Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational Capability and Advanced Training Algorithm
2021/2/28
来源:2018ECCV
resource:自己收录了一下。
作者是Hong Kong University of Science and Technology的Zechun Liu,ReActNet也是她的作品,太强了。
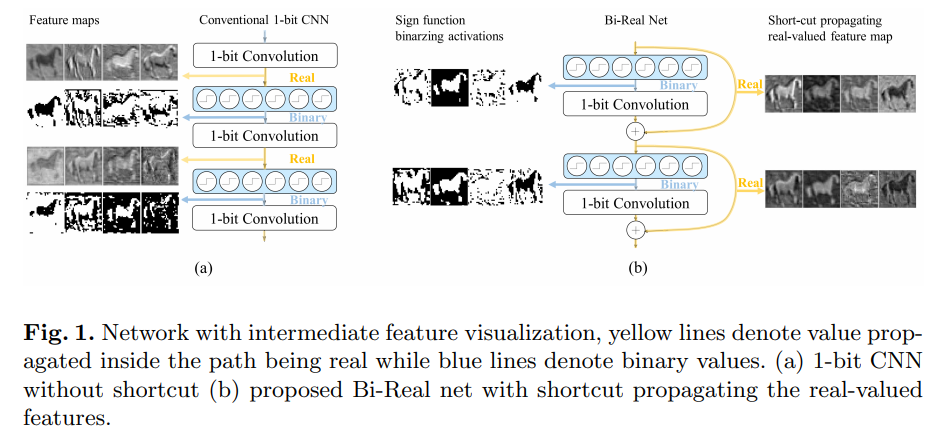
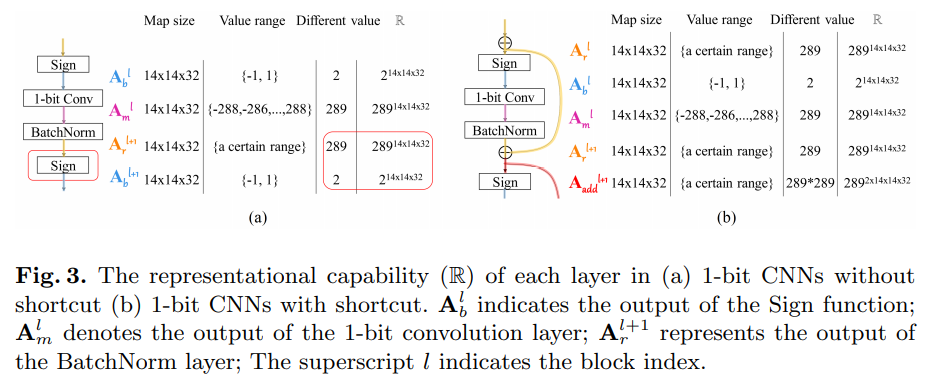
Insight:作者观察到在inference阶段,binary conv层产生整数输出,如果后面紧跟着BN层,这个输出会进一步变成real values。但是这些real values会被sigh函数二值化为−1 / +1,导致信息损失。因此想到通过一个shortcut保留这些信息,也就是文中提出的Bi-Real结构:
Contributions:
- 结构方面,作者提出了Bi-Real block结构,在原来的
Sigh-Conv-BN的基础上block-wisely引入shortcut(当前block的输入在sigh之前引出,和当前block的输出element-wise相加作为下一block的输入):
- 作者提了三项训练方面的tricks:
- 提出了一种piecewise polynomial function作为sigh函数导数的近似,取代传统的clip函数:

原文图3-sigh函数导数的近似 具体的形式是:
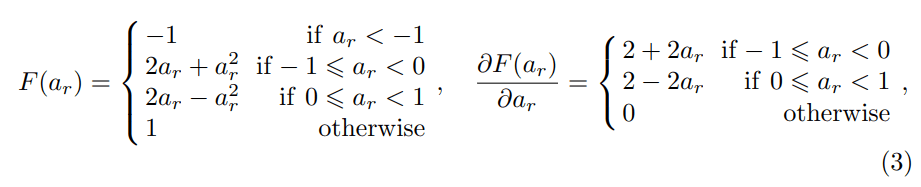
原文图4-该近似的数学形式 -
认为之前的基于real-valued更新的梯度只考虑了weights的符号,没有用到其绝对值大小,提出了一种Magnitude-aware gradient。有复杂的数学推导(矩阵求导),没懂。
-
之前基于pre-trained model的训练方法,对应的预训练的模型使用了ReLU func,而它的激活值是非负的,和sigh的输出−1 / +1有较大差别,因此用clip函数取代ReLU进行pre-train。
- 提出了一种piecewise polynomial function作为sigh函数导数的近似,取代传统的clip函数:
Results:略
2021/3/1 update:
details:
- 没有对weights & activations使用scaling factor(inference阶段)以节约FLOP和memory。(原文P14 Part5前)