CLEARER: Multi-Scale Neural Architecture Search for Image Restoration
2021/12/12
来源:NIPS20
resource:github上备份的包括ipad标注的pdf版本。
作者是川大/学而思的Yuanbiao Gou, Boyun Li, Zitao Liu, Songfan Yang, Xi Peng等人。
Summary:一篇很一般的文章,倒不如说非常符合预期(指没有水平的A+B)。但是,这篇文章的出发点还是有趣的,即从多尺度的角度讲LLCV+NAS的A+B的故事,听起来还合理。文章主要做的可微分NAS for LLCV,主要贡献在搜索空间的设计(此外还有自吹的Loss func设计+可微搜索,但是在这糊弄谁呢),不是根据一些op搜两种cell,而是设计搜索的module,拼成cell再进一步拼成superent,即module -> cell -> supernet,但是我估计NAS里肯定早就有人这么做了。
Key words:
- NAS
Rating: 2.0/5.0 比较差,没什么东西,游戏文字。
Comprehension: 4.0/5.0 除了一些细节,基本上比较容易懂。
两张图总结全文:
-
搜索空间设计
-
软化离散决策
1. Introduction
一些常识回顾:
- 基于学习的方法将显式且手工设计的图像先验替换成隐式且学习的先验,这些先验由网络架构捕捉;
these so-called learning-based methods substitute the explicit and andcrafted image priors
with implicit and learning-based priors which are captured by neural architectures
- 低分辨率网络可以捕捉图像的全局结构特征,但是会丢失感官细节;高分辨率网络可以保存图像的局部细节,但是对噪声更敏感;
The success of multi-scale methods are attributed to different roles of low- and high-resolution
networks. In brief, the low-resolution networks could capture the global structure of the given image,
while losing the perception of details. In contrast, the high-resolution networks could preserve the
local details of images, while being with less semantics and robustness to noise
- 本文涉及的指代令人迷惑,甚至和现在的认识冲突,
Low Resolution -> Low Scale -> small pic - 一种有趣的认识:多尺度信息分显式和隐式(跳连)
- 提出了一种激进的观点:cell-based NAS可以减少时间和空间消耗,但是会导致更差的结果:
As pointed out in [2], although cell-based NAS could remarkably reduce the time and space cost,
it will achieve inferior performance.
3. Multi-scale NAS for Image Restoration
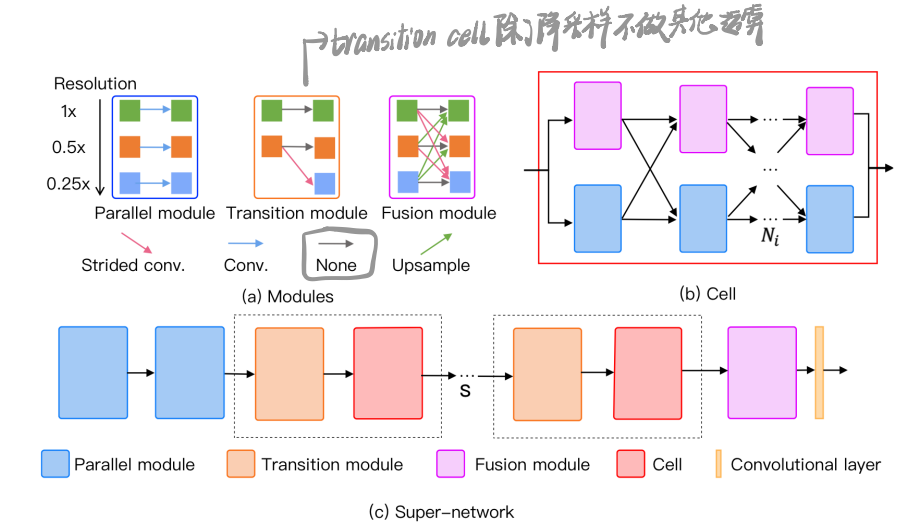
CLEARER最大的贡献就是设计了一种"多尺度搜索空间",其实也就那样。
具体的成分有三种,见最上图:Parallel module,Transition module和Fusion module。其中Transition module固定在每个cell之前,所以搜索成分只有两个,parallel module和fusion module。
3.1 Differentiable Multi-Scale Search Space
整个supernet有S个cell,每个cell $N_i$个column,这个column可以填成pm或者fm,所以整个搜索空间规模非常小,以S=3,N=4记,仅$2^{12}$。
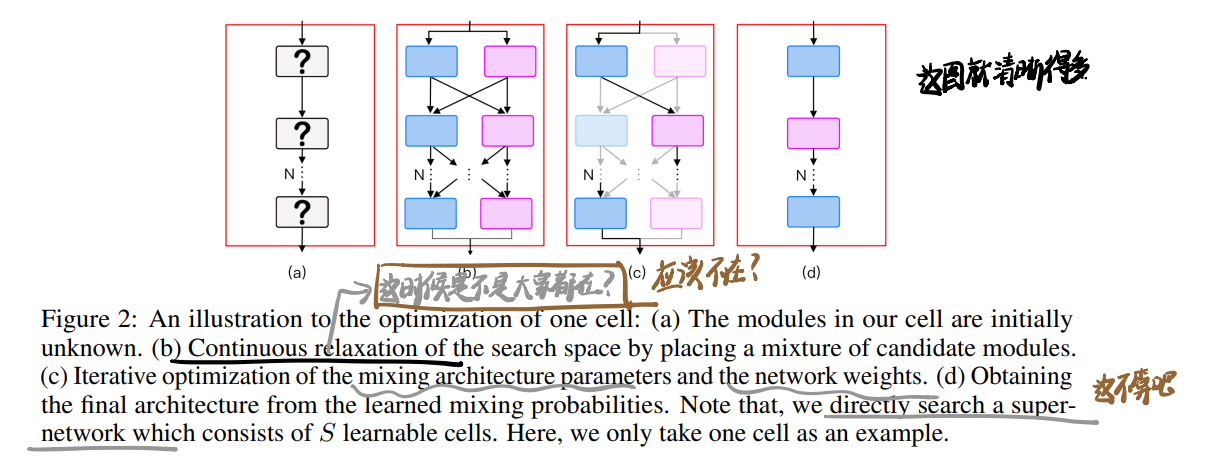
搜索的范式和DARTS一样,但是我忘了DARTS搜索中是不是软性加权了,这里应该是,单列决策为:

二值限制有以下限制,我理解是通过这个限制软化了离散决策,所以在搜索时两个candidate应该都会参与运算:
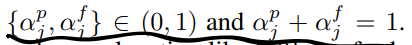
搜索示意见第二张图。
3.2 Loss Function
Loss Function有点过于简单了:
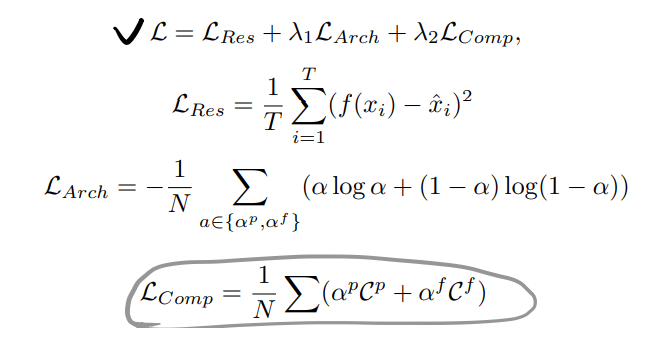
三部分,第一部分是MSE重建误差,第二部分把架构参数推到0/1,第三部分是加权惩罚。
优化时采用双层优化策略,用整体Loss L优化架构参数,用$L_{Res}$优化网络参数,数据采用独立分隔的数据。
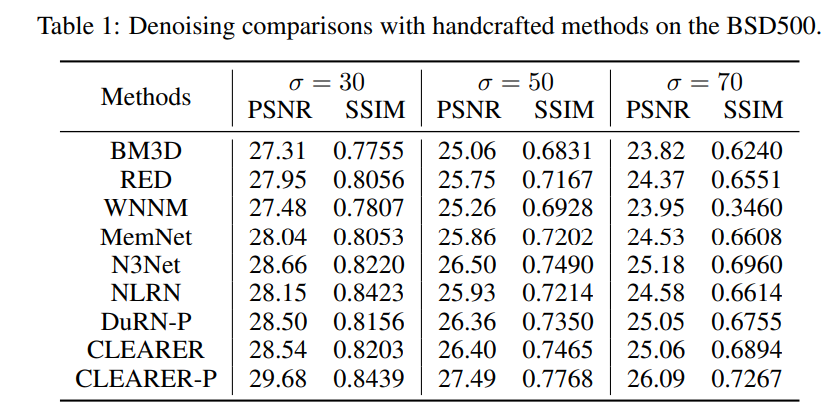
4 Experiments
训练架构参数和网络参数时采用两种优化器,有点新奇。
在BSD上比了去噪能力,不是很认可: