Attentive Fine-Grained Structured Sparsity for Image Restoration
2022/5/23
来源:CVPR22
resource:github上备份的包括ipad标注的pdf版本。
作者是首尔大学的Junghun Oh, Heewon Kim, Seungjun Nah, Cheeun Hong, Jonghyun Choi, Kyoung Mu Lee等人,话说Kyoung Mu Lee这个B也太能水了吧。
Summary:A+B了个M:N剪枝;用不同剪枝比例的模型拼出一个dynamic patch inference flow。具体来讲,将1:M的参数tensor(幅值排序)作为基本的剪枝单元,用STE训一个channel-wise的binary mask(大于阈值取1,小于阈值取0),将mask作为约束项进行训练。
Key words:
- N:M pruning
- dynamic patch inference
Rating: 2.8/5.0 一般,就一普通A+B LLCV+pruning,倒是做了很多实验。
Comprehension: 4.5/5.0 挺好懂。
- 一张图总结全文:
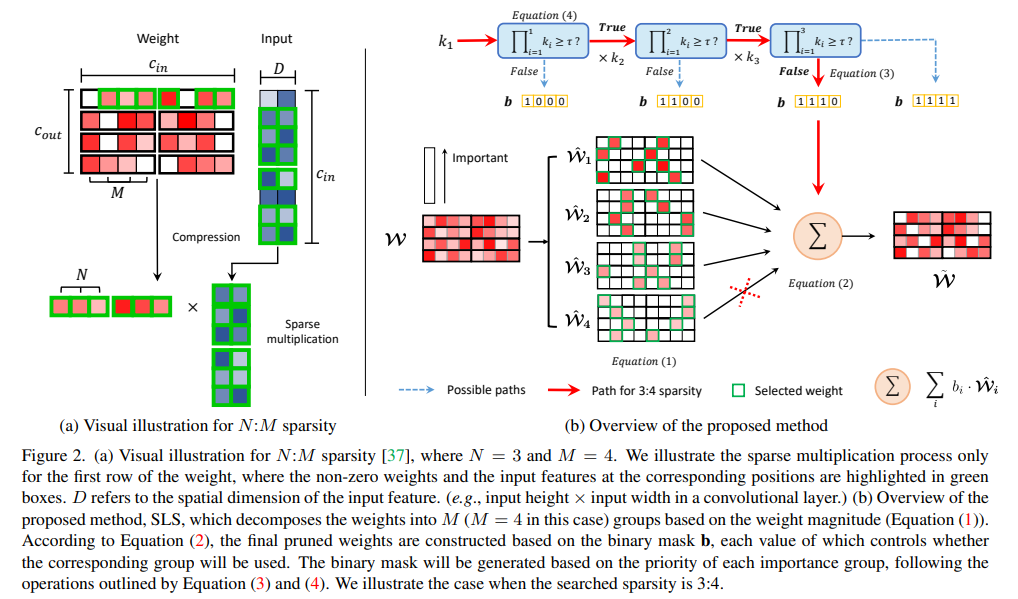
Preliminary
- N:M剪枝
- 结构化剪枝和非结构化剪枝的一种中间态?
- 细粒度剪枝(√),通用GPU加速(√)
- 剪输入feature(等效剪参数/剪输出feature?),将计算节约至N:M
- 结构化剪枝和非结构化剪枝的一种中间态?
Methods
- N:M pruning
- 将 1:M参数作为剪枝的单元,由一个mask决定该单位(这个通道)的参数是否保留
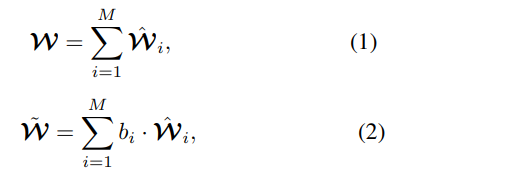
-
(经典瞎说) In the case of N:M sparsity pattern, however, it is challenging to determine such structural units because there are many possible configurations for preserving N weights out of M weights. -
使用STE训练这个binary mask(latent mask大于阈值取1,反之取0)

- 初始参数的权重用于分组,为避免大幅值参数先于小幅值参数被剪去,利用Priority-Ordered Pruning"保证剪枝顺序,先剪小幅值通道:

-
但是有个问题,如果有的通道在训练中被训小了呢?/原始的大小关系被打破了?(没有回答)
-
将mask作为约束训练,直到硬性约束满足,再拿掉正则项finetune:

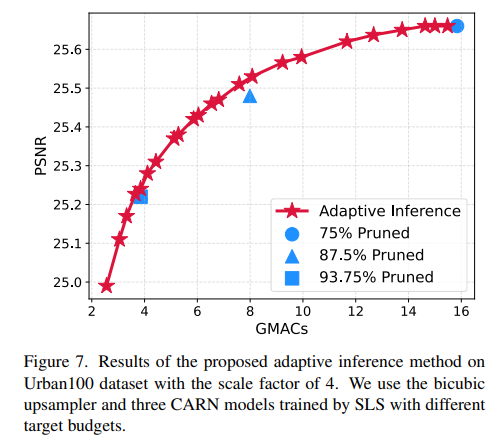
- Adaptive Inference
- 相当于ensemble方法,每个ensemble对象都是剪枝比例不同的网络,根据patch的难度和消耗的计算资源做trade-off
- (MSE Estimator)对于每个剪枝网络训练一个轻型CNN,估计还原出来的图像和GT之间的MSE分数
- 利用下式+调超参确定性能-效率 trade-off:

- 最后可以实现灵活权衡的inference
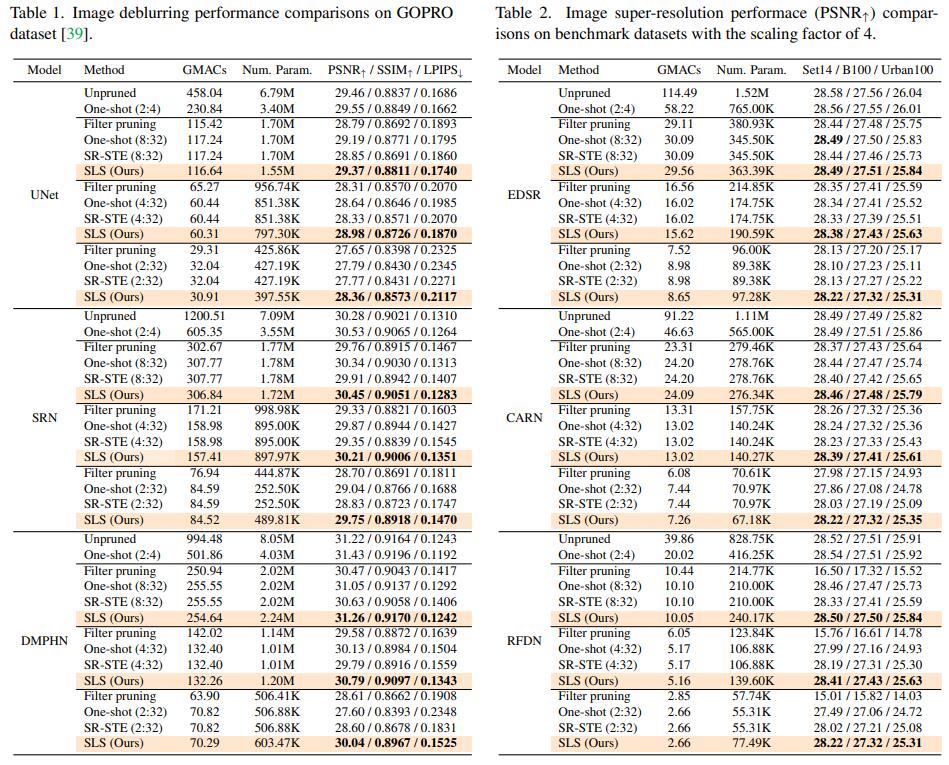
Results
-
Extensive实验,Deblur + SR两个任务,每个任务各做三个模型,比较不同方法: