Training Binary Neural Networks through Learning with Noisy Supervision
2021/5/17
来源:ICML2020
resource:github上备份的包括ipad标注的pdf版本。
作者是Huawei Noah王云鹤组。
Summary:文章感觉一般,提了一种Fine-tune的方法,具体是把weight的quantizer从简单的sign换成一个learnable function(在文章中是Neural Network/CNN),将输入的FP W通过该函数变成量化后的值(虽然我并不清楚为什么FP weight过一个CNN能变成quantized value吧…或许这个量化的值并不确定是±1?不对..又好像是..似乎没有scaling factor?Figure 2 显示的确实没有scaling factor)。对于每层的latent weight引入一个新的loss term来,将sign直接量化的weight作为noisy label进行含噪声的监督学习(这种mapping function)。所以这个方法只是调优+作用到W,至于A,管它呢。
Rating: 2.0/5.0
Comprehension: 3.0/5.0
文章的贡献有:
- 提出了一种Fine-tune的方法,在预训练的模型上再同时端到端训quantizer和latent weights,用训练的CNN将FP W(但是不清楚是per layer来还是per filter作为输入,但是这个model是per layer的)作为输入产生binarized weight。这种方法据说可以解决直接量化不能handle不同weight之间关系的问题。
- 还说了一种无偏estimator,但是是用来噪声监督的副产物,理论分析了在clean distribution(没弄明白)下能收敛到最优B W(这里有歧义,不知道是在clean distribution条件下可以收敛到还是在Equal10变化下可以收敛成这种条件下的效果,哪怕是用noisy label训练的)。
同样用一张图来说明本文的工作:
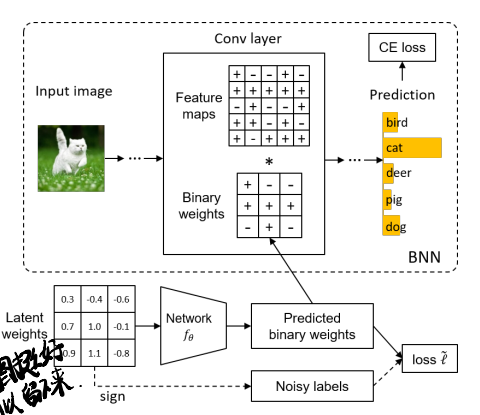
1 Introdution
本文的出发点:单独二值化W不能充分探索神经元之间的关系,因此可能达不到最佳值。同时,STE估计的梯度经常产生带有噪声的不精确的W,也就是一些二进制的W被错误翻转成了相反的值。
2 Related Work
2.2 Learning with Noisy Labels
有点意思,扩充知识面(没多大用)。
Learning with noisy labels可以分为以下几类:
- Label correction:"标签校正旨在将原始标签中错误的标签校正成正确的,现有的方法通常使用一个clean label inference module来校正错误标签。这种推断模块可以是NN,可以是图模型,也可以是conditional random fields。但是这种方法需要额外的干净数据或者开销很大的噪声检测过程,在实际应用中行不通"。
- Refined training strategies:"精炼训练策略提供了一种针对错误标签鲁棒性的新式学习框架。这些方法包括MentorNet和Co-teaching,他们将标准的学习过程替换成了复杂的干预过程"。
- Loss correction:"损失校正方法提供了适合噪声标签的标准损失函数,一种通用的方法是建模噪声转变矩阵来定义一类翻转成另一类的概率…(罗列)…噪声鲁棒损失函数是另一类处理噪声标签的技巧,比如泛化交叉熵,标签平滑正则,对称交叉熵"。
3 Approach
3.1 Binary Weight Mapping
- 3.1末尾提到只用l_cls(标准交叉熵)来监督网络会使每层中的mapping funciton缺少直接监督,因此后面加了auxiliary loss(话虽如此,但实际上是以一个被alpha加权的loss term出现的?所以本质上还是可以归类为修改loss函数?看来这些方法在某些维度上是相通的呢)
3.2 Learning with Noisy Supervision
- 所以那个estimator果然指的是l_tilde(Q_hat, Q_tilde)吧!(也可能是Equal16 Sample average)
- 用的loss correction approach看不太懂…(主要是Equal10那里,l_tilde到l的变化不懂)
- 但是又好像懂了!Equal10是应该是目标,希望修改Equal7使得Equal10成立,后面应该就顺势推出了l_tilde(Q_hat, Q_tilde)的形式。
- Theorem 1上下文是什么怪物…看起来有些硬核,也不懂(有新问题了!不知道是在clean distribution条件下可以收敛到还是在Equal10变化下可以收敛成这种条件下的效果,哪怕是用noisy label训练的),至于(R_hat)_(l_tilde)是啥就不重要了,但是clean distribution是啥?是说用noisy lable训练的也能收敛到没有noise的label训练出来的效果吗?
- 最后用个algorithm来总结一下文章:

4 Experiments
这里提到使用的binarize依然是经典的:
- 不量化第一层Conv和FC层
- 不量化downsaple层