BoolNet: Minimizing the Energy Consumption of Binary Neural Networks
2021/6/15
来源:arxiv2021/NIPS2021在投
resource:github上备份的包括ipad标注的pdf版本。
作者是与我们合作的HPI的郭年辉、Joseph、杨浩进老师,还有凯哥妃哥。
Summary:感觉工作非常solid…甚至可以说杀死了比赛(但又据说不如fracBNN杀)。这篇文章针对现在作弊严重的BNN现象(在BNN里引入大量FP32 op但是仍claim自己是FP的)提出了一种二值化程度很高的boolnet,具体做法是,修改shortcuts的起点保证shortcut两端的feature map都是binary的,同时将原来的32b元素加改成OR/XNOR,将BN merge到sign里,保证information flow是完全binary的;但是这种logic shorcuts很难进行信息的积累,所以引入了一种Multi-slices Binary Convolution,使用不同量化分界的sign进行量化,再加上Group Conv把额外的参数和运算降下来。
rating:4.1/5.0
comprehension:2.5/5.0
文章的贡献有:
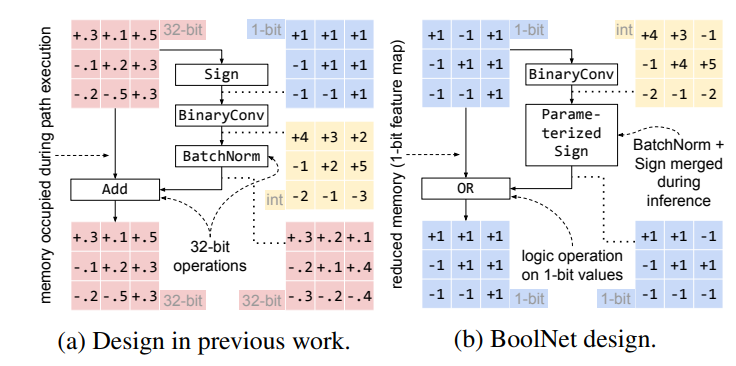
- 提出了一种feature map完全二值化的BNN(仅在BinaryConv后有部分Int16的值,但是很快就被BN-merged Sign量化掉了),具体的做法是将shortcut的起点从BN后sign前移到sign后(这种全binary的shortcut被起名叫做logic shortcut,并且由原来的element-wise addition改成Boolean functions:OR / XNOR)。在inference的时候将BN和sign merge到一起。在除了最后一层fc前外的地方把PReLU、average pooling、FP downsample Conv拿掉或者替换成max pooling和binary downsample Conv。这一块大致可以用下图解释:
- 提出了一种Multi-slice strategy,通过改变量化起点的方式利用相对幅度信息,这样可能会使通道数变成原来的k倍,就使用group conv来弥补。
Abstract
核心论点:很喜欢!认为现在BNN实际上是一种mixed-precision network,现在和FP counterpart性能接近的原因是在BNN中引入了很多FP32的操作(BatchNorm, scaling, and 32-bit branches, 而且中间的feature map和shortcut也都是FP32的),这实际上是一种作弊行为,对硬件实现非常不友好。
3 BoolNet
3.1 Improving Accuracy with Additional 32-bit Components
非常尖锐(但是有道理)。点出了一些用在SOTA BNN里的trick,这些trick里往往有很多32-bit op,实际上硬件消耗非常大:
- channel-wise scaling factor(本篇文章里没用scaling factor);
- 32-bit shortcut(这篇文章完全是±1的shortcut);
- 32-bit 1×1 downsampling(这篇文章真的用的是binary downsample conv…不过也好理解,因为前面都是全1-bit的fm了,这里虱多不咬了吧);
- PReLU activation(好像只在最后一层里用了);
- attention mechanism(Real-to-Bi里用input计算的scaling factor,这就叫注意力机制了吗)。
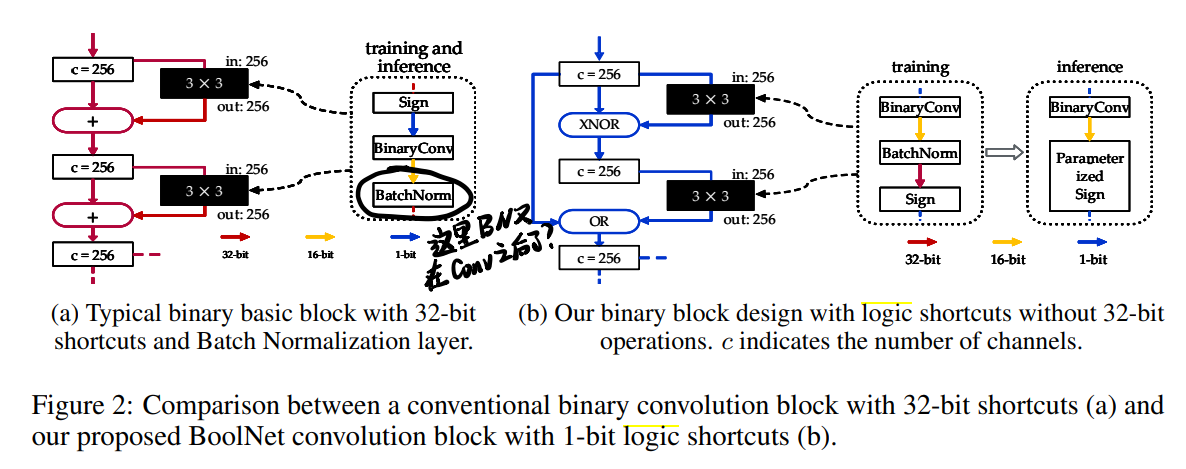
3.2 BaseNet: Replacing 32-bit Components with Boolean Operations
这里又调整了Conv block的顺序,把basic conv block里的顺序从{Sign-BinaryConv-BN}调成了{BinaryConv-BatchNorm-Sign}(这里有点问题,XNOR里不是reorder了吗,怎么这里又成了这种顺序?见后面的回答)。
3.2.1 Integrating BatchNorm into Sign Function
这里讲的是在inference阶段把BN融到sign函数里(很有点道理):

先分析了BN的作用原理(计算running mean和running variance,在训练阶段训练scale和shift parameters,在inference阶段固定scale和shift(有点问题,在inference的时候BN里的running mean和running variance还会变化吗?)),所以BN就可以和sign merge一下了,得到的结果就是上式中的(4)。
3.2.2 1-bit Logic Shortcuts
这块对shortcut的修改主要是:1)改变shortcut的起点;2)用OR和XNOR取代32bit addition。起了个名叫Logic Shortcuts,但是为了让OR和XNOR在训练的时候可导,在训练的时候用两个可导的term代替。
(注意,如上图所示,这里的shortcut有两种实际上,一个是OR连接的,一个是XNOR连接的)
3.2.3 Further Reducing 32-bit Operations
这里提了一些更精确的设置(指干掉32-bit op的方法)。
- 只在最后FC层前用了PReLU;
- 没用scaling factor;
- Binary 1×1 downsample conv,根据补充材料,最后采用了[1-bit Conv (groups = 1), MaxPool2d, BN, Sign]这种结构;
- 但是第一层Conv和最后一层FC还是FP的。
3.3 BoolNet: Enhancing Binary Information Flow
提了一种Multi-slices Binary Convolution,使用这种相对幅度信息(relative magnitude information)扩充feature map的容量(这里将一般的sign视为一种single-slice numerical projection)。

公式(6)——\(x_i^b = Sign(x_i, b_n)\)的输出结果是[N,C×k, H,W],为了保证通道数和计算数不变,这里引入系数为k的Group Conv。在input conv后第一个MS-BConv中引入了一个Local Adaptive Shifting,这个module由depth-wise 3×3 conv和一个BN layer组成,来调整每个piexl的零点(有点玄幻)。不过这种组卷积还是会在最后的downsample处增多op数。
又因为logic shortcuts和它对应的boolean op只能反映True/False信息,不能用有效积累信息,所以在每个block重用feature map(指输入Tensor被平分成两半,一半concate,一半参与运算,最后shuffle一下)。
3.4 Training with Progressive Weight Binarization
之前的完全binary information flow的努力会让模型对参数初始化更敏感,这里作者采用了一种progressive binarization technique,在训练阶段用hardtanh取代sign,可以被视为一种平滑的multi-stage train。inference的时候把这种hardtanh-STE再替换回sign。
4 Experiments
一些启发:
- 在最后一层Conv使用dilation而不是stride可能有点好处。
- BNN中能量的消耗主要发生在访存环节。
- 实验结果:
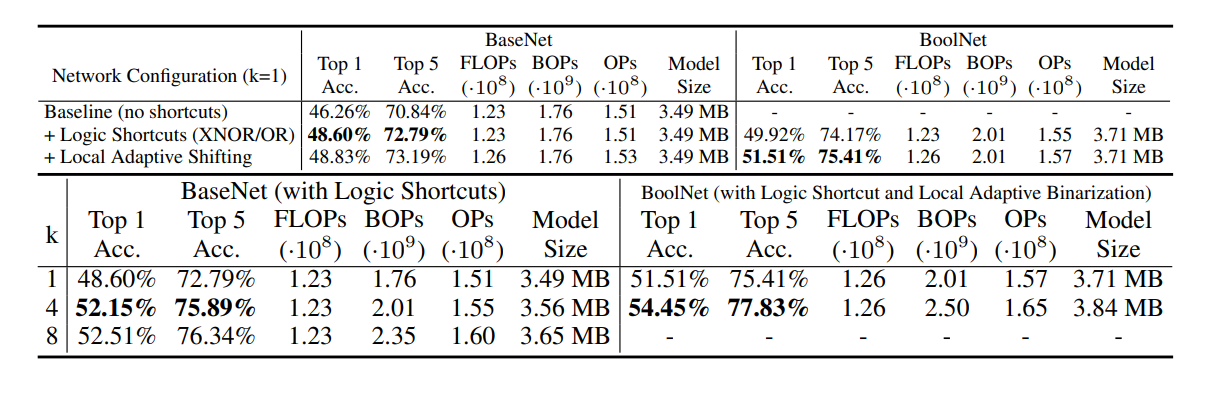
需要检查的问题:
Q1:Bi-real等网络的building block和XNOR是否一致?
A1:check过了,Bi-real的设置和XNOR不一样,原来认为XNOR layer reorder是BNN默认设置的认识是错的!- Q2:在inference的时候BN里的running mean和running variance会变化吗?