21/8/23商汤龚睿昊讲PTQ
2021/8/23
备份链接:https://github.com/YouCaiJun98/YouCaiJun98.github.io/blob/master/Backups/Talks_and_Lectures/Talks/20210823-%E5%95%86%E6%B1%A4%E5%AD%A6%E6%9C%AF%E5%85%AC%E5%BC%80%E8%AF%BE%E7%AC%AC026%E6%9C%9F%E7%A6%BB%E7%BA%BF%E9%87%8F%E5%8C%96%E7%A0%94%E7%A9%B6.pdf
分享者是商汤的龚睿昊,21年北航硕士毕业,之前读过他的survey入门BNN,有点强欸,个人主页。
内容分为下面三个部分,模型量化的基本概念、离线量化现状和基本方法与离线量化的关键要素,第一部分基本上没啥用,第二部分涉及硬件部署的东西也不懂,感觉第三部分还挺重要的。
模型量化的基本概念
- 模型压缩的目标:让模型变小变快还尽可能保证精度不降,常用方法(known)
- Quantization
- Sparsity
- NAS
- Distillation
- 一些已经知道的分类方法:
- 均匀量化与非均匀量化
- 对称量化与非对称量化
- 量化粒度:per-tensor & per-channel
- 生产量化模型的四个等级(这个感觉还挺有用,照抄):
- Level 1:无数据离线量化
- 无需数据,不需要反向传播,一个API调用完成量化模型生产
- Level 2:有数据离线量化
- 需要数据,不需要反向传播,数据用于校准BN,或者统计激活值分布,用于降低量化误差
- Level 3:量化感知训练
- 需要数据,需要反向传播。通过训练和微调使量化模型达到可接受的精度,一般需要完整的训练过程和超参数调整
- Level 4:修改网络结构的量化感知训练
- 需要数据,需要反向传播,同时调整网络结构。需要明显更多的训练时间和细致的超参数调整
- Level 1:无数据离线量化
提了两个问题,还挺有价值:
- 如何获得实质的推理性能提升(这里不是很理解,缺硬件部署背景):
- 硬件特性(指令支持和架构设计)支持
- 软件推理库优化(又是不懂的名词)
- 手工优化
- 编译优化
- 躺
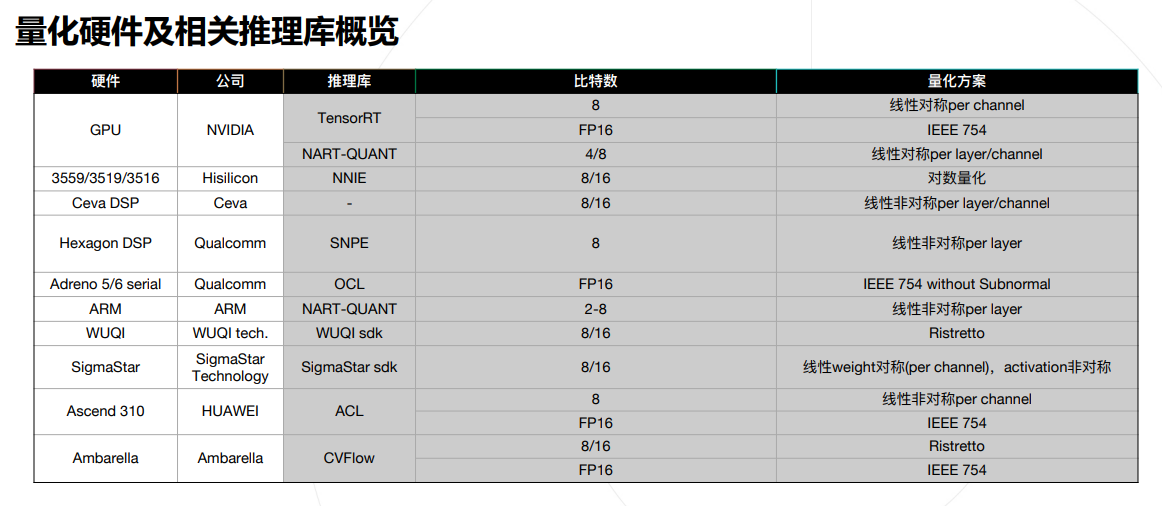
- 这张图按说有用,我不懂,但我大受震撼:
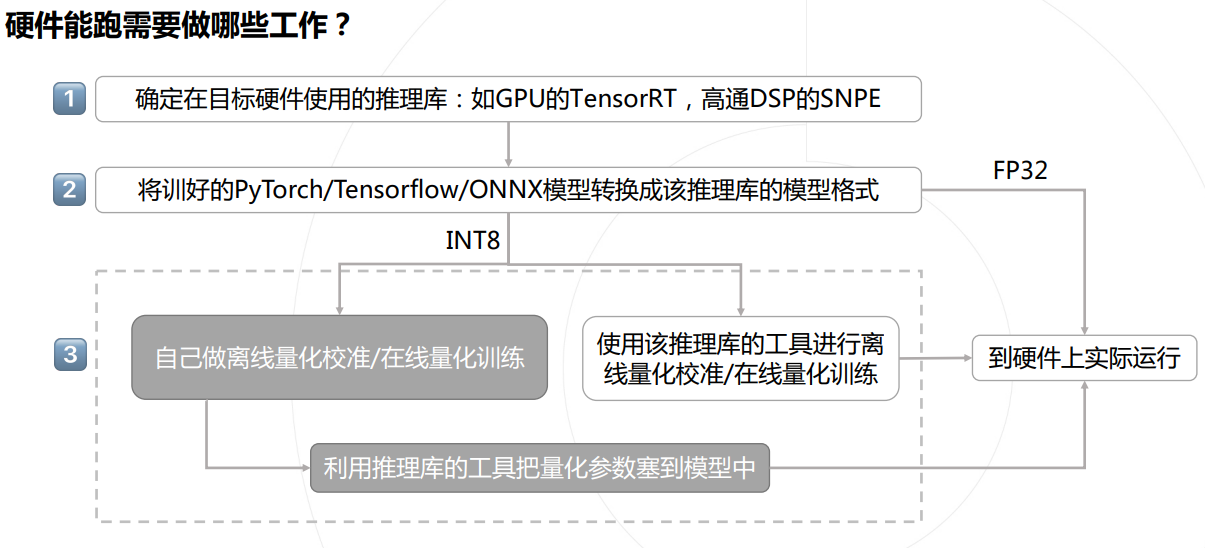
- 下面这张流程图也挺有用:
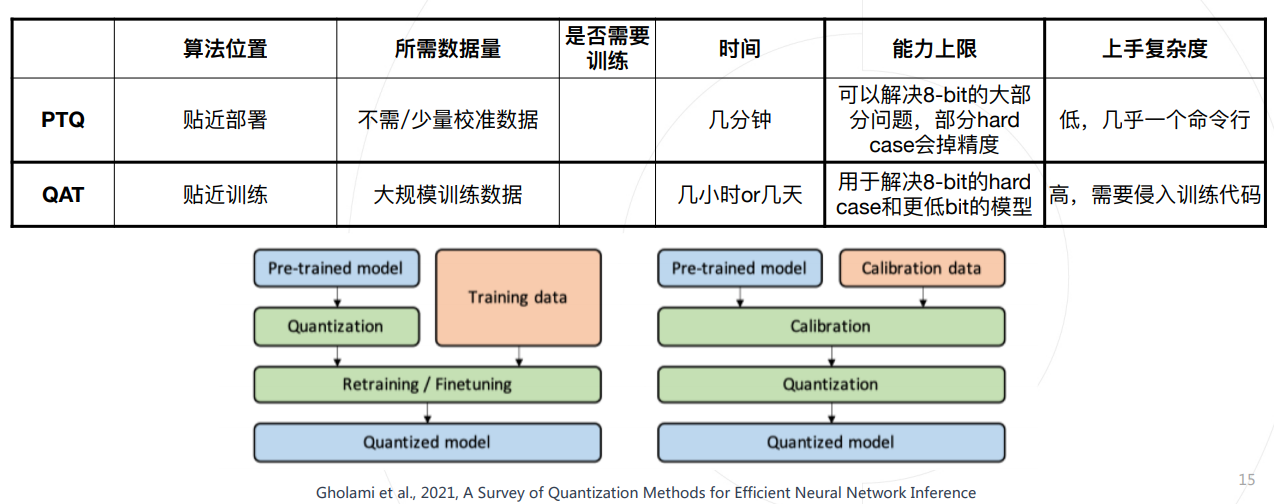
- 如何挽救精度损失:
- 还是PTQ & QAT,以及一张总结:
离线量化现状和基本方法
- 这里的总结感觉好怪,"解决的主要问题:给定一个Tensor,如何确定其截断范围",这就是PTQ主要需要解决的问题吗?

-
大多数深度学习硬件,全都支持基本的离线量化校准,这是因为离线量化是最快而且可以完全独立于训练的方式,最容易支持,使用方式也最容易被人接受。
-
离线量化的难点(总结不错):
- 校准数据有限(这点说得不太对,应该是校准数据与实际数据的差异?)
- 夜间、白天
- RGB/近红外数据domain
- 异常数据分布
- weight分布异常(特别大的weight)
- 优化空间有限
- 之前只能调整量化参数,现在可以微调weight(应该是说可以改BN等?)
- 优化粒度选择
- Layer by layer or End to end
- 上限会被QAT bottleneck?
- 校准数据有限(这点说得不太对,应该是校准数据与实际数据的差异?)
离线量化的关键要素
- 校准数据
- 校准数据是否能代表实际场景?
- 学术界定义的两种场景:
- 无数据量化
- 直接借助BN统计值确定截断值
Markus et al., 2019, Data-Free Quantization Through Weight Equalization and Bias Correction - 利用BN统计值等信息生成图片,再用图片做校准
MixMix: All You Need for Data-Free Compression Are Feature and Data Mixing
- 直接借助BN统计值确定截断值
- Cross-domain量化
- 定义了用A domain图片校准,去B domain测试的效果gap
MixMix: All You Need for Data-Free Compression Are Feature and Data Mixing
- 定义了用A domain图片校准,去B domain测试的效果gap
- 无数据量化
- 总结:
- 学术界比较极端,假设拿不到校准数据或者不同domain的校准数据
- 工业界思考的更多的是如何帮大家挑出最有效的校准数据实现最佳精度
- 异常层分析
- Merge BN后可能导致某些weight出现极端值,打回重训/QAT
- concate层与element-wise 等tensor merge层 - 难解决,靠引入QAT的约束,最坏方案是使用混合比特
- 优化空间和方式
- 除了传统的量化参数s与z(\(x_q=clip(round(\frac{x}{s}-z),n,p)\))外,对round函数进行修改
Markus et al., 2020, Up or Down? Adaptive Rounding for Post-Training Quantization. - 总结:
- 引入Round的优化之后将可优化的空间进行了数量级的放大,效果显著提升
- 不完全符合早期的离线量化定义,但确实可以独立于训练进行,也不需要标注的标签,使用成本很低(把参数摘出来量化?)
- Adaround能够在PTQ中训练rounding,学习一个额外的w加在scale里面(涉及了反传,但是能够独立于训练进行)
- 除了传统的量化参数s与z(\(x_q=clip(round(\frac{x}{s}-z),n,p)\))外,对round函数进行修改
- 优化粒度选择
- 不同级别:tensor、layer、network
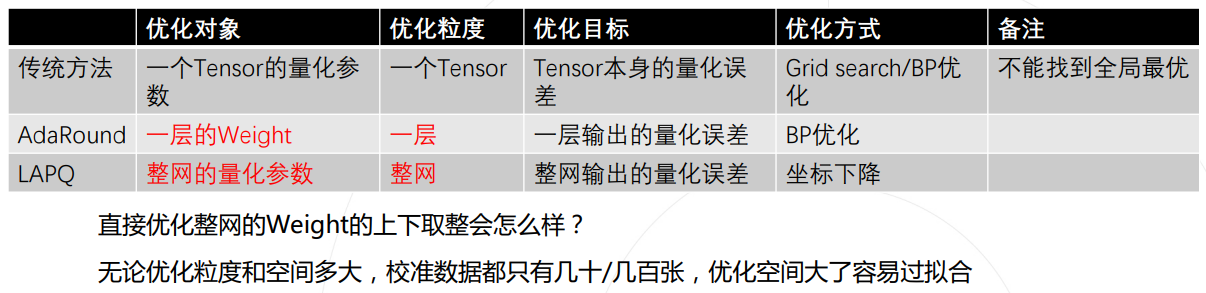
BRECQ : Pushing The Limit of Post-training Quantization by Block Reconstruction
上面这篇文章探索了不同的粒度(带来量化空间大小的变化)对量化的影响,以块为单位作为量化粒度可以更好地权衡?
总结
照抄:
- 模型量化作为比较早被硬件支持的压缩方式,被广泛使用
- 离线量化作为低成本、独立于模型训练的量化模型生产方式,被广泛使用
- 硬件厂商自带的工具支持基本的离线量化算法,但由于缺乏实际场景打磨,对掉点问题的挑战来源意识不足
- 需要更先进的离线量化算法和成体系的经验
- 离线量化的几个关键要素:
- 校准数据
- 异常层分析
- 优化方式和空间
- 优化粒度
- Model Quantization Benchmark