Transfer Learning from Synthetic to Real-Noise Denoising with Adaptive Instance Normalization
2021/9/20
来源:CVPR20
resource:github上备份的包括ipad标注的pdf版本。
作者是Seoul National University(韩国sky之首哎)的Yoonsik Kim, Jae Woong Soh, Gu Yong Park, Nam Ik Cho等人,第一次见到他们的文章,搜了下还有个ICIP?实在是来者不拒(褒义意味)。
Summary:一篇还不错的文章,主要涉及module design和一种新的训练方案,在SN数据集上预训练再在RN数据集上部分调整网络参数(可以看成一种staged training,但是读下来感觉还是为了解决样本不足的问题),这种方法在SN上预训练学习domain-invariant信息后只需要补充较少一部分RN数据就能实现校正,不用重新训练整个网络(但是据实验结果来看,整个重新训练效果更好)。其次,他们设计的module是施加了一种Regularization(防止网络对训练集数据过拟合),也可以看成Feature Attention(逐pixel进行scale和shift),用文章的话总结贡献,就是:
- 设计了一种模块AIN;
- 提出了一种transfer learning scheme,从SN数据中学出domain-invariant信息,再在RN数据上更新AIN中仿射变换的参数。
Key words:
- Module Design / Feature Attention / Regularization
- Training Scheme
Rating: 4.0/5.0 还不错,该有的都有,中规中矩,不过开了一条新路,还挺喜欢。
Comprehension: 4.5/5.0 基本上挺好懂,少0.5分谦虚一下。
需要三张图总结全文:
-
模型总体架构
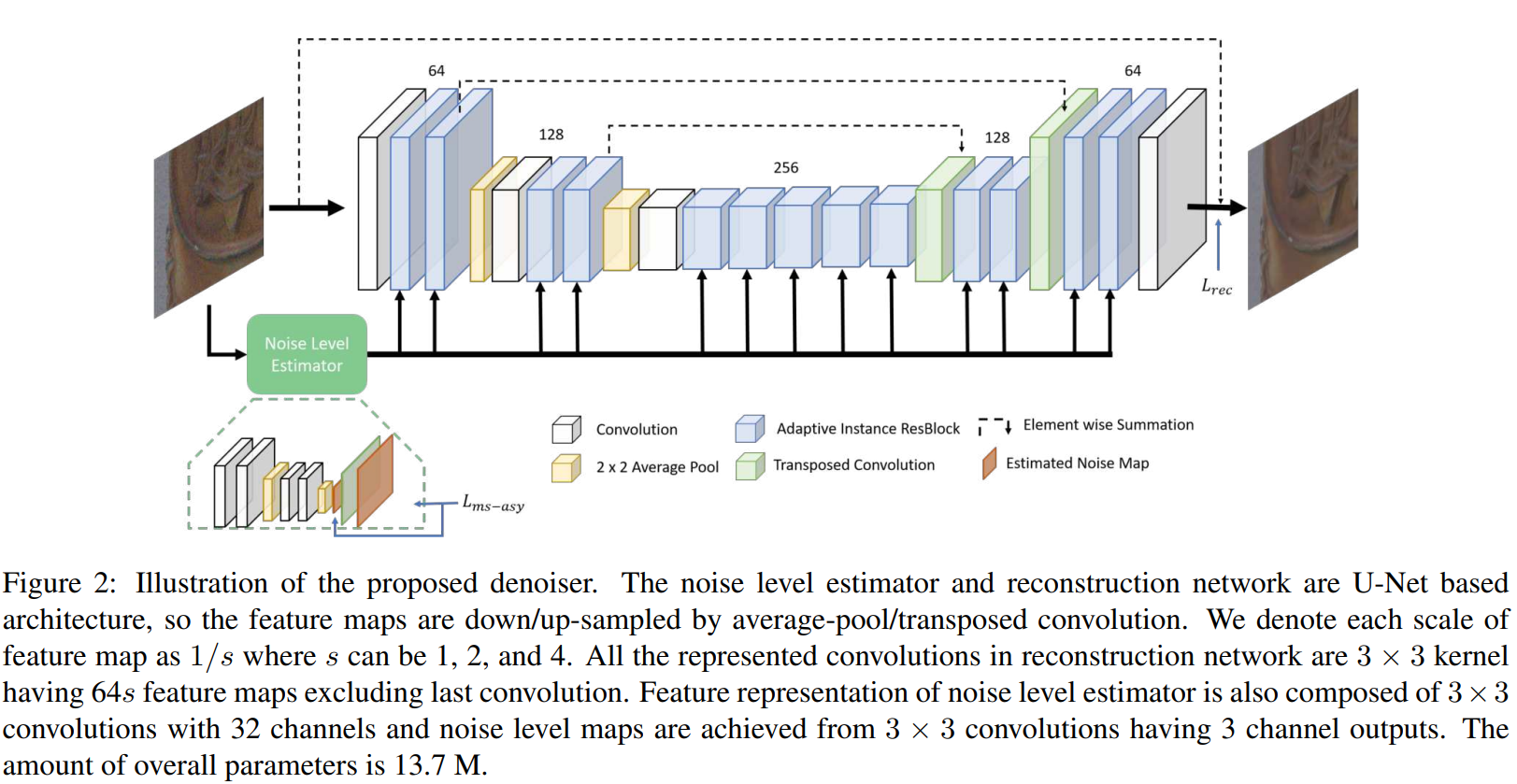
-
AIN模块
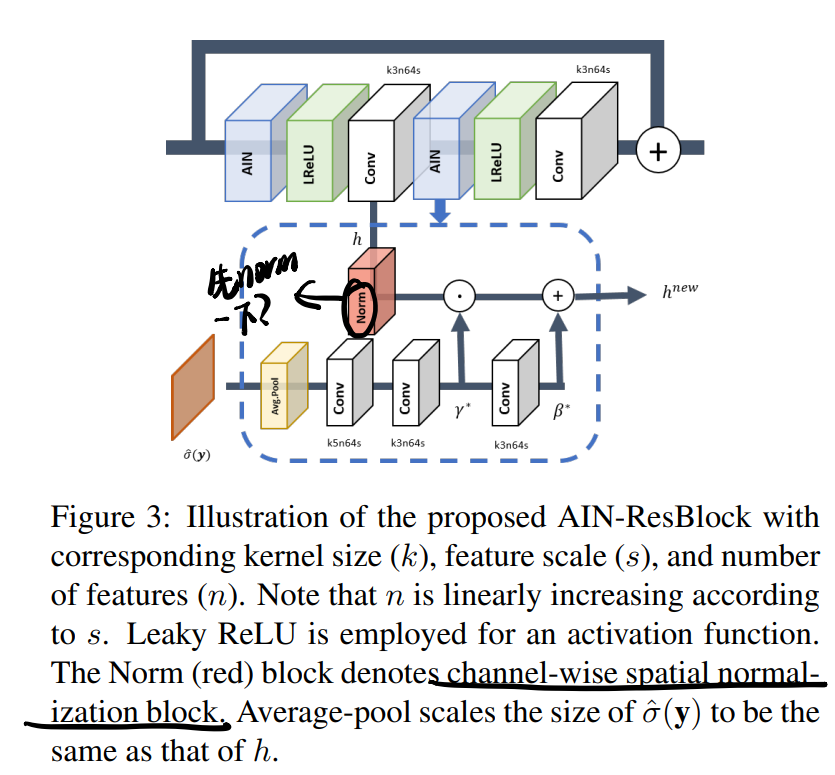
-
Transfer Learning Scheme
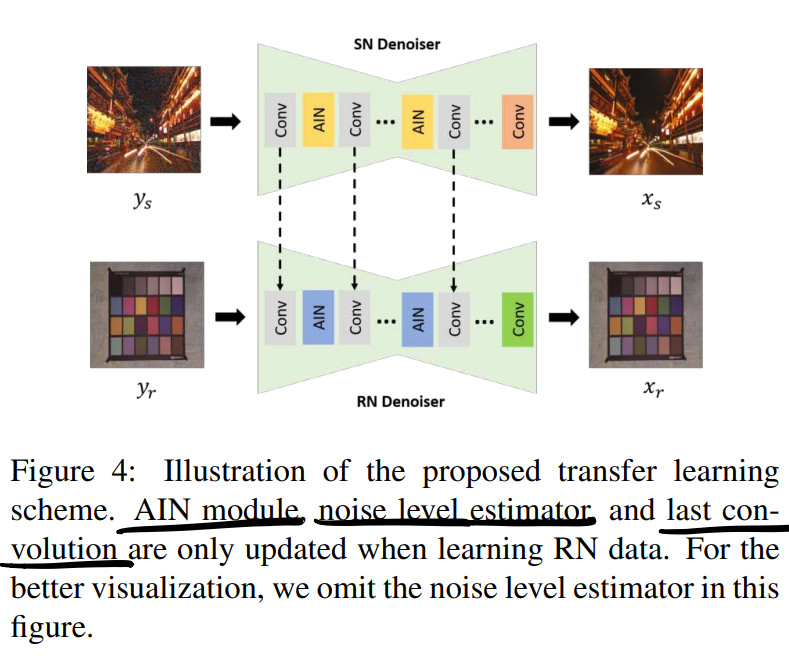
1. Introduction
- 泛化性体现在两个方面:
- 从合成数据到真实数据
- 从小数据集到大数据集
- 认为CNN在真实数据上的泛化性差是因为合成数据和真实数据的分布不一致,CNN过拟合
- 解决真实数据和合成数据分布不同的两(四)种思路:
- 使用真实含噪-纯净图像pair作为训练/测试数据
- 优点是CNN可以鲁棒地工作(训练测试数据之间没有gap)
- 缺点是1.获取数据需要专家知识、数量不足、容易对某种特殊的摄像设备与ISP过拟合
- 找到合适的噪声模型(从而人工合成数据用于训练)
- 典型的噪声模型有Gaussian-Poisson, heteroscedastic Gaussian, Gaussian Mixture Model (GMM), deep leaning based methods
- 本文的Transfer Learning和CBDNet应该类似,混用合成数据/真实数据
- 但是CBDNet其实更像第二条,就是用合成数据和真实数据拟合分布?而且CBDNet在SN和RN之间还是有个discrepancy,而且可能过拟合到实际上并不是真实数据的分布
- 最近流行的无监督学习
- 使用真实含噪-纯净图像pair作为训练/测试数据
- Regularization方法在denoise中探索得也不是很多,主要是因为在训练-测试数据分布一致的情况下表现不好
- CBDNet的SN/RN batch交叉的方式既可以看成一种数据增强,也可看成一种训练方案,但是可能会有训练不稳定的情况,毕竟数据分布不同。
3. Proposed
- 使用CBDNet中的噪声模型生成训练数据(异方差高斯+ISP)
3.1. Adaptive Instance Normalization Denoising Network
- SN和RN对应模型一样
- AINDNet包括噪声等级估计器和重建网络两部分,总体结构符合U-Net架构,里面的计算块替换成AIN Residual block(虽然文中没说,但是应该学的是残差,不然不用把图加到最后)见第一幅图
- 噪声等级估计器相比CBDNet升级了down/up sample以获得更大的感受野,且输出是由两个尺度的结果构成的(就是中间引出来了一个feature map,线性插值up scale,再和最后的输出加权求和,实在看不懂这么怪有什么用,见第二张图),拼接loss如下:
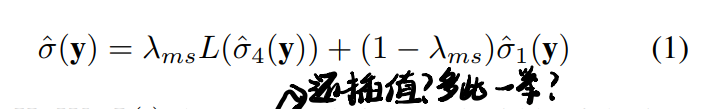
- AIN module:还是见第二张图,一个AIN-ResBlcok由两个Conv层和两个AIN modules组成,在处理之前会有一个channel-wise normalization(减均值除方差,很怪)
- AIN module的作用是1. regularize模型,防止过拟合到SN 2. 从SN转换到RN(主要是参数替换)
- AIN对特特征图的处理是一种pixel-wise线性变换,可以理解成一种feature attention,也因此可以处理spatially variant noisy images:

3.2. Transfer Learning
读下来的感觉还是为了解决样本不足的问题。
- 分工(会有这么好的事吗):SN学习general and invariant feature representations,RN学习noise characteristics that can not be fully modeled from SN data.
- 受到其他迁移学习的启发(换BN参数就能迁移到其他领域分类,感觉有些神奇),这里主要是调整normalization(AIN)的参数。
- 实际上更新的部分包括AIN中仿射变换的参数、噪声水平估计器、最后一层Conv,据称transfer learning的好处有:
- converged with faster speed
- RN样本一样少时性能比从头训练的网络好
- 可以和multi-model结合,避免对不同噪声水平重复训练模型
- 训练Loss
- 在训SN时需要combine下面两个:
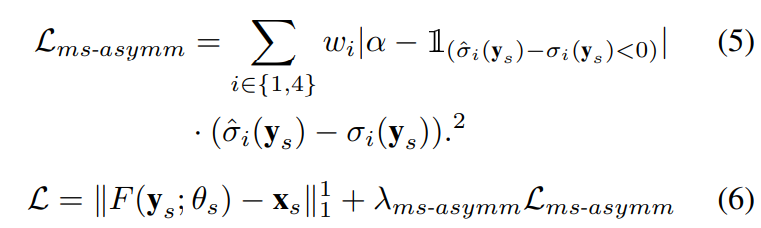
- 再finetune RN时只需要:
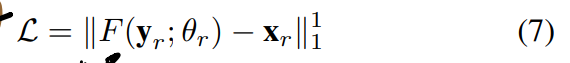
- 在训SN时需要combine下面两个:
- AINDNet + RT的训练方法暴露出了另一种常见的训练/转移方式,即直接以SN为初始化重训,而不是更改部分参数。
4. Experiments
训练的数据集包括:
- Gaussian denoiser
- DIV2K
- BSD400
- RN denoiser
- Waterloo
- SIDD
测试的数据集包括:
- Gaussian denoiser
- Set12
- BSD68
- RN denoiser
- RNI15
- DND
- SIDD
AINDNet甚至并不是当时的SOTA,但是他们argue自己模型尺寸要小很多。
实验结果还挺real的,可以看看分析。
少样本的情况下用transfer learning有点用。
关心的点有:
- 性能
- ablation - training scheme, module design
- 速度
- 模型尺寸