Fast and Memory-Efficient Network Towards Efficient Image Super-Resolution
2022/5/26
来源:NTIRE22
resource:github上备份的包括ipad标注的pdf版本。
作者是南大的Zongcai Du, Ding Liu, Jie Liu, Jie Tang, Gangshan Wu, Lean Fu,没听说过呢。
Summary:指出LLCV中feature fusion的设计资源消耗大。在Sequential(区别于multi-branch or multi-scale)backbone上设计了两个高效建构模块。
- 具体而言,local feature fusion的问题在于:
- 需要占据内存,内存开销大;
- 需要额外计算节点,例如concate或者conv 1 x 1
- Local SC设计访存频率高
Key words:
- memory optimization
- efficient architecture design
Rating: 3.5/5.0 一般,无聊的模块设计,但是局部跳连的故事有点意思。
Comprehension: 4.5/5.0 挺好懂。
- Inspirations:
- (LLCV)effciency设计的要点在于利用有限的feature组合出更representative特征。
- (LLCV)既然Sequential模型可以取得很好的性能-效率trade-off,multi-scale的设计真的必要吗?
- (更大的优化空间)除了global skip connection,local skip connection(ResBlock、DenseBlock)消耗的内存多,访存频繁,也有优化的必要。
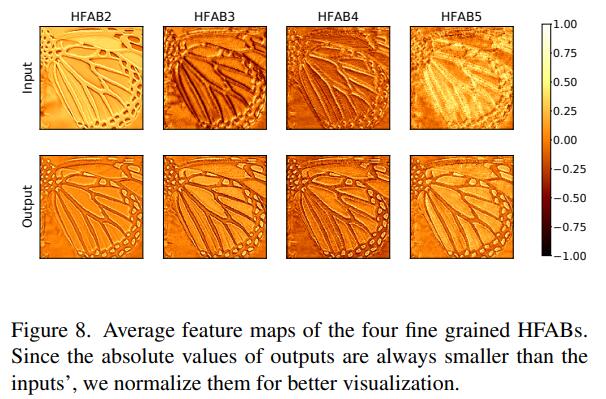
- (方法上的启发)* 可用 torch.cuda.max memory allocated 分析内存开销 * Feature 高频分析的图很好看(也很占地方)
Insight
- Local sc内存消耗大,且访存更频繁:
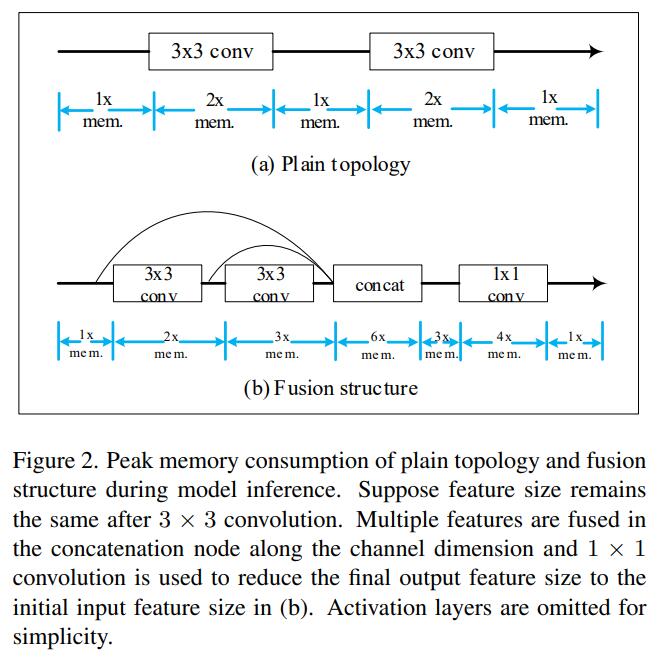
- Local SC对延时的影响很小,完全取消所有local sc(EDSR baseline),延时改善非常有限:

Methods
搭积木。
- Sequential Backbone
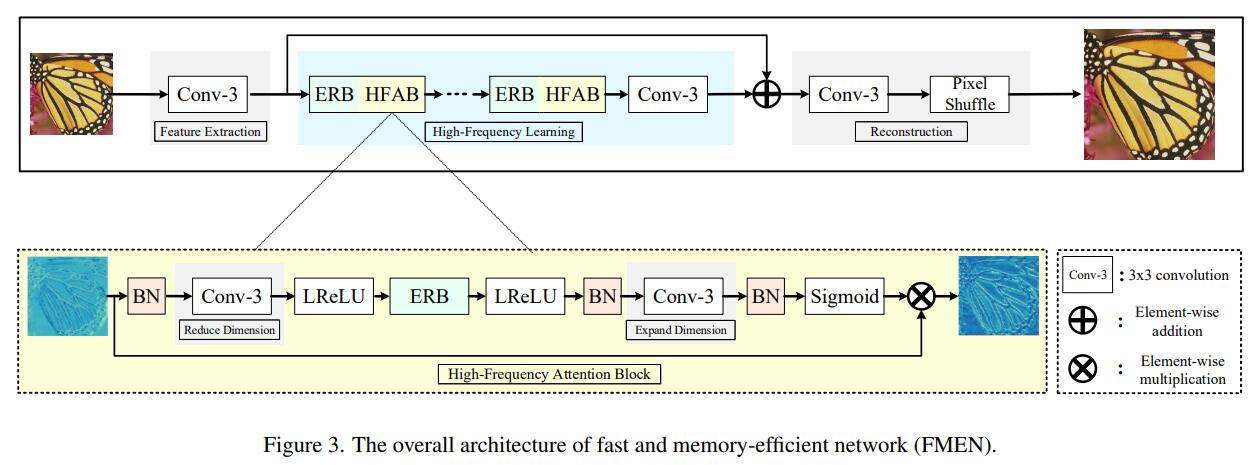
-
基本构建块 ERB(Enhanced Residual Block)
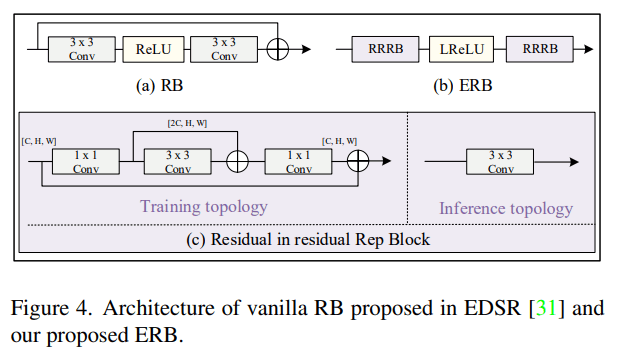
- 使用re-parameterization的方法取消local跳连
-
增强高频信息HFAB(High-Frequency Attention Block)
- Pixel attention增强高频信息
Results
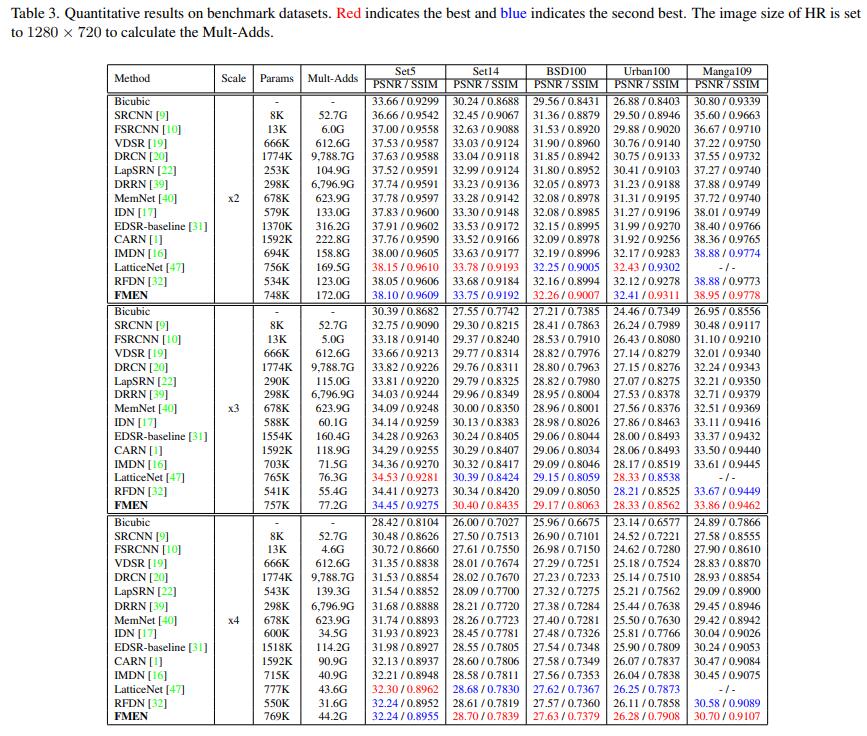
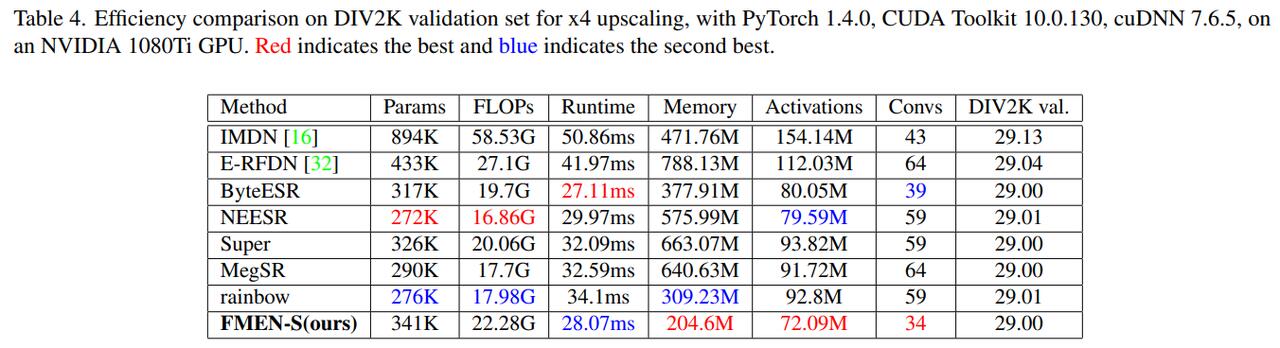
经典任务性能大表格 + 可视化 + 高效性能表格:
- 任务大表格
- 可视化

- 高效表格
- Ablation里有个很好看的高频分析: