WRPN: Wide Reduced-Precision Networks
2021/4/19
来源:ICLR2018
resource:github上备份的包括ipad标注的pdf版本。
作者是Intel Accelerator Architecture Lab的Asit Mishra、Eriko Nurvitadhi、Jeffrey J Cook和Debbie Marr(看起来像是印度作者)。
Summary:文章还可以,用非常朴素的方法打点,应该是读明白了(第一次comprehension打5.0,有丶激动)。文章创作的背景是当时大多数量化方法都关注weights(后简称为W)的量化,很少有(推测)对activation(后简称为ACT)做量化的研究,作者的出发点是在训练阶段,ACT占比很高,消耗了大部分内存,所以需要对ACT进行量化(但是我觉得这个出发点很站不住脚,因为在实际应用中推断是对一张图进行的(当然也不排除类mini-batch的应用场景,但是我目前还没有这种发现),所以这种内存消耗的分析非常无所谓,与其讲这个故事,不如说Binary W和FP ACT作用实际上还是FP OP,对加速而言没有多大帮助,倒还显得顺理成章)。作者提出的方案是扩大通道数量,给的例子是4 x A, 2 x B, 2 x Ch可以达到和FP model一样的精度。后面还有在GPU/FPGA/ASIC上的测试(不知道是仿真还是真做了),有一点启发(GPU上加速效果非常受限,ASIC因其非常实在的DIY支持所以加速效果最明显,甚至超过了理论值),还有些聊胜于无的quantization scheme的改进。
Rating: 3.0/5.0
Comprehension: 5.0/5.0
文章的贡献有:
- (应该是首先)提出扩展若干倍通道数目提量化神经网络(包括BNN)在内的点数;
- 在GPU/FPGA/ASIC上做了(或者仿真了)加速效果的实验;
- 提了一种简化的quantization scheme(似乎是没有用量化映射而是直接hard-clip,然后用了些cheap的方法实现量化)。
1 Introdution
提了个奇怪的说法,先前只binarize weights的方法一般只在batch size比较小的时候才能增益inference step:
Further, most prior works target reducing the precision of the model parameters (network weights).
This primarily benefits the inference step only when batch sizes are small.
(2021/5/25 update)想了下其实挺好理解的,因为BS大的时候基本上都是ACT,那么只Binarize Weight带来的增益其实挺小。
2 Motivation for reduced-precision activation maps
讲的是本文的故事,讲ACT内存优化确实不是个好的切入点。
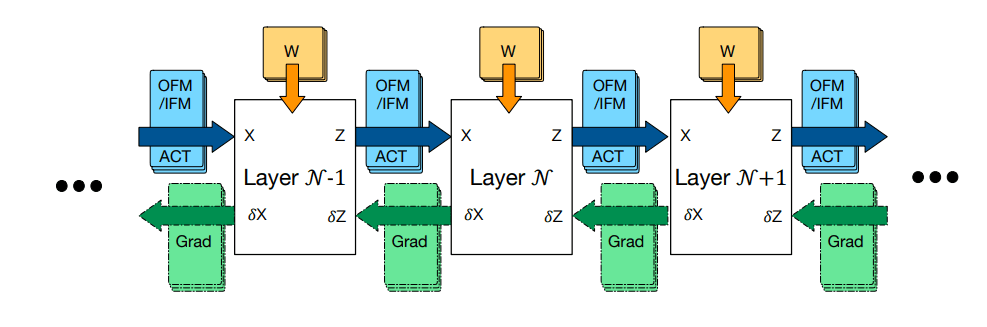
这张图还有点用,说训练时内存占用是ACT、W和input gradient maps (δZ)与back-propagated gradients (δX)的最大者,最大还好理解(传一次就把上一步骤的梯度删了,但是不需要存一份更新参数吗?),前面δZ和δX的区别是啥?关于ACT和W的梯度?推断的时候需要的空间就是IFM和OFM各最大的内存块,可以理解。
原文:
The total memory requirements for training phase is the sum of memory required for the activation maps, weights
and the maximum of input gradient maps (δZ) and maximum of back-propagated gradients (δX). During inference,
memory is allocated for input (IFM) and output feature maps (OFM) required by a single layer, and these memory
allocations are reused for other layers. The total memory allocation during inference is then the maximum of IFM
and maximum of OFM required across all the layers plus the sum of all W-tensors.
3 WRPN scheme and studies on AlexNet
ACT量化/加宽CH的另一个优点我没看懂:
Apart from other benefits of reduced precision activations as mentioned earlier, widening filter maps also
improves the efficiency of underlying GEMM calls for convolution operations since compute accelerators are
typically more efficient on a single kernel consisting of parallel computation on large data-structures as
opposed to many small sized kernels.
4 Studies on deeper networks
- ResNet34的设置,没有reorder layer,使用了一样的超参和lr。
- 但是使用scaling factor了吗?似乎用了第五节的量化方法?
- 是这样没错
5 Hardware friendly quantization scheme
- 用的量化方案中,W的量化区间是[-1, +1],A的量化区间是[0, 1],推测使用了ReLU,具体方案:
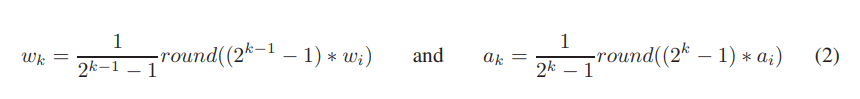
-
在量化后使用scaling factor,具体到binary的情形中,scaling factor用的是BWN的方案。
-
TTQ和DoReFa用了复杂的range arrange方法,本篇文章就用了简单的clip:
TTQ and DoRefa schemes involve division operation and computing a maximum value in the input tensor.
...
We avoid each of these costly operations and propose a simpler quantization scheme (clipping followed by rounding)
- 一个显而易见的结论:实际应用中的加速效果取决于使用的硬件平台能多有效地利用这些低精度操作。
in practice the efficiency gains from reducing precision depend on whether the underlying hardware can take
advantage of such low-precisions
- 这大概解释了在FPGA上性能提升明显的现象,以及为什么ASIC上出现了2-3个数量级的提升:
Reducing the precision simplifies the design of compute units and lower buffering requirements on FPGA board.
Compute-precision reduction leads to significant improvement in throughput due to smaller hardware designs
(allowing more parallelism) and shorter circuit delay (allowing higher frequency).
...
ASIC allows for a truly customized hardware implementation.
- 搬自Conclusion的结论:降低精度可以让自己设计的计算单元和buffer性能更好。
reducing the precision allows custom-designed compute units and lower buffering requirements to provide
significant improvement in throughput.
Remained Questions
- 读一下看看affine transformation是怎么回事。