nn-Meter: Towards Accurate Latency Prediction of Deep-Learning Model Inference on Diverse Edge Devices
2024/3/22
来源:Mobisys21
resource:github上备份的包括windows标注的pdf。 作者是MSRA的团队,Li Lyna Zhang, Shihao Han, Jianyu Wei, Ningxin Zheng, Ting Cao, Yuqing Yang, Yunxin Liu。
Summary:文章提出了一款针对边侧设备的延时建模工具nn-Meter,该工具针对特定硬件+特定运行时离线建模,将模型按照kernel-level粒度进行拆解,分别预测延时并加和得到总体延时。
- 整个模型延时预测流程大体可分为两个阶段,离线数据采集+预测器训练 与 在线延时预测:
- 离线数据采集阶段,nn-Meter有两件需要解决的事,解析待建模硬件+运行时的图优化方式(涉及算子融合,用于后续预测模型延时时的模型拆解)与特定kernel的延时预测;
- 对于图优化方式 / 算子融合规则解析,nn-Meter采用手工规则匹配的方式,预设可能的算子融合方案作为测试用例,通过实测算子组合的延时来判断某种类型的融合是否发生,将匹配到的规则记录下来作为该硬件+运行时(该规则和"硬件-运行时"是一一对应的)的图优化描述;(即通过穷举-匹配的方式确定某种硬件+运行时是怎么做计算图切分和优化的,因为默认运行时后端是不开源的)
- 对于kernel的延时预测,从常用的24个CNN架构模型中统计出kernel类型和参数配置,以此作为采样范围,并按照各个kernel配置出现的频次进行特定分布下的采样;在采样得到某个kernel的配置后,在特定硬件上部署测试该kernel的延时,利用(kernel配置,kernel延时)数据训练一个预测器(每种类型的kernel对应一个预测器,输入kernel配置,预测kernel延时)。
- 在线延时预测阶段,nn-Meter利用离线解析得到的图优化规则对输入模型进行拆解,拆解成若干kernel的组合,利用离线训练的kernel预测器分别预测模型各部分的延时,最后加和得到总延时。
- 在整个nn-Meter的测试流程中,作者highlight的关键设计有:
- Kernel Detection - 手工设计测试用例来探测特定硬件的算子融合规则;
- Adaptive Data Sampling - 目的是减少采样到不常见的kernel配置;根据统计出的各kernel配置出现的频次来采样。
rating:5.0/5.0
comprehension:4.5/5.0
个人comment:非常全面的工作,很有启发性;提出的方法论泛化性较强且已开源,可以在**的硬件上测试下;
文章细节
- 本部分按照原文章节组织,内容比较琐碎
Intro
- 作者提到GCN-based方法泛化性比较差;
- nn-Meter有一个关键的预设前提,即端侧设备上的模型推理是以kernel为单位、顺序推理的(dividing a whole model inference into multiple kernels that are independent execution units of the model inference on a device)
- 讨论:此处的"kernel"其实更应该称之为"fused-operator";一般认为"operator"是指深度学习框架里的最小运算单元(一个层),比如一层Conv,一层ReLU激活,而"kernel"指的是硬件向上层提供的可执行的指令;本文的"kernel"没有那么底层,按照文中的描述来看其实是backend优化(融合)后的operator,比如"Conv-BN-ReLU"。
- 这样拆解的优点是,模型、算子的种类虽然多样,但是其底层的、作为基本执行单元的kernel种类比较有限,更适合预测;
- 该方案的难点是,大多数推理框架/后端不开源,因此不知道kernel的种类和融合规则;kernel的配置空间很庞大(比如单个Conv算子,它的配置有输入特征的宽W与高H、卷积核尺寸K、卷积步长S、输入通道数C_{in}和输出通道数C_{out}),采样效率比较低;这两个难点分别对应了本文的解决方案kernel detection与adaptive data sampling;
- 本文还提供了一个包含26000个测试样例的数据集,用于评价性能预测结果,该数据集是在常用架构(AlexNet, VGG等)的基础上采样kernel配置得到的。
- 注意区分这里的数据集和Kernel Detection中的测试用例,前者是以模型为单位的、评估不同性能预测方案的数据集,后者是以kernel组合为单位的,来探查不同backend对应的融合规则的。
Background Knowledge
- operator粒度的建模方案往往不能考虑推理框架做的算子融合优化,因此精度不高;
- 作者提了一个有意思的分类方法,将推理优化分成了backend-independent与backend-dependent的两种类型:
- 前者和backend无关,比如𝑎𝑑𝑑(𝑐1,𝑎𝑑𝑑(𝑥,𝑐2))->𝑎𝑑𝑑(𝑥,𝑐1 +𝑐2)
- 后者是和backend相关的融合规则,比如有的框架会把Conv-BN融合在一起,有的不融合;
Overall Design
-
nn-Meter总体框图:
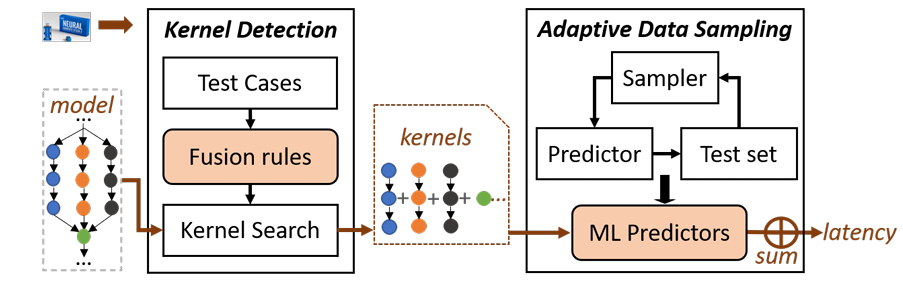
-
原文总结:

Kernel Detection
- 影响operator fusion的因素有operator的类型和连接方式;
- 类型包括injective和non-injective两类,前者比如ReLU,可以融合到其他算子(Conv)的循环体内,后者比如pooling,没法和其他算子的循环体融合到一起;
- 连接方式包括顺序连接(单输入单输出)、多输入、多输出三类;
- nn-Meter预设多种融合规则,通过kernel组合的延时与单个kernel延时之和是否存在差异来判断某个融合规则是否生效:
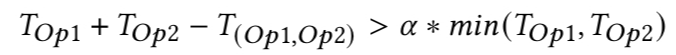
- 对于有多种组合可能的kernel,挑选延时最接近的规则作为生效的规则:

- 在得到特定硬件(+runtime)的融合规则以后,通过DFS来拆解待预测输入模型:

Latency Prediction
- 给了一些有意义的观察:
- Conv和DWConv是模型推理延时的大头;
- Conv的配置采样空间很大(主要是输入输出通道的选项很多);
- Conv的配置和性能之间存在非线性,随机采样可能会遗漏一些关键数据点:
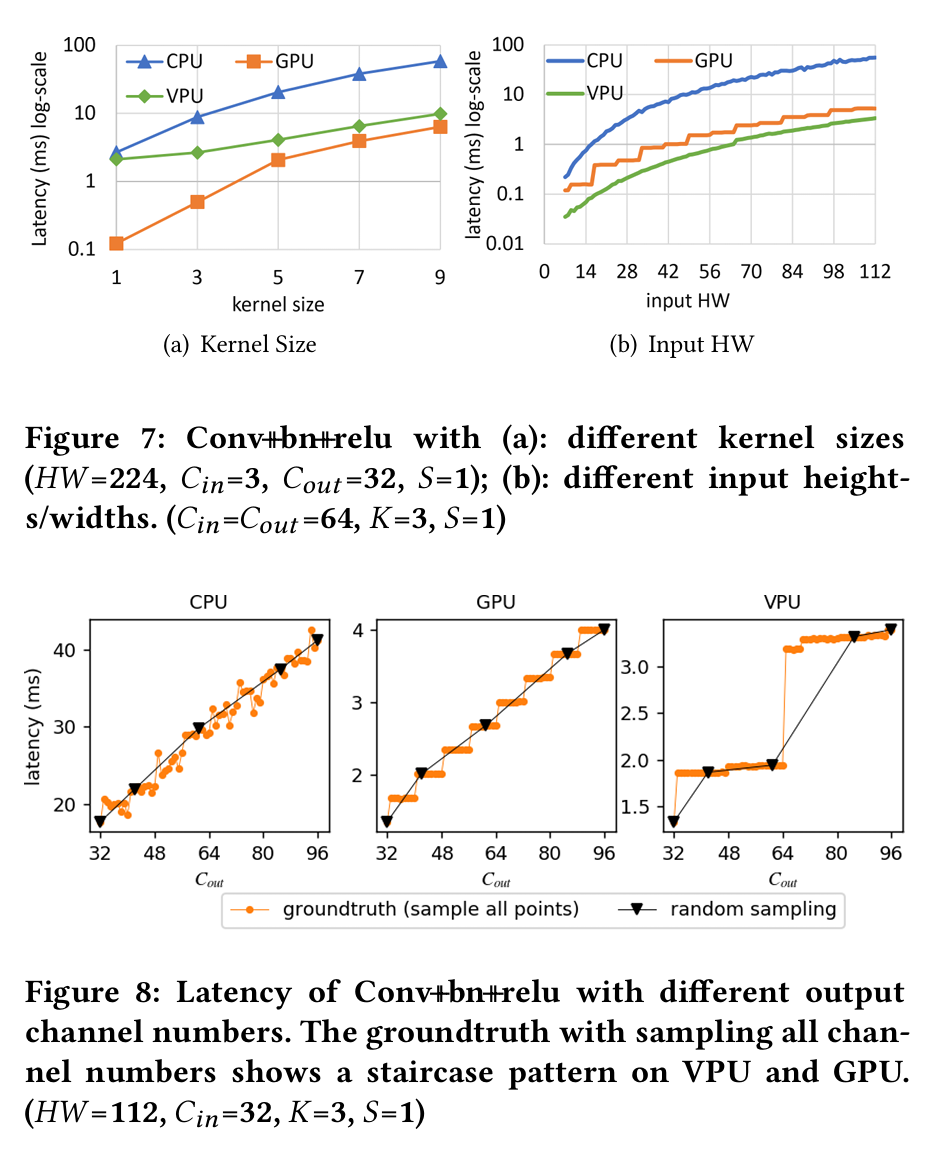
- 设计了一种采样方案,首先从常用模型里统计出可能出现的kernel类型和kernel配置,kernel配置会张成一个采样空间(比如Tab. 5里给了Conv-BN-ReLU算子可能的配置);根据不同kernel配置出现的频次进行采样,来减少不常出现的算子配置(比如常见的卷积通道是64,就多在64附近采;2160这种极端配置附近少采);在每次采样后,将新采样的数据和原来的数据混到一起,训练该kernel对应的预测器(一个random forrest模型);对于一些预测不好的配置,在那个配置附近更细粒度地采样,来扩充数据集。
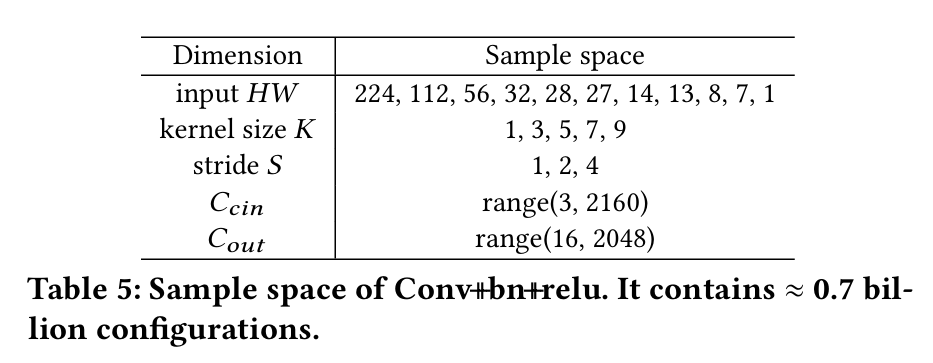
- 采样方案如下:

Experiment-Related
- nn-Meter提出了不少有意思的评估方案,如k-fold cross-validation experiment、kernel configuration overlaps等,未来若做文章可参考。
-
实验表格,内含多项可参考的数据:
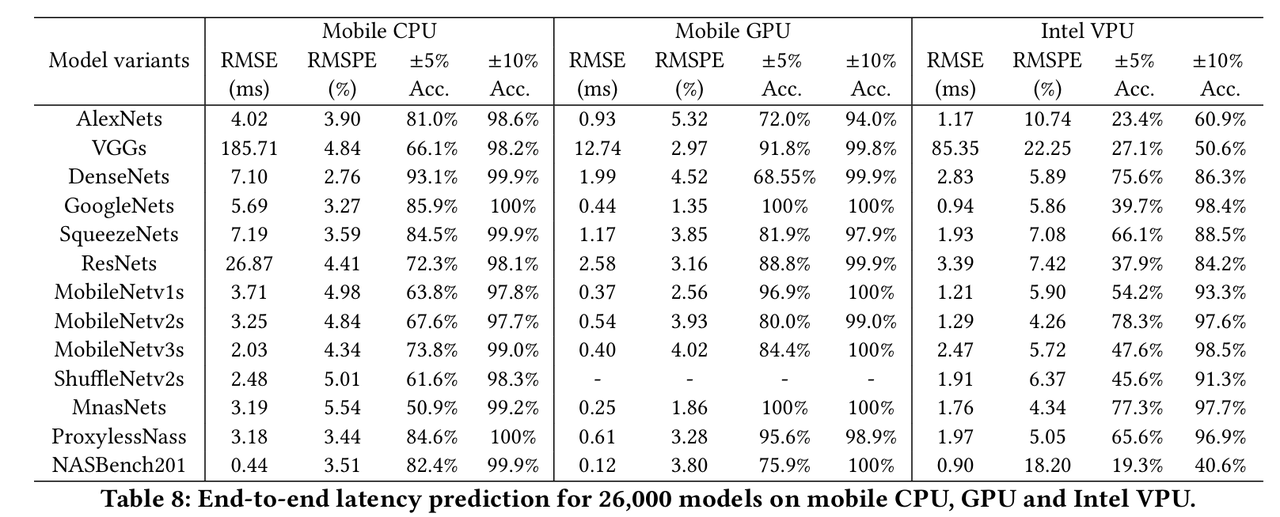
- ± x% Acc是指相对误差在x%以内的预测占数据总量的比例,例如图中Mobile CPU - AlexNets - ±10% Acc.为98.6%的意思是,有98.6%的AlexNets模型的预测结果和真值之间的差距在10%以内。
- nn-Meter作为目前的SOTA之一,能达到约100%的 ±10% Acc. ,但是RMSPE(相对均方根误差)要在5%附近。
讨论
- nn-Meter有一个顺序推理(kernels all run sequentially)的前提,即认为端侧设备只能在单个计算单元上,按照模型拓扑顺序地依次推理,对于异构并行计算不适用;
- nn-Meter面向CNN架构,没有报告语言模型相关的预测结果;
- nn-Meter是对特定硬件 + 运行时组合设计的,在不同的硬件之间泛化性较差,所以换一个硬件 / 运行时有更新就得重测一次;重新建模的时间开销比较长,大约要1-4天;
- nn-Meter的规则匹配是人工设计的,可能不能覆盖到所有情况:
