深度神经网络压缩与加速综述
2021/5/12
来源:计算机研究与发展(JCRD)
resource:github上备份的包括ipad标注的pdf版本。
作者是厦大纪荣嵘组,好强啊,业界大佬执笔的综述(虽然读起来感觉没那么大的收获233)。
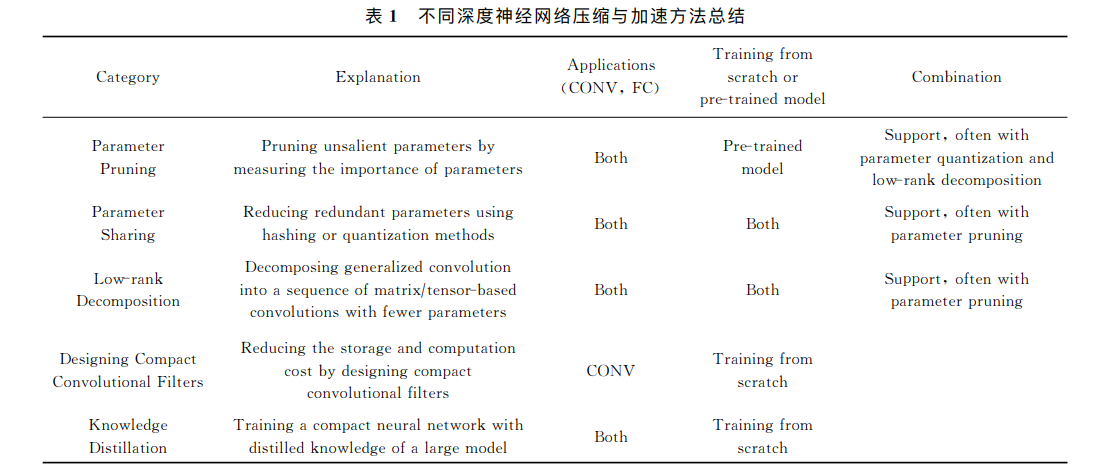
Summary:综述了18年以来的模型压缩的方法,当然直到最近(根据我目前的阅读情况来看)也没有其他的更新就是了:1)参数剪枝(parameter pruning), 2)参数共享(parameter sharing), 3)低秩分解(low-rank decomposition), 4)紧性卷积核的设计(designing compact convolutional filters), 5)知识蒸馏(knowledge distillation)。参数剪枝主要通过设计判断参数重要与否的准则,移除冗余的参数;参数共享主要探索模型参数的冗余性,利⽤Hash或量化等技术对权值进⾏压缩;低秩分解利⽤矩阵或张量分解技术估计并分解深度模型中的原始卷积核;紧性卷积核的设计主要通过设计特殊的结构化卷积核或紧性卷积计算单元,减少模型的存储与计算复杂度;知识蒸馏主要利用⼤型网络的知识,并将其知识迁移到紧性蒸馏的模型中。
Rating: 3.0/5.0
Comprehension: 4.0/5.0
文章的贡献有:
- 帮我厘清了这些模型压缩方法,阿里嘎多(?)
摘要
这张表不知道现在还准不准了,当然我倾向于有点问题(主要表现在pretrain和combination)…
1 深度神经网络相关概念与回顾
无用。
2 深度神经网络压缩与加速算法
这节的定义可以好好看看。
2.1 基于参数剪枝的深度神经网络压缩与加速
网络/参数剪枝是通过对已有的训练好的深度网络模型移除冗余的、信息量少的权值,从而减少网络模型的参数,进而加速模型的计算和压缩模型的存储空间。不仅如此,通过剪枝网络,能防止模型过拟合。以是否⼀次性删除整个节点或滤波为依据,参数剪枝工作可细分成非结构化剪枝和结构化剪枝。非结构化剪枝考虑每个滤波的每个元素,删除滤波中元素为0的参数,而结构化剪枝直接考虑删除整个滤波结构化信息。
参数剪枝的缺点在于,简单利⽤非结构化剪枝,无法加速稀疏化矩阵计算。虽然近年来,相关软件与硬件已被利用进行加速计算,但依靠软硬件的非结构化剪枝方案还无法在所有深度学习框架下使用,另外硬件的依赖性会使得模型的使用成本提高。结构化剪枝不依赖软硬件的⽀持,且能很好地嵌⼊目前主流的深度学习框架,但逐层固定的剪枝⽅式导致了网络压缩的低⾃适应能⼒、效率和效果。此外,上述的剪枝策略需要⼿动判断每层的敏感性,因此需要⼤量的精⼒分析及逐层微调。
2.2 基于参数共享的深度神经网络压缩与加速
参数共享是通过设计⼀种映射将多个参数共享同⼀个数据。近年来,量化作为参数共享的最直接表现形式,得到⼴泛的应⽤。此外,Hash函数和结构化线性映射也可作为参数共享的表现形式。
量化权值,特别是⼆值化网络,存在以下缺点:1)对于压缩与加速大的深度网络模型存在分类精度丢失严重现象(现有⽅法只是采⽤简单地考虑矩阵近似,忽略了⼆值化机制对于整个网络训练与精度损失的影响。2)对于训练大型⼆值网络,缺乏收敛性的理论验证,特别是对于同时量化权值和激活的⼆值化网络。3)对于限制于全连接层的参数共享方法,如何泛化到卷积层成为⼀个难题。此外,结构化矩阵限制可能引起模型偏差,造成精度的丢失。
2.3 基于低秩分解的深度神经网络压缩与加速
基于低秩分解的深度神经网络压缩与加速的核心思想是利⽤矩阵或张量分解技术估计并分解深度模型中的原始卷积核。卷积计算是整个卷积神经网络中计算复杂度最高的计算操作,通过分解4D卷积核张量,可以有效地减少模型内部的冗余性。此外对于2D的全连接层矩阵参数,同样可以利用低秩分解技术进行处理。
基于低秩分解的深度网络模型压缩算法,在特定场景下取得良好的效果,但增加了模型原有的层数,极易在训练过程中造成梯度消失的问题,从⽽影响压缩后网络的精度恢复。另外,逐层低秩分解优化参数,⽆法从全局进⾏压缩,延长了离线分解时间开销。
2.4 基于紧性卷积核的深度神经网络压缩与加速
对深度网络模型的卷积核使用紧性的滤波直接替代,将有效地压缩深度网络。基于该思想,直接将原始较大的滤波大小(如5×5, 3×3)分解成2个1×1卷积滤波,大大加速了网络的计算同时获得了较高的目标识别性能。
基于紧性卷积核的深度神经网络压缩与加速采用了特定的卷积核的设计或新卷积计算方式,大大压缩神经网络模型或加速了卷积计算。但压缩与加速方法的扩展性和结合性较弱,即较难在紧性卷积核的深度神经网络中利用不同压缩或加速技术进⼀步提高模型使⽤效率。另外,跟原始模型相比,基于紧性卷积核设计的深度神经网络得到的特征普适性及泛化性较弱。
2.5 基于知识蒸馏的深度神经网络压缩与加速
知识蒸馏的基本思想是通过软Softmax变换学习教师输出的类别分布,并将大型教师模型的知识精炼为较小的模型。
虽然基于知识蒸馏的深度神经网络压缩与加速⽅法能使深层模型细小化,同时大大减少了计算开销,但是依然存在2个缺点:1)只能用于具有Softmax损失函数分类任务,这阻碍了其应用。2)模型的假设较为严格,以至于其性能可能比不上其他压缩与加速方法。
2.6 其他类型的深度神经网络压缩与加速
此外,基于卷积的快速傅里叶变化和使用Winograd算法的快速卷积计算,大大减少了卷积计算的开销。Zhai等人提出了随机空间采样池化,用于加速原始网络中的池化操作。但是这些⼯作仅仅为了加速深度网络计算,无法达到压缩网络的目的。
3 数据集与已有方法性能
无用。
4 讨论:压缩与加速方法选择
有一点用。
1)对于在线计算内存存储有限的应用场景或设备,可以选择参数共享和参数剪枝⽅法,特别是⼆值量化权值和激活、结构化剪枝。其他方法虽然能够有效的压缩模型中的权值参数,但⽆法减小计算中隐藏的内存大小(如特征图)。
2)如果在应⽤中用到的紧性模型需要利用预训练模型,那么参数剪枝、参数共享以及低秩分解将成为首要考虑的⽅法。相反地,若不需要借助预训练模型,则可以考虑紧性滤波设计及知识蒸馏方法。
3)若需要⼀次性端对端训练得到压缩与加速后模型,可以利用基于紧性滤波设计的深度神经网络压缩与加速方法。
4)⼀般情况下,参数剪枝,特别是非结构化剪枝,能大大压缩模型大小,且不容易丢失分类精度。对于需要稳定的模型分类的应⽤,非结构化剪枝成为首要选择。
5)若采⽤的数据集较小时,可以考虑知识蒸馏方法。对于小样本的数据集,学⽣网络能够很好地迁移教师模型的知识,提高学⽣网络的判别性。
6)主流的5个深度神经网络压缩与加速算法相互之间是正交的,可以结合不同技术进⾏进⼀步的压缩与加速,如韩松等人结合了参数剪枝和参数共享;温伟等人以及Alvarez等人结合了参数剪枝和低秩分解。此外对于特定的应⽤场景,如目标检测,可以对卷积层和全连接层使⽤不同的压缩与加速技术分别处理。