Bayesian Optimized 1-Bit CNNs
2021/5/14
来源:ICCV2019
resource:github上备份的包括ipad标注的pdf版本。
作者是厦大纪荣嵘组的(但是感觉写得不太…不太行?反正不喜欢)。
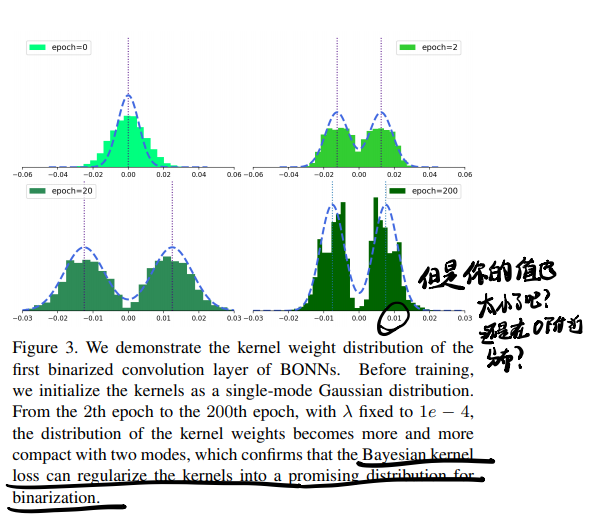
Summary:文章挺一般的,完全看不出来启发点。不是,你凭什么觉得分布应该是在以正负两个量化值为mode的GMM分布?而且残差为什么服从均值为0的正态分布?而且你实际做出来的量化值/mode值也小得离谱啊?~0.01所以数据还是想分布在0附近不是吗?所以感觉你加的这个限制就是强行把weight掰到两边了呗?最后的结果也没多好啊?感觉就是在调点调上去的?
还是回到文章干了什么上来:作者在常规的cross entropy loss外加了两个bayesian loss,就构成了所谓的bayesian optimization,最后是把latent weights的分布拉成了在±binarized value两边的分布,最后ImgNet上的点只有59.4,很可疑。
这张图可以很清楚地显示本文做了什么:
Rating: 1.5/5.0
Comprehension: 2.5/5.0
文章的贡献有:
- 提出了两种bayesian loss(Bayesian kernel loss 和 Bayesian feature loss),对latent weights的分布进行了限制(诱导?),在loss项中结合上面两种loss引入新的正则项。
1 Introdution
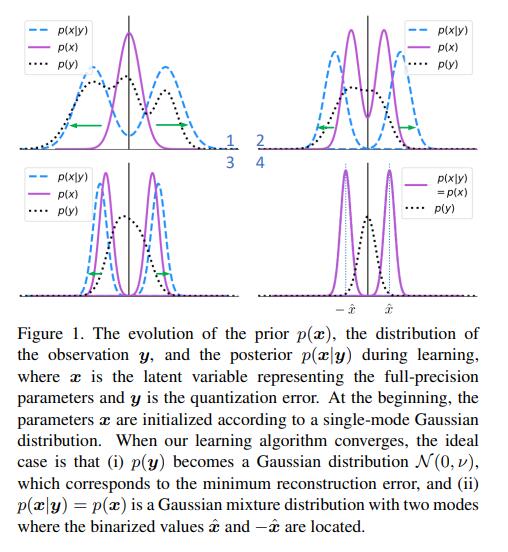
本文的核心论点:理想上当FP kernel服从以量化值为峰值的高斯混合模型时量化误差最小,所以对于BNN用两个峰分别在量化值的高斯混合模型来建模FP weight分布。
(所以从头到尾除了FC部分就没有关注过feature map的分布似乎->直接binarize activation)
Ideally, the quantization error is minimized when the full-precision kernels follow a Gaussian mixture model with each Gaussian
centered at each quantization value. Given two centers for 1-bit CNNs, two Gaussians forming the mixture model are employed to
model the full-precision kernels.
一些关于其他文章的"导读":
- DoReFa-Net似乎既低比特了weights也低比特了gradient
- ABC-Net似乎是用多个binary的weights和activations
2 Proposed Method
Bayesian kernel loss
这里量化的核心思路还是让量化前后的值尽可能地接近,因此也用了一个vector对量化后的x_hat作hadamard积:
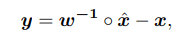
后面的描述就很奇怪了:对于一个y,我们找一个x_hat使得:
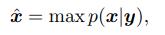
这表示在最可能的y下(对应y=0即x=w^(-1)○ x_hat,即上式移项,也就是最小重建错误)x的潜变量的分布是一个双峰高斯分布,峰值在量化值处。后面就是数学推导Bayesian kernel loss的形式。
Bayesian feature loss
这个loss的引入目的也很奇怪:"这种loss引入是为了减轻极端量化(binarize)引入的干扰,考虑到intra-class compactness(不懂),第m类的特征fm应该服从高斯分布,其均值cm revealed in the center loss"。
This loss is designed to alleviate the disturbance caused by the extreme quantization process in 1-bit CNNs. Considering the
intra-class compactness, the features fm of the mth class supposedly follow a Gaussian distribution with the mean cm as revealed in
the center loss.
后面把这两种loss结合到一块,可以看出来X和φ都是逐层逐kernel的,特别的,w_l是每层来的,和X_l中元素一一对应,训练的时候里面的元素也是分开训,但是前传的时候w_l退化成了一个scalar,值取w_l_i的均值。 φ_l_i也被简化成了值相同的对角矩阵。
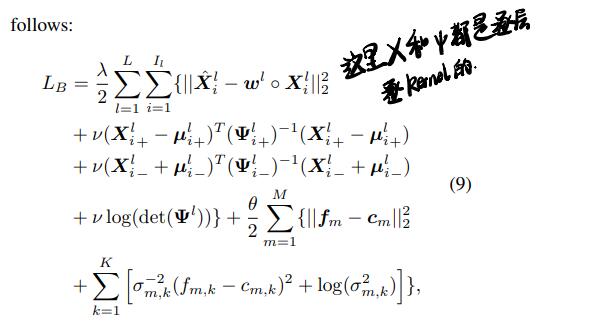
Backward Propagation
最后算法如下,可以看出来其实也就是引入了个新的正则项,加了点可训练的项目:

3 Experiments
持续减分:
- 第一层stem没有binarize(大家都这样,勉强吧)
- skip op / 1*1 conv没有binarize(你就是这样马马虎虎到海军学校的吗?)
- FC layer没有binarize
- 甚至没说downsample层有没有binarize
其中的一个结果,还是减分(值根本没跑多远好吧):