21/9/9商汤QAT talk
2021/9/9
首先是概览:

量化感知训练算法概览
- 主要是一些preliminary和前情提要:
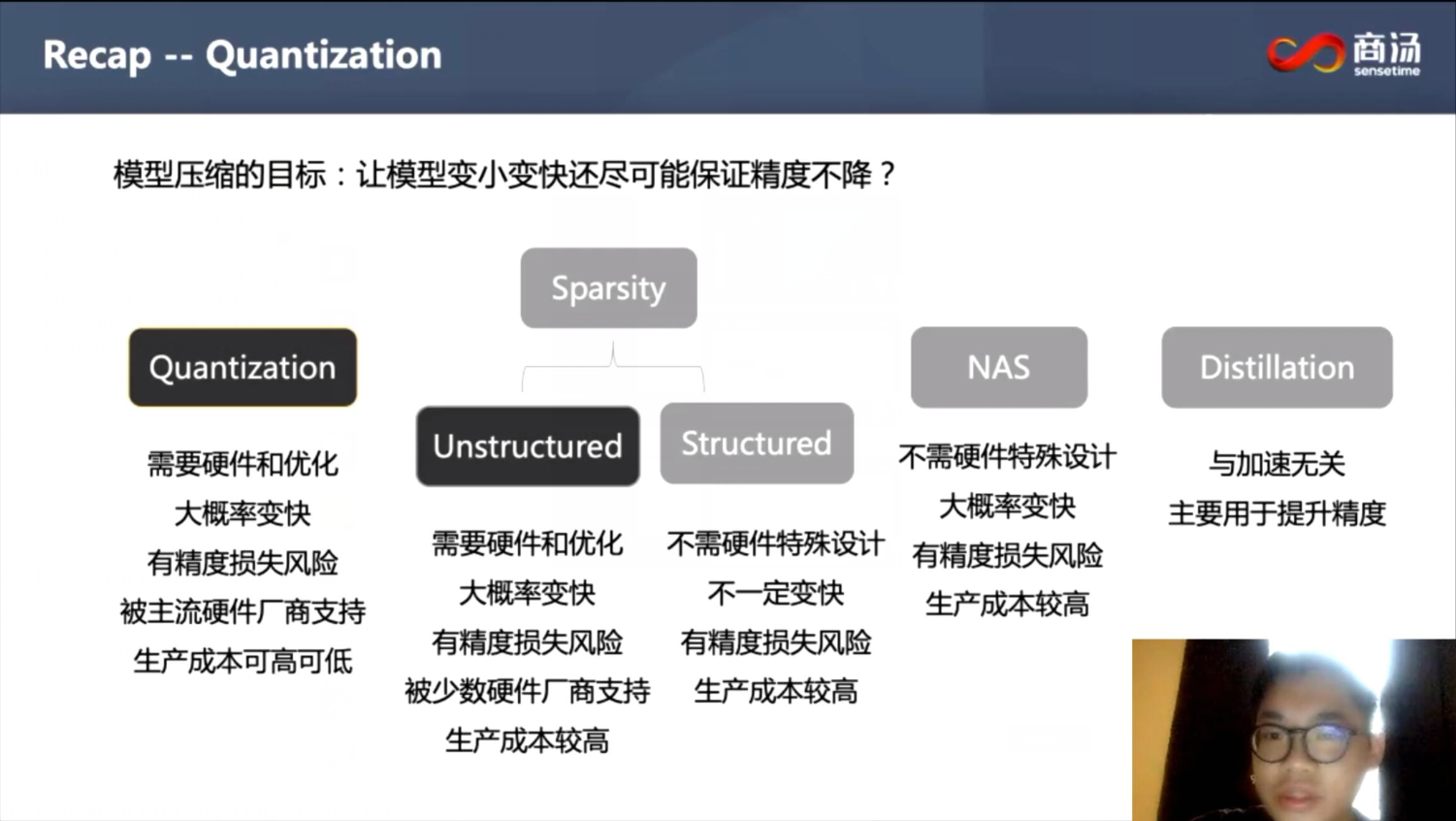



- MQBench只讨论均匀量化,非均匀量化需要特殊硬件设计支持,不易部署。
- 后面简单介绍了DoReFa-Net、PACT、QIL、LSQ(sota)四种量化算法,这些算法的学术设置有以下特点:
- 对A与W都进行量化,首层与最后一层保留精度较高
- 逐层、对称量化,激活值采用unsigned量化,这是因为经过ReLU激活值都变成正数,但是在硬件部署时不支持这种本质上是非对称的量化方式(只支持"绝对"对称量化,既量化区间关于0点对称,学术上对A的4-bit量化实际上要浪费掉符号位,只有3-bit可用)
- 无法真正部署到硬件上(和hardware backend不匹配,比如是否为对称量化、是否是均匀量化、是否per-tensor/channel)
- 算法间采用了不同的训练设置,有些算法可能有训练上额外的优势
- DoReFa-Net:

- 先压缩到[0, 1]范围内再量化W与A(weight quantization/activation quantization就是压缩量化范围)
- Activation的处理由于经过ReLU(没有负半轴)再Clip到[0, 1],不需要复杂的变化
- 取值范围限制在[0, 1]太局限
- PACT:
- W量化方式与DoReFa一致,考虑到每一层对应activation的最优截断范围不一样,逐channel学最优的截断范围(将activation的范围从[0, 1]拓宽)
- 没有修改weight量化方式,是其不足
- QIL:
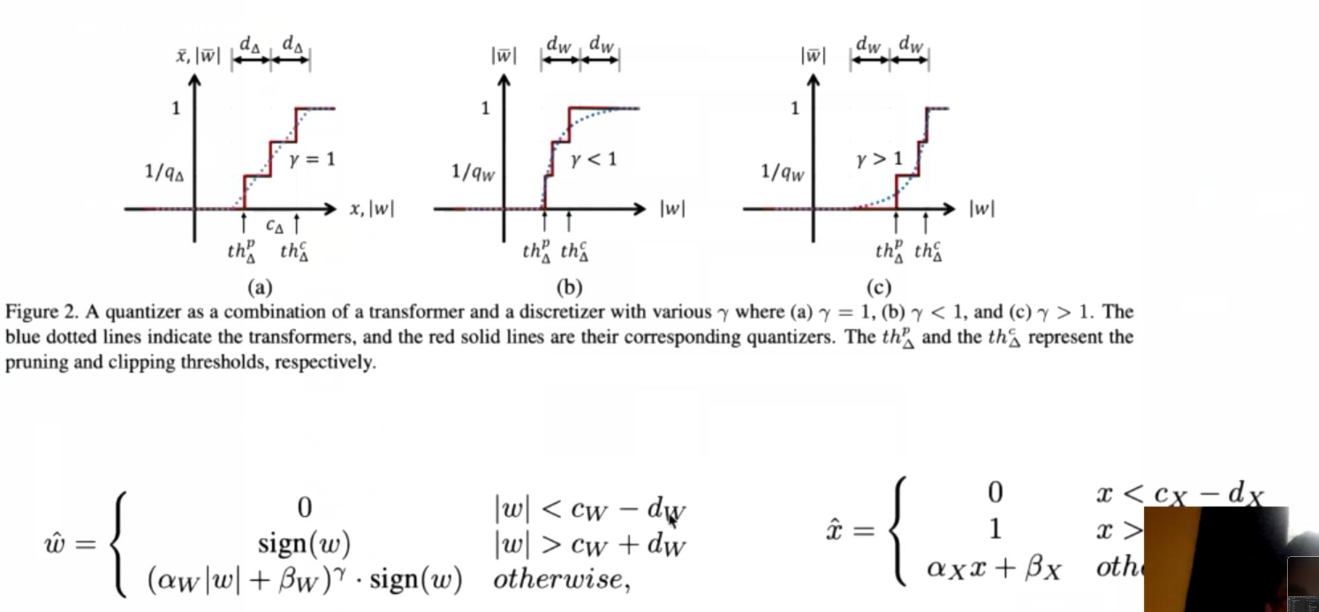
- 学习C_w(量化区间中心点)和D_w(量化区间半径),另外根据这两个参数计算\alpha_w和\beta_w(对应斜率和偏移)
- \gamma在指数位上,表示非均匀量化,实际上学不出来会训崩,复现的时候也没加\gamma,本来意义可能也不大
- LSQ:
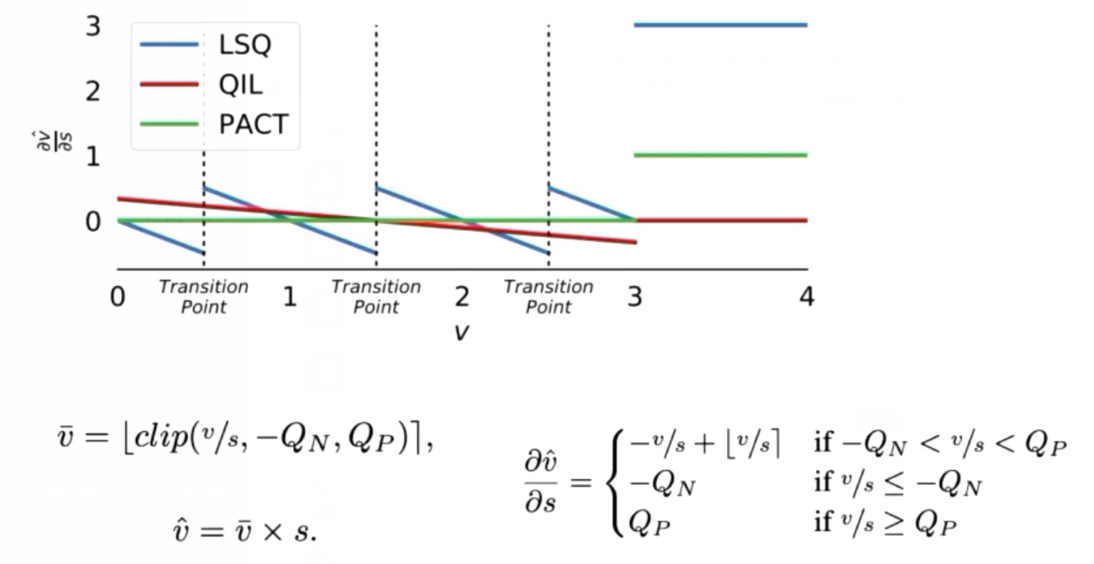
- 改变了求scale/stepsize的导数的范围
可部署的量化感知训练
- 总结了学术设置和可部署量化模型之间的区别:
- 量化函数配置不一致:学术论文普遍采用per-tensor, symmetric的量化函数,而不同的硬件有自己的量化函数配置;一些量化算法在per-channel的情况下表现不佳;学术量化认为A的量化是无符号的,硬件中只有有符号量化(浪费1bit)
- 激活值量化插入点不同:学术量化只考虑量化卷积层,不考虑element-wise加等
- 没折叠BN
-
硬件后端设置:

- FBGEMM是服务器上CPU的?
- TVM POT -> 2次幂 scale -> 级数加法/移位 -> 减少乘法
- 对称量化更快(没有零点偏移,只是乘)
- 非对称量化可以改成无符号量化
- 模拟量化(软件仿真)和硬件量化计算图:
- 模拟量化(Fake Quantization):
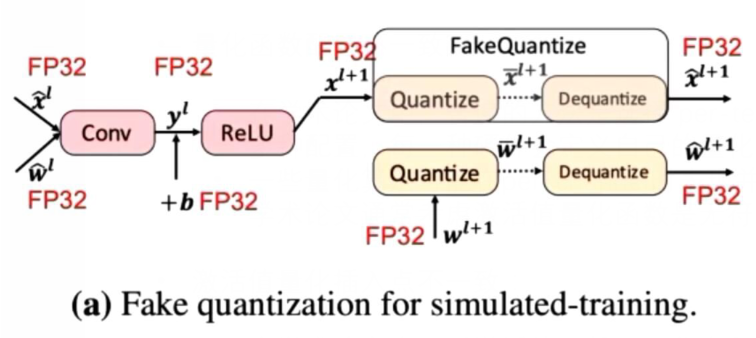
- 硬件量化:
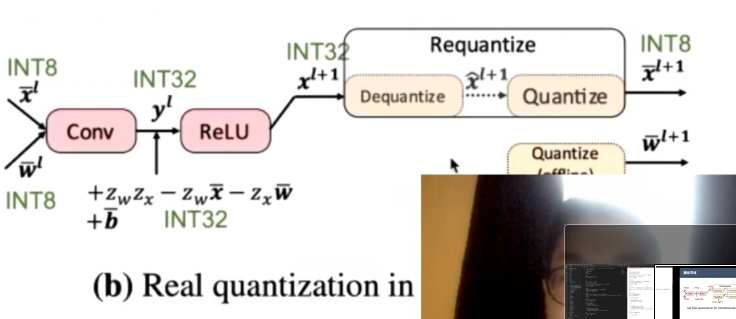
- x_hat虽然是FP32,但是是离散取值
- 真实量化需要重新计算scale所以要先dequantize,但实际上只有requantize一步,不会拆成去量化和量化两步
- 模拟量化(Fake Quantization):
-
量化节点的区别:
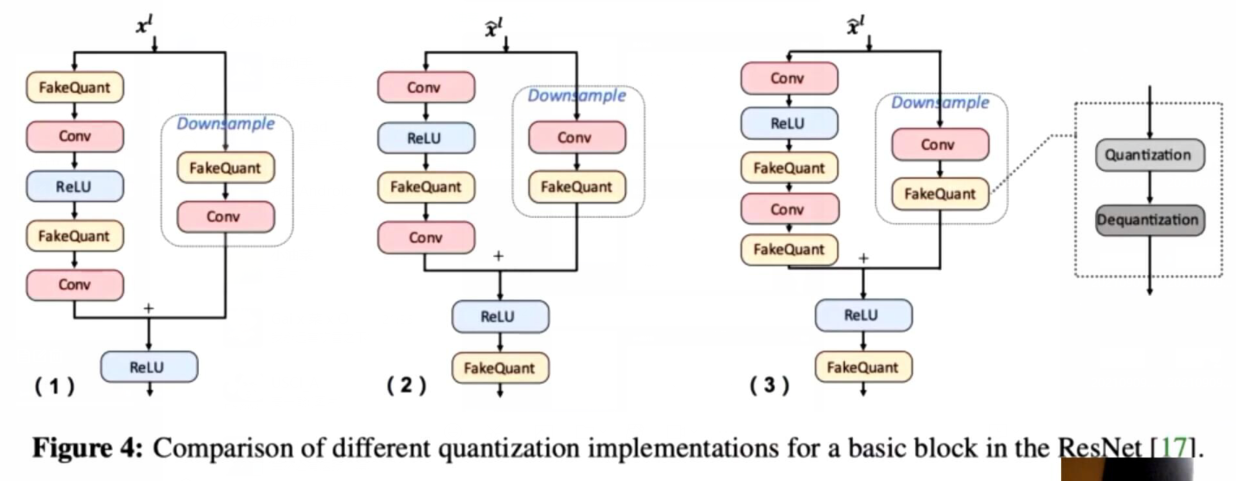
- (1)是学术设置,只保证参与卷积运算的参数与激活值是定点的,element-wise以全精度计算;这种方法很慢,比如在shortcut和normal path中要独立量化两次,无加速效果;
- (2)(3)方法区别在于加法前是否量化,(3)更通用
- tensorRT -> (2);ACL -> (1)(非通用平台); 其他的->(3)
- BN折叠策略的区别:
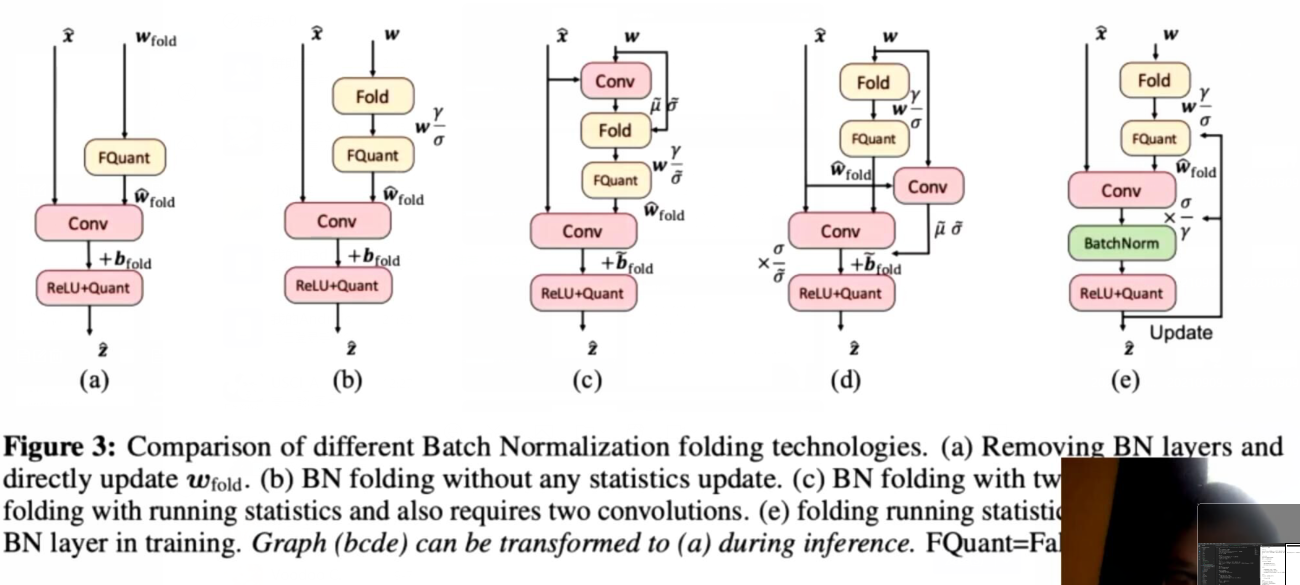
- (1)直接fold进Conv,调优时没有BN
- (2)不更新BN统计量,fold之后调优时继续优化affine参数
- (3)google 两次卷积 第一次计算更新统计量 再折叠进Conv 再量化
- (4)google 第一次卷积计算移动统计量,fold时统计量抖动较少
- (5)pytorch官方 反乘折叠系数 推理时可以消掉插入的BN
可复现的量化感知训练
- 部分学术论文无法复现精度的原因有:
- 没开源
- 训练配置不一样(预训练的全精度模型训练程度不同、不同lr schedule、不同batch size与训练时长、不同wd、etc.)
- 软件库发展
模型量化标准集(MQBench)
- MQBench统一配置与预训练模型,消除训练偏差(具体设置不关心)
- 实验结果一(没截到图),统一学术训练设置,4-bit QAT,结果差距非常小,在ResNet-50上效果更明显/5个模型4个最优解 -> 不同算法差距不大&更好的训练配置导致结果差异;MQBench没有方差分析,有的话差距应该更小。
- 实验结果二,对齐硬件后端的设置,4-bit QAT,算法不分好坏,有好有坏,也没有最坏的,小结论:
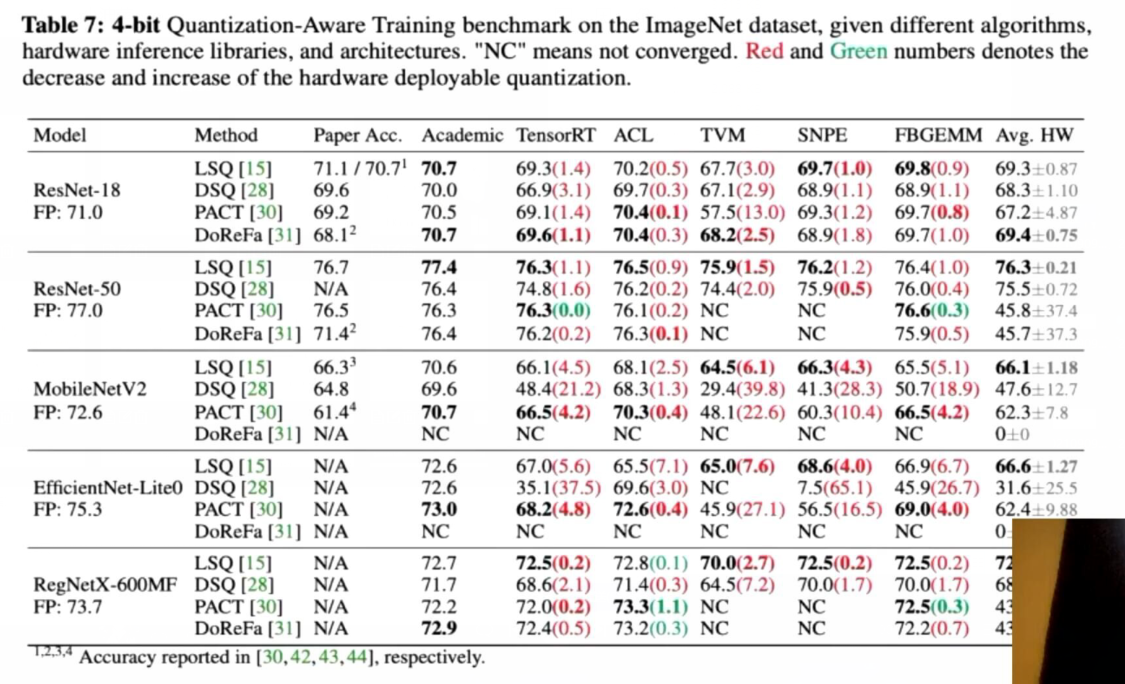
- PACT->对per channel友好
- LSQ -> per tensor友好 但是在per channel中不太好
- DoReFa也不差,训崩了可能是[0, 1]范围的问题 -> rule-based与learning based差不多
- 对齐硬件之后和学术设置下结果差距很大,基本上会掉点
- 实验结果三,BN折叠:

- BN折叠会影响量化算法的效果
- 右上角带*表示异步统计量,即不同步分布式训练中BN层的统计量 -> 显著影响性能,因为BN会fold进Conv层,不同步会导致weight不同
Q&A
- LSQ/LSQ+按照论文里不能部署,需要手动调整
- 硬件量化集成为requantize,而不会有dequantize和quantize
- swish/hardswish实际上不好用,ReLU好用
- 学术上几乎没有做检测分割的,baseline比较少,任务也挺难
- github还会更新,以及doc
- softmax的量化在NLP中有, Q-bert有量化
- NLP transformer可以部署,CV transformer量化做的人还少