High-speed control and navigation for quadrupedal robots on complex and discrete terrain
来源:Science Robotics 25
2026/5/11
-
总结:这篇文章提出了一个面向复杂离散地形的高速四足机器人分层导航系统:用竞争式生成 curriculum 训练出能精确踩点的 RL tracker,再用采样 + 启发式/神经过滤 + 物理仿真 rollout 的 planner 实时生成动态可行落脚点计划,最终让 Raibo 在真实环境中完成跳远、跑墙、踏石高速奔跑和复杂地形导航。上层 planner 负责快速找可行落脚点序列,下层 tracker 负责精确踩到这些落脚点。
-
讲的故事 / 难点是:
- 落脚点规划本身是非凸问题,地形可能由台阶、碎石、间隙、斜坡、柱子组成,不能像平地导航那样只规划一条连续轨迹。
- 高速运动时机器人无法瞬间改变方向,所以仅用几何可达性判断落脚点是不够的,必须考虑动态可行性。
- 高速踩点对控制器要求极高,脚落点稍微偏一点,后续步态就可能彻底失效。
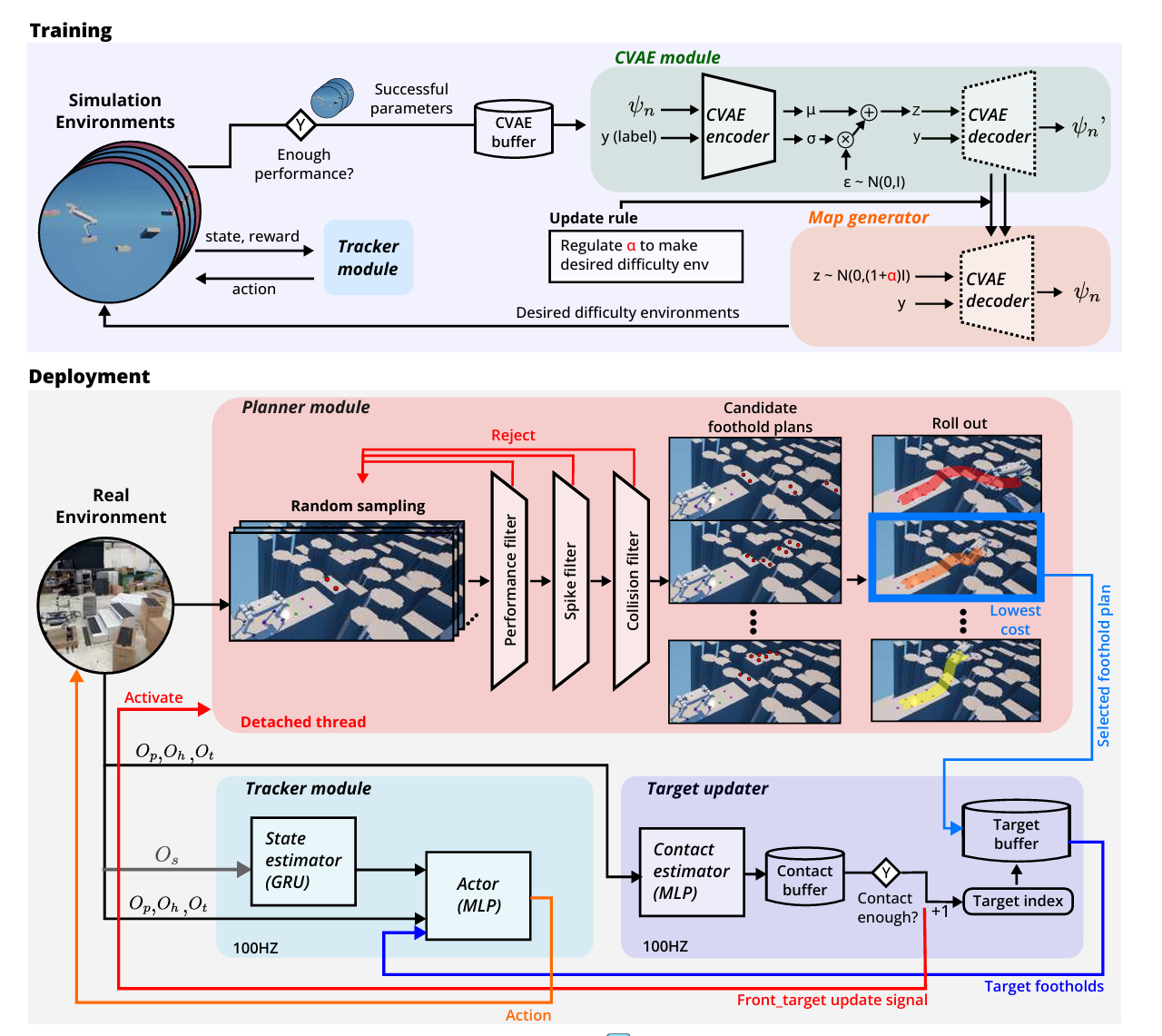
- 下层tracker的作用是给定一串目标落脚点后,尽量准确地把脚踩到这些点上。
- 由 state estimator 和 actor 两部分组成,其中state estimator 是 GRU + MLP,用来估计机器人线速度,actor 是 MLP。
- 通过PPO训练。
- 在 Raisim (这个组自己的仿真环境,机器狗也是他们自己的硬件)中仿真,每个环境由连续 10 个 stepping stones 组成,tracker 的任务是按目标索引依次踩到目标落脚点。
- 训练地形的生成是通过一个 map generator 生成的,这个 map generator 基于 CVAE,和 tracker 进行竞争式训练。初期先用固定范围逐步扩大的 curriculum 让 tracker 和生成器稳定起来;之后当 tracker 已经能通过足够多的 stepping stones 后,收集 tracker 成功通过的地形参数,用这些成功样本重新训练 CVAE,然后通过调节 latent sampling 的尺度来生成"刚好有挑战性"的新地形。
- Reward 包括三类,target-related(落点和目标之间的约束 / 奖励)、constraint-related(限制关节不要超限)、style-related(减少 torque、减少打滑等)。
- 输入包括机器人本体状态、历史观测、未来落脚点目标、时间信息,以及由 state estimator 估计出的机体线速度,输出是 12 维关节目标,也就是每个关节的位置 target。
- 这里,tracker 不只看下一个落脚点,而是看未来两个目标,因为高速运动需要考虑加速和减速,机器人在当前 stepping stone 上的动作已经受到后面两个目标的影响。
- 上层planner的作用是根据地形 height map、当前机器人状态和目标点,采样可能的落脚点序列,然后经过一系列快速过滤器去掉明显不可行的方案,最后把少量候选方案放进物理仿真里 rollout,用真实 tracker 和 Raibo 模型模拟执行,选成本最低的落脚点计划。本质是先用便宜的规则/网络过滤器做粗筛,再用昂贵但准确的物理仿真做精筛。
- 这里的落脚点序列是随机采样得到的,为了减少采样空间,作者提出了两个假设,第一,前脚左右目标同步更新,后脚左右目标同步更新;第二,后脚踩到对应前脚之前踩过的位置。
- 采样之后,使用三种 filter 来快速过滤不满足的采样结果:
- performance filter:它检查候选 foothold 及其周围区域是否落在 tracker 训练过的能力范围内;
- spike filter:检查候选区域周围高度是否变化太剧烈,用 PCA 估计坡面并评估与线性模型的偏差,从而避免选择过于尖锐、粗糙、曲率过大的落脚区域;
- collision filter:用一个 boundary estimator network (MLP)预测机器人沿当前目标到下一目标运动时,碰撞体扫过区域的最低边界,然后与地形高度比较,提前判断是否可能发生不希望的碰撞。
- 过滤之后,planner 会形成 8 个候选 foothold plans,每个 plan 长度是 4 个 foothold pair。然后在物理引擎里并行 rollout,每个候选都用训练好的 tracker 和完整 Raibo 模型执行一遍,最后根据成本函数选择最优 plan。
- 成本函数包括survive cost、distance cost、direction cost、elevation cost。
- 存在的问题:
- 不是实时感知并闭环控制。作者没有用 onboard perception,而是预先获取 height map,并用 Vicon motion capture 获取机器人位姿。(解释的原因是高速运动带来高加速度,状态估计漂移会严重影响控制,此外很多期望落脚点可能被遮挡或超出相机视野)
- planner 只工作在 2.5D height map 上。虽然 tracker 能做 wall running,planner 本身还不能为垂直墙面生成落脚计划(后续需要 3D voxel map 等 3D 地图表示,才能让 planner 支持墙面落脚规划)。
- 完全基于他们自己的生态(Raibo机器狗 + Raisim仿真环境),直接迁移难度应该很大。