Toward Convolutional Blind Denoising of Real Photographs
2021/9/13
来源:CVPR19
resource:github上备份的包括ipad标注的pdf版本。
作者是HIT的Shi Guo, Zifei Yan, Kai Zhang, Wangmeng Zuo, Lei Zhang等人,又是张凯他们,难不成HIT有个做LLCV很强的组?
Summary:一篇还可以的图像去噪文章,应该是新的baseline了和DnCNN、FFDNet一起挨打,主要在喷现在的CNN用来去噪AWGN图像还行,但是对AWGN过拟合,以至于在真实图像上的表现很差,所以提出了主要面向真实图片噪声去噪的CBDNet,具体的"创新点"有:
- 用heteroscedastic Gaussian + ISP建模噪声,并用这个噪声模型合成训练图像;
- 提出了一种2-subnet的结构,一个子网络用于预测noise level map,并且可以手工调节这个map以产生"交互效果",另一个子网络用噪声图和含噪图片作为输入,去图像去噪;
- 基于subnet,提出了一种混合loss,其中一个非对称loss用来惩罚噪声水平预测低的情况,还比较有新意
- 混用真实噪声图像和合成噪声图像(这种数据增强方法感觉没啥用,但是后面RIDNet将其视为一种图像增强方法,不知道是不是故意这么说…还是感觉没用啊)作为训练数据,起到扩充训练数据的作用。
Key words:
- 辅助信息(可学习的噪声地图)
- 2-stage network(标准的噪声预测-噪声去除真实图像盲去噪流程)
- 数据增强(混用真实图像和合成图像)/训练方案
- Loss改进(三个term,其中有意思的asymmetric loss)
- 结构(U-Net, residual-learning)
Rating: 4.0/5.0
Comprehension: 4.5/5.0
一张图总结模型结构:
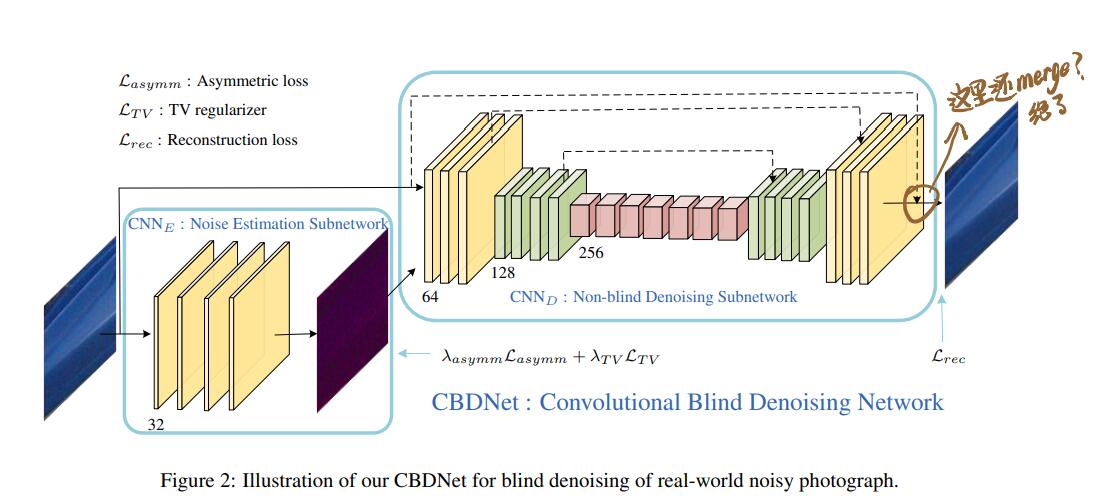
1 Introduction
- 观点:传统方法已经可以很好地去除AWGN了,而真实噪声盲去噪还没有很好地解决
- 真实噪声来源(应该是第二次总结了):
- dark current noise, short noise, thermal noise, etc.
- 来自ISP(demosaicing, Gamma correction, compression, etc.)
- AWGN盲去噪的去噪器用于真实噪声去噪会产生很大的性能下降,AWGN非盲去噪的去噪器则会在去除噪声的时候抹去图像细节(第二次反直觉了,非盲去噪按说在噪声等级这一维度上的泛化性不行(但是反之专一性很强),但是在跨任务(AWGN/real)上的泛化性能还行)
- 文章出发点:现在的CNN去噪器因为会过拟合高斯噪声,所以泛化到真实图片上的性能不佳。以及CNN的成功主要是可以记住输入,所以合成噪声与真实噪声的分布是否一致非常重要(合理)。
2 Related Work
2.2 Image Noise Modeling
可能有用,但不太懂 - 噪声建模。
- 大多数去噪方法是针对非盲高斯去噪的。
2.3 Blind Denoising of Real Images
- 真实噪声的去除可以分为两个阶段:噪声估计和非盲去噪。
剩下的部分主要是传统的真实图像盲去噪,不太关心。
3. Proposed Method
3.1. Realistic Noise Model
他们用的噪声模型,比较细节,实际上不太关心。
- photon sensing可以被建模成Poisson,remaining stationary disturbances可以被建模成Gaussian,两个合在一起,Poisson-Gaussian就成了imaging sensor raw data的噪声模型,这个模型进一步可以由heteroscedastic Gaussian(异方差高斯分布)近似:
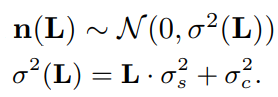
式中的L是raw pixels的irradiance image,\(\mathbf{n}(\mathbf{L})=\mathbf{n}_s(\mathbf{L})+\mathbf{n}_c\)由两部分组成,第二项是stationary noise component,方差是\sigma_c^2,第二项是signal-dependent noise component,它的方差空间可变,就是L*\sigma_s^2。
经过ISP处理的噪声更加复杂,spatially and chromatically correlated。用两个步骤来描述,demosaicing/Gamma correction:
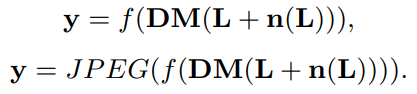
y表示合成的图片,f(·)表示从201 CRFs里均匀采样的camera response function (CRF),\(\mathbf{L}=\mathbf{M}f^{-1}(\mathbf{x})\)表示从纯净图像x中生成irradiance image,M(·)表示把sRGB图像转换成Bayer image,DM(·)表示demosaicing函数(也就是通过这一步引入了像素之间的通道/空间依赖性)。
如果考虑JPEG压缩(Nam数据集),就像上式一样在外面套一个JPEG函数。
量化噪声忽略不计。
3.2. Network Architecture
- 由两部分组成,噪声估计子网络CNN_E和非盲去噪子网络CNN_D。后者将含噪图片与前者输出的noise map作为输入,输出去噪图像;noise map可以手工调整。
- 一些层间设置,不太关心。
- residual learning
- BN不太好使,因为真实噪声分布和高斯噪声分布相差很多。
3.3. Asymmetric Loss and Model Objective
- 总体loss:
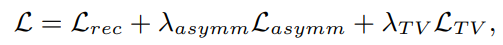
- 分成三部分:
-
asymmetric loss,主要惩罚预测结果低于真实噪声的情况,\alpha=0.3:
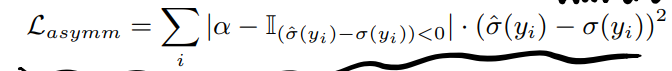
-
total vairation regularizer,用来平滑噪声map的预测结果,两个算子分别表示gradient operator along the horizontal (vertical) direction:
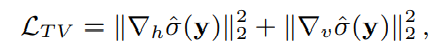
-
经典重建Loss,但是是L2 loss:
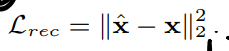
-
perceptual loss
-
3.4 Training with Synthetic and Real Noisy Images
有点数据集扩充的意思嗷。
- real-noisy image pair收集起来很贵,而且over-smoothing,与合成数据结合起来可以增强泛化能力(真的吗,我不信)
- 用到的数据集:
- BSD500
- Waterloo
- MIT-Adobe FiveK
- RENOIR(真实数据,前面仨都是合成用的)
- 合成batch和真实batch交替喂入,真实数据因为没有noise map,loss里也就没有asymmetric一项。
- 测试集:
- NC12
- DND
- Nam
4 Experimental Results
-
典中典之"巨大的提升":
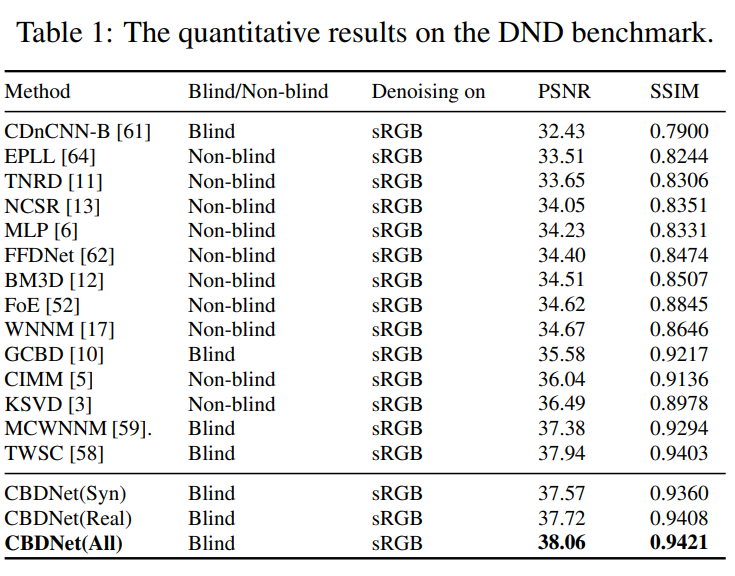
-
关心的实验:
- 和sota比较
- ablation
- 提到ISP对真实噪声建模更重要