202605 Working Progress
By 2026/5/10
- StreamVLN短指令测试
- 现象梳理
- StreamVLN导航至画面里出现且距离较近的物体的成功率很不错!(体感~80%)
- StreamVLN具有一定的探索能力!在不正对房间门口的情况下,VLN会输出旋转命令,直到它找到门口,并可以正确输出从门口出去的动作序列!
- 问题梳理
- turn-around命令和底层控制器不是很match(其实是旋转角度和执行结果之间就一定gap,这个可以通过调整接口改进)
- StreamVLN在房间探索时(找到出口)会先往某个方向转120~180度,找不到出口就往另一个方向又转 120~180度 ,实际上会回到原来的方向,能不能让它在探索时固定旋转方向呢?
- 现象梳理
By 2026/5/31
- 搭建 Pi-0 SFT Pipeline
- TODOs
- 复现 openpi 中 Pi-0 在 libero 上的finetune pipeline(包括full & Lora)。
- 复现 Pi-0 的 serve & query 结果。
- [] 检查 Pi-0 模型实现和微调部位选择。
- [] 检查 Pi-0 模型微调的数据形式、数据预处理方式。
- 探索用四足狗数据微调 Pi-0 的思路(by GPT)
- 控制形式
- 目前在 Isaac Sim 中跑起来的 M20 的控制器的控制形式:VLN输出文本形式的运动指令,脚本将文本控制指令解析成本体运动增量,并进一步换算成[vx, vy, wz]与持续时间(NaVILA),或直接输出[vx, vy, wz]与持续时间(StreamVLN)。机身目标速度、本体状态(包括机器人机体系下的重力方向projected_gravity、机器人 base 在机体系下的角速度base_ang_vel、关节位置joint_pos、关节速度joint_vel、上一帧传给环境的 action,这些参数是直接从 Isaac Lab 环境里的 robot state buffer 读出来的 observation,或是上一轮 PPO policy 输出并经过 wrapper/action manager 接收的动作)作为PPO policy的输入,输出 12 个腿部关节 + 4 个轮子关节的目标位置/速度(腿部关节对应位置目标/姿态目标,轮子关节对应速度目标)。Isaac Lab 的 action manager 会将分别对 12 个腿部关节设置 position target,对 4 个轮子关节设置 velocity target,最后 Isaac Lab 把这些 target 写入 robot articulation,底层 actuator/PD controller 再在物理仿真里驱动关节。
- (优先)控制方案1:输出 12 个关节的目标位置或目标位置增量,然后下面接一个稳定的 PD 控制器。和目前仿真环境中实现的版本非常接近,且更加稳定。
控制方案2:输出 12 个关节的目标速度。- 控制方案3:输出机身速度([vx, vy, wz])+ 持续时间,等效取代了 NaVILA / StreamVLN,训练难度或许更低,但是和我们想要的直接到关节的控制还有gap。(也是Miao博现在采用的策略)
- 优劣比较:直接让 VLA 输出 12 个关节速度,问题会比较多。速度需要积分成位置,长期执行容易漂移;而且四足机器人对相位、触地、姿态稳定非常敏感,关节速度稍微不稳定就可能摔倒。输出目标关节位置或相对于当前姿态/默认步态的 offset,通常更安全、更容易加限制。
- 层次建议:如果已经有一个成熟的 RL locomotion policy,GPT更建议让 Pi-0 作为高层或中层控制器,而不是直接替代底层控制。也就是说,Pi-0 可以输出
[vx, vy, yaw_rate]或者前进 / 左转 / 右转 / 停止 / 上台阶 / 绕障命令,再交给已有的低层四足控制器。如果坚持输出 12 关节姿态,GPT建议把它定位成"中低层动作生成器",但底层一定要保留 PD、限幅、姿态保护和紧急停止。
- 控制输入 可考虑的输入包括:
- 本体状态(proprioception):
- (方案1,作废)
12 个关节角 q、12 个关节速度 dq、IMU 姿态/角速度、机身线速度或里程计估计、(如果有)足端接触状态、(如果使用周期步态)当前 gait phase。 - (方案2,对齐到PPO Policy的输入)机体系角速度 base_ang_vel(3) 、机体系重力方向 projected_gravity(3) 、关节位置 joint_pos(16) 、关节速度 joint_vel(16) 共38维,此外,还有历史执行动作(n * 16,根据控制频率取~10)。由于Pi-0的状态输入维度只有32,这些本体状态需要通过一个新增的 adapter 映射到 Pi-0 的状态输入空间。
- (方案1,作废)
- 前视照片 + 底部鱼眼相机照片。
- 语言导航指令。
- 本体状态(proprioception):
- 控制频率 & 采样频率
- Isaac Sim中物理仿真积分步长为0.005s,PPO policy的一个动作输出持续 4 仿真步长,对应控制频率为 50Hz 。
- Pi-0 在双卡 3090 服务器上的推理延时大约是 130ms:
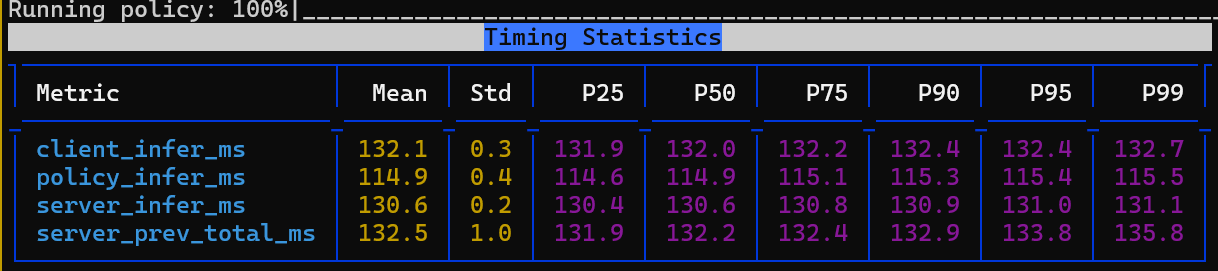
- 目前设计的输出控制频率是,action trunk中每个动作的持续时间为 0.02s (50Hz),Pi-0每次推理输出 32 个动作(对应时间长度为 $32 * 0.02 = 0.64s$),每次取前 16 个动作作控制($16 * 0.02 = 0.32s$),后续可测试更高频率的推理,取 8~12 个动作作控制($8 * 0.02 = 0.16s$)。
- (NOTE)需注意图像帧、关节状态和 action 的采样时刻,避免数据不匹配。
- 数据采集
- 前向相机和底部鱼眼相机最好固定分辨率、固定内参和固定安装位置。鱼眼图像建议做一致的预处理:要么一直使用原始鱼眼,要么一直做去畸变,不要训练和部署不一致。底部鱼眼看到四足和地面,图像变化会很剧烈,如果没有足够数据,模型可能过拟合到某些腿部外观或光照条件。
- 或许需要短期历史帧或状态历史。
- 安全性 & 注意事项
- 不要让模型直接输出无限制关节速度或力矩。所有输出必须经过限幅,包括关节角范围、速度范围、动作变化率、机身姿态阈值和足端高度限制。
- 训练动作最好归一化。每个关节单独统计 mean/std 或 min/max,训练时归一化,部署时反归一化。
- 部署时只执行 action chunk 的前一小段,然后重新推理。
- 保留 emergency stop 和 fall detection。比如 IMU 检测 roll/pitch 超阈值,或者关节误差过大,就立刻切换到安全模式。
- 微调阶段设计
- Stage1:输出 base velocity 或关节目标位置增量,并接稳定低层控制器;
- Stage2:局部控制稳定后,再逐步加入语言长程导航和记忆机制。
- 微调梯度大小
- 可行性分析
让模型直接从这类语言和图像输出每个关节下一秒怎么动,相当于让一个模型同时学会语义导航、局部避障、路径规划、步态生成和稳定控制,难度很高
更好的分层形式是,语言 + 前向图像 → 高层导航意图 / 局部目标 / base velocity;base velocity + proprioception → 低层四足控制器 → 12 关节目标。
如果想用 Pi-0 做端到端,建议至少把训练数据里的语言指令细化到局部动作级别(向前走 1 米、慢速左转、跨过前方低障碍)
- 控制形式
- TODOs
- 检查Isaac Sim中的仿真时间
- 仿真时间与物理时间是两回事。理想中的仿真频率(后文中的RL step)是 50Hz ,但实际上打时间戳算出来的(物理世界)频率只有 20 Hz,在这种情况下,仿真世界的1秒钟等于物理世界的2.5秒。反过来说,GPU需要花2.5秒的时间,才能把仿真环境的1秒算完。在视觉上会出现仿真被慢放、帧数较低的效果。
- 仿真物理量和图像的对应关系。脚本中设置的 Isaac Sim 仿真的最小单元(physics tick,或者说是物理仿真积分步长,dt)为0.005s,也就是 200Hz,这个量是各个仿真物理量的最小积分单元,各个仿真物理量也是以这个单位更新的(在仿真世界,对应0.005s更新一次,对应到物理时间,大约0.0125s,更新的内容包括积分位置/速度/接触/约束)。在当前脚本中,PPO Policy产生控制信号(RL step)的间隔是 $4 * dt$,这个 4 也是手工指定的,仿真世界的频率为 50Hz ,对应物理世界的频率大约为 20 Hz。在一次 PPO Policy 控制的间隔中,各个仿真物理量被更新 4 次。图像更新频率 / 渲染频率也是手工指定的,目前脚本中将渲染频率和PPO Policy控制频率对齐了,也就是对应 4 个dt。所以,理论上仿真物理量的变化频率是控制频率的 4 倍,在采数时需要把它对齐到RL step。
- 当前脚本中一次RL step对应的变化。一步RL step中发生的事件包括:PPO policy 输出 action -> action 被写入机器人控制器 -> Isaac Sim 连续推进 4 个 physics tick(仿真时间,tick 1: +0.005s,tick 2: +0.010s,tick 3: +0.015s,tick 4: +0.020s,仿真时间总共前进 0.02s) -> 触发一次渲染/viewport 更新/图形管线刷新 -> 更新 scene/robot/sensor 数据缓存 -> 产生新的observation。物理量的组织形式主要在 Isaac Lab 的 scene / asset data buffer 里,例如
env.unwrapped.scene["robot"].data.root_pos_w、env.unwrapped.scene["robot"].data.joint_pos。