HINet: Half Instance Normalization Network for Image Restoration
2021/7/14
来源:CVPRW/NTIRE21
Resource:github上备份的包括ipad标注的pdf版本。
作者是旷视的Liangyu Chen, Xin Lu, Jie Zhang, Xiaojie Chu, Chengpeng Chen——他们怎么这么喜欢打比赛…不愧是做算法挣钱(能挣到钱吗)的。
Summary:这篇文章是SIDD上的SOTA,有一定参考价值(堆就完了)。提出了一个HIN block,在block中间将通道折半通过Instance Normalizaiton(另一半不动),用HIN block和ResBlock插到U-Net中,再将两个U-Net作为两个阶段拼成大网络,在两个网络之间用CSFF和SAM传特征和注意力图。
rating:3.8/5.0
comprehension:3.2/5.0
文章的贡献有:
- 将Instance Normalization加到提出的HIN block里,用两个U-Net作为两个stage拼成一张超网,并在中间套用CSFF和SAM模块,取得了SIDD上的SOTA性能。
1 Introduction
高级图像任务中有很多的Normalization:
- 分类任务中的BN和IBN;
- 检测任务中的Layer Normalization(DETR)和GroupNorm(FCOS);
- style/domain transfer任务中的Instance Normalization。
2 Related Work
2.1 Normalization in low-level computer vision tasks
本文出发点:在图像分类任务中常用的BN往往在底层视觉任务中不适用,这是因为:
- 图像恢复任务往往使用小mini-batch和小patch训练网络,导致BN的统计特性不稳定;
-
图像恢复任务是逐图像、密集像素值预测任务,尺度敏感,而BN适合尺度不敏感的任务。
- Instance Normalization在某种层度上可以看做是底层feature特征的normalization,这种normalization最初应用在style transfer领域,将style image和content image的逐通道特征align起来,在训练和测试阶段的仿射一致,可以校正特征图的均值和方差,而不影响batch维度,可以维持更多尺度信息。
2.2 Architectures for Image Restoration
经典报菜名环节:
- single-stage methods(复杂的架构设计):
- Densely residual laplacian super-resolution, CVPR20
- Density-aware single image de-raining using a multi-stream dense network, CVPR18
- multi-stage methods(将原来的网络拆解成简单的小网络):
- [Lightweight pyramid networks for image deraining, TNNLS19] introduce the mature Gaussian-Laplacian image pyramid decomposition technology to the neural network, and uses a relatively shallow network to handle the learning problem at each pyramid level
- [Progressive image deraining networks: A better and simpler baseline, CVPR19] proposes a progressive recurrent network by repeatedly unfolding a shallow ResNet and introduces a recurrent layer to exploit the dependencies of deep features across stages;
- [Deep stacked hierarchical multi-patch network for image deblurring, CVPR19] proposes a deep stacked hierarchical multi-patch network. Each level focus on different scales of the blur and the finer level contributes its residual image to the coarser level;
- [Multi-stage progressive image restoration, arxiv21] proposes a multi-stage progressive image restoration architecture, where there are two encoder-decoder subnetworks and one original resolution subnetwork, and proposes a supervised attention module (SAM) and a cross-stage feature fusion (CSFF) module between every two stages to enrich the features of the next stage;
3 Approach
3.1 HINet
本文提出的网络如下所示:
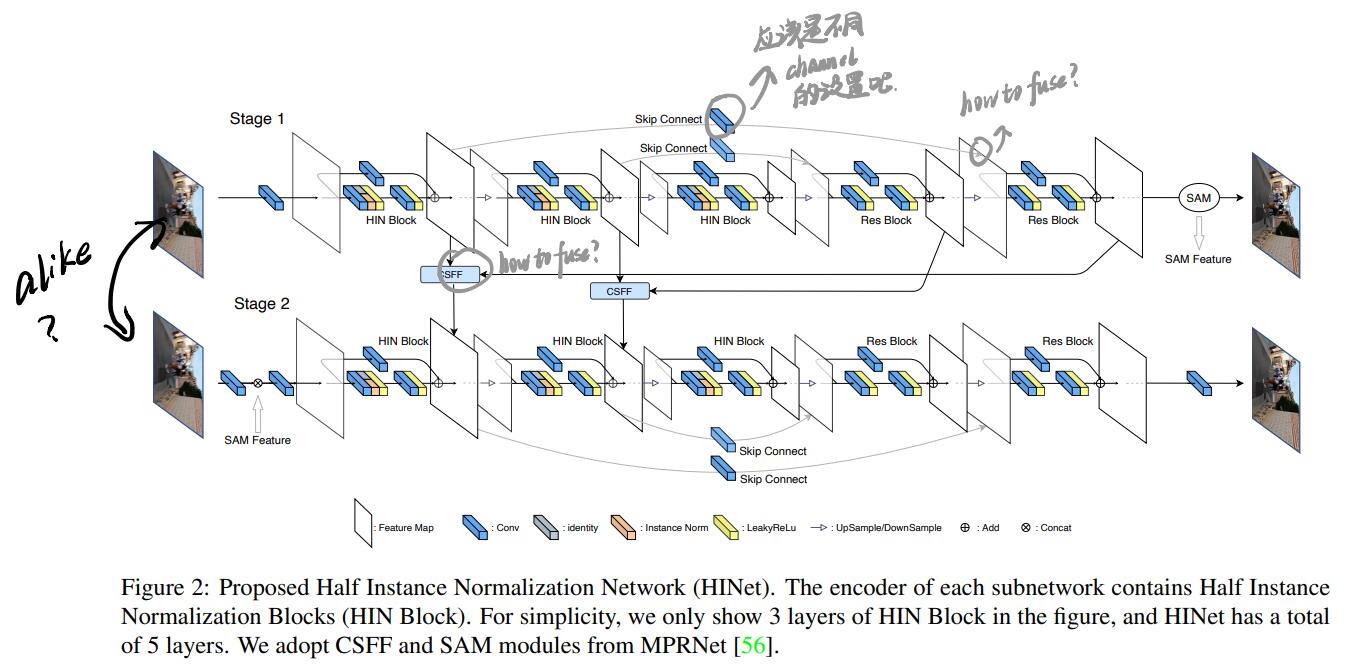
HINet由两个子网构成,每个子网都是U-Net,每个子网开始都由一个3*3的卷积层提取初始特征,编码器由5个HIN block组成,解码器由5个Res Block组成,在两个子网间使用了cross-stage feature fusion (CSFF) module和supervised attention module (SAM),前者将前一个阶段的不同尺度的特征融合在一起,丰富下一阶段的特征,后者将前一阶段提取的比较有用的信息传到下一阶段,而不怎么有信息的特征则会被attention masks掩码掉。
HIN block如下所示:
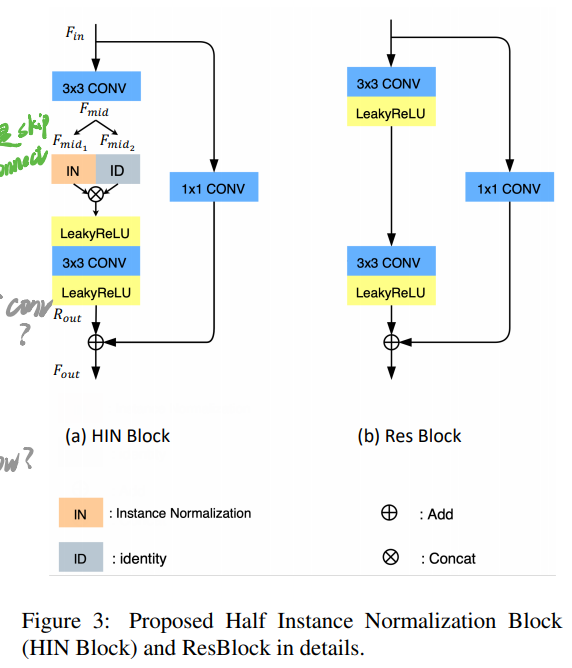
没啥好说的,就在中间把通道分成两半,一半过IN,一半Identity。
- 使用了PSNR loss,看样子每个阶段输出的是去掉的噪声?

4 Experiments
-
使用的bs=64,patch=256*256,真看不出来这俩有哪个小了。
-
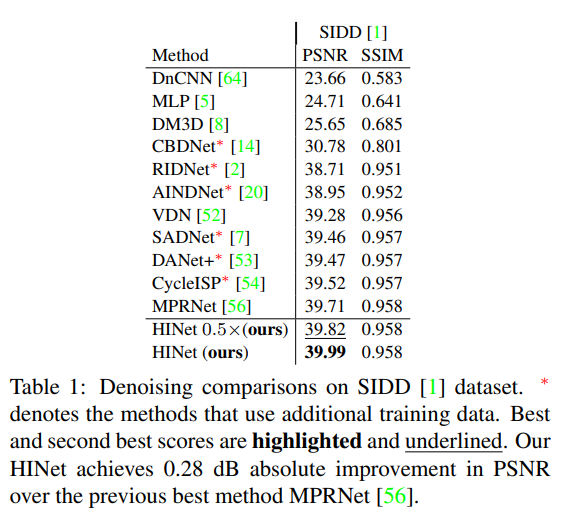
有用的benchmark on SIDD:
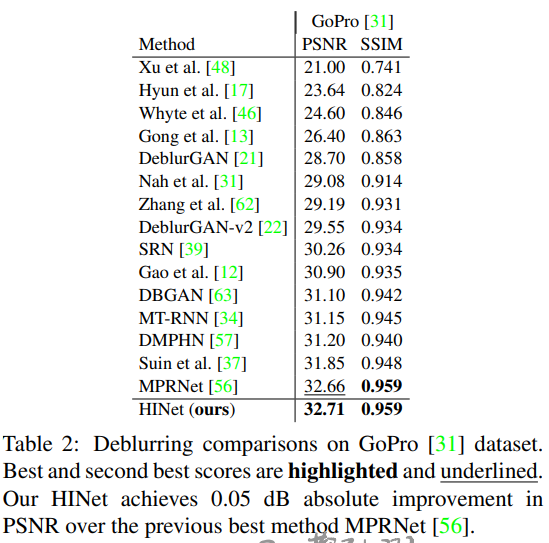
- 未来说不定有用的benchmark on GoPro(deblur):
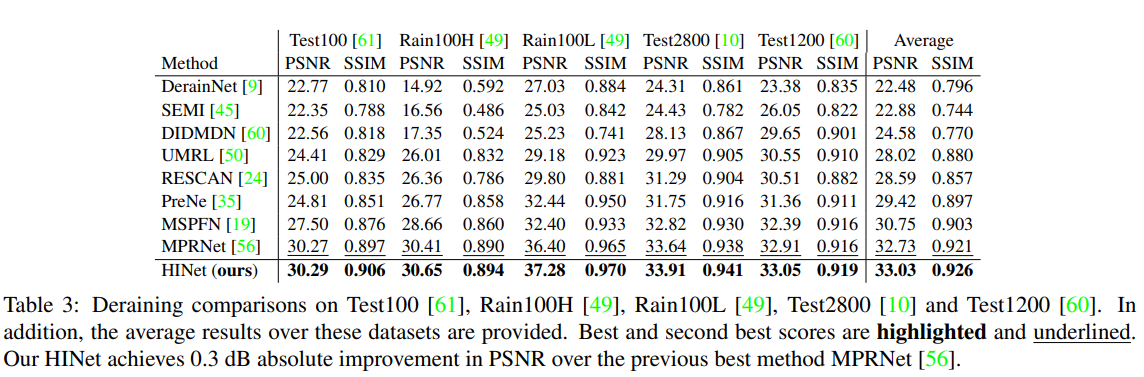
- 同样可能有用的benchmark for deraining:
4.4 Extension to HINet
实际比赛的HINet和前面说的有点区别,这些提点的方法应该可以注意下:
- Wider, Deeper:实际上用的HINet是2x宽,且在编解码器上各加了两个resblock(为什么不加hinblock?还是不好用呗)。
- Test Time Augmentation and Ensemble:在测试的时候还做了增强,而且用了3个model作ensemble,结果取平均。