Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising
2021/9/8
来源:TIP17
resource:github上备份的包括ipad标注的pdf版本。
作者是HIT的Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang等人,做的工作非常solid(虽然挺简单的,就DnCNN而言),但是有很多很有影响力的文章,比如TIP18上的FFDNet。
Summary:非常经典的基于深度学习的图像去噪文章,虽然思路很简单,但是结果非常可观、文章很扎实,不愧是去噪领域的经典!思路非常简单,就是用了Residual Learning,应该是以前对Residual learning的理解不深入,这里就是学真实图像和去噪图像的差值(也就是学习逐渐剔除纯净图像,学出来噪声),而不是我之前以为的简单的"跳跃连接=残差学习"。简单的模型性能很好,比之前一众baseline效果都好,且versatile,既可以做高斯噪声去噪、盲高斯噪声去噪、也能做SISR、demosaicking(需要同时喂入这些类型的数据)。做了一些比较合理的分析,比如BN和residual learning相互促进。
Key words: Residual Learning
Rating: 4.3/5.0
Comprehension: 4.6/5.0
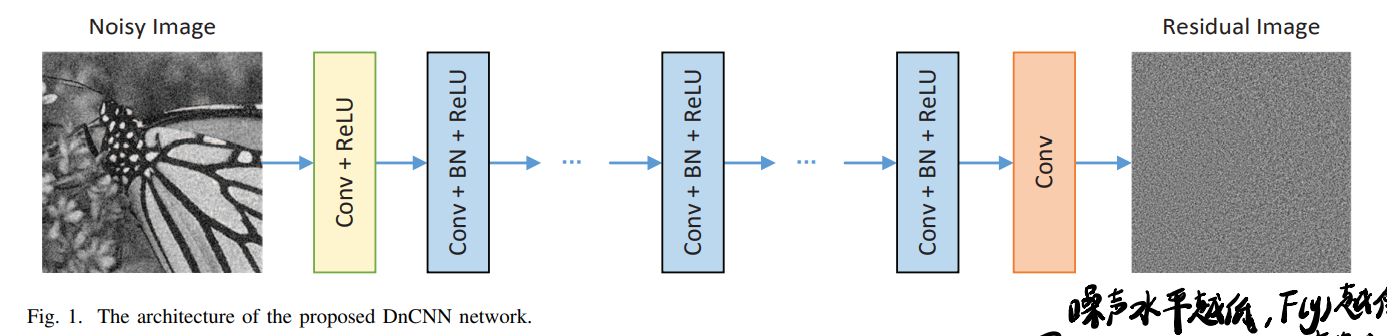
一张图总结模型结构:
1 Introduction
- 从贝叶斯的观点,当似然函数已知,图像的先验就在图像去噪中起到非常重要的作用。建模图像先验的方法有nonlocal self-similarity (NSS) models, sparse models, gradient models, Markov random field (MRF) models. NSS里的sota方案包括BM3D, LSSC, NCSR和WNNM。
- 有一段专门讲学习图像先验的文字,都是传统方法,不关心
- 与其学直接输出去噪的图像x_hat,这里学预测图像的残差,就是去噪图像和纯净图像的差距
- 作者总结的全文贡献:
- 用CNN做去噪,使用残差学习策略从含噪观测中去掉纯净图像,留下来噪声;
- residual + BN,相得益彰;
- 结果不错,还versatile。
2 Related Work
介绍过MLP/TNRD等非常早期的DL方法,survey的时候或许能用到。
- 预测图像残差的思路在之前很多Low level vision任务里已经用过了。
3 The Proposed Denoising CNN Model
3.A Network Depth
- 网络结构里去掉了池化层;
- 去噪网络的感受域的大小和去噪的有效patch大小相关 + 更高水平的噪声需要更大的patch size以获取更多纹理信息 -> 根据patch size确定深度(感觉似乎有道理,又没有道理) -> 17 or 20
3.B Network Architecture
-
Residual Loss:
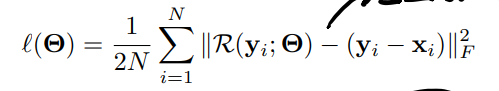
-
卷积层通道都是64,zero padding保证size一致(保证没有boundary artifacts)。
3.C Integration of Residual Learning and Batch Normalization for Image Denoising
- 解释了一波为什么学残差,噪声水平越低,正变换F(y)就越像identity,越难学,所以要学残差R(y)
- BN对residual有好处:残差也就是噪声本来就符合高斯分布(高斯噪声),所以加一个BN有好处还挺好理解的
- Residual对BN也有好处,加了BN后每层的输入都接近高斯分布,更少互相关,与图像内容更少相关
3.D Connection with TNRD
对TNRD不熟,看不懂分析,大体是说TNRD在指定惩罚函数和变换函数就相当于2层Conv,在这种语义下DnCNN就是对TNRD的拓展。
3.E Extension to General Image Denoising
可以从确定噪声水平的高斯去噪拓展到高斯盲去噪、SISR、JPEG deblocking,由一个训练出来的模型去执行三个任务,但是训练数据必须是掺杂的(不能transfer among tasks)
4 Experiments Results
关心的角度有:
- Experimental setting:非常详细,复现的时候可以试试
- 比较的方法里放出了自己的代码,非常贴心
- 定性分析
- 里面说了一个相比BM3D的upper bound?有点不解。
- 在House和Barbara情况下结果不如BM3D,分析说non-local means的方法对有regular与repetitive结构的图像表现较好,而判别训练类的方法则对irregular texture更好。
- 运行时间,后面好像就很少强调这一点了?
- versatility