Binarized Neural Network for Single Image Super Resolution
2021/6/10
来源:ECCV2020 resource:github上备份的包括ipad标注的pdf版本。
作者是西电的Jingwei Xin, Nannan Wang, Xinrui Jiang, Jie Li, Heng Huang, Xinbo Gao等人,不认识呢。
Summary:第一篇把BNN的概念引入SR的文章(灌水?),具体不好判断怎么样。文章提出了一种BAM(bit-accumulation mechanism)算法,将不同层的weights和activations分别加权加在一起,通过BN再取sign作为量化的weights和activations(见鬼了,这能work?也没解释这么做的动机啊?)。这种BAM方法似乎可以直接去改SR的一些baseline。这篇文章还提出了一种SR model building block,这种block搭出来的网络比直接BAM一些baseline效果更好些。总之读起来是一篇抢坑的水文(更别说文中还有"ass"这种拼写错误了,怎么回事)
Rating: 3.0/5.0
Comprehension: 4.0/5.0
1 Introdution
有一些关于Super Resolution的知识:
- SR中已经采用了Residual Learning、Recursive Learning、Skip Connection、Channel Attention等学习策略和模型结构。
- SR文章报菜名:SRCNN、Sparse Coding Network (SCN)、VDSR、SRDenseNet、EDSR、RDN、RCAN。
- 为了用更少的参数取得更好的效果,使用残差块,相关工作有:DRCN、DRRN、MemNet;还有减少推断时间的设计:FSRCNN、ESPCN、CARN、ODE。
3 Proposed Approach
3.1 Motivation
现有的基于深度神经网络的SISR方法的处理过程可以分成三个阶段:特征提取(feature extraction)、非线性映射(nonlinear mapping)和图像重建(image reconstruction)。用公示表示成:
其中\(\mathcal{R}\)、\(\mathcal{M}\)和\(\mathcal{E}\)分别表示上文所述的图像重建(通常是一层Conv)、非线性映射(通常是级联的Conv)和特征提取(一层Conv),x和y分别是输入的低分辨率图像和输出的高精度图像。\(\mathcal{M}\)的结构直接影响了整个网络的性能和参数(复杂度)。
这一部分还提了一些点:
- 对\(\mathcal{M}\)的量化可以极大地减少存储空间消耗和计算资源开销,后文就是对这一部分进行量化的,最前面的Conv和最后一层Conv保持全精度,和BNN一致。
- 说对weights和activations的scaling factor不好使,但是不清楚是直接照搬了BNN的结论,还是在SR任务上进行了测试,后文实际上用了某种scaling factor,但是是求解/学习出来的。
3.2 Quantization of Weights
计算当前层binary weights的方法是,用几个\(\alpha\)加权之前层的weights(这里的加权方法是按元素乘系数,然后量化的部分只有\(\mathcal{M}\),这一部分的网络通道数一致,所以"+"也是按元素加),通过BN(为什么要过BN…)后取符号,再用逐层用全精度参数的均值绝对值加权。
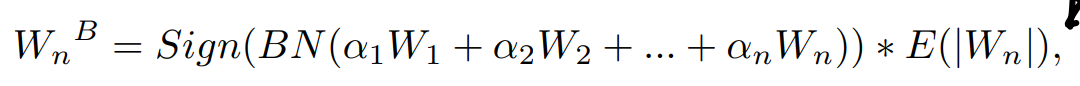
至于式中的\(\alpha\),按照后面algo的描述并不是可训练的(activation累加时的参数\(\beta\)才是可训练的),这里只是求解出来的(解这个优化问题应该相当费时间?):
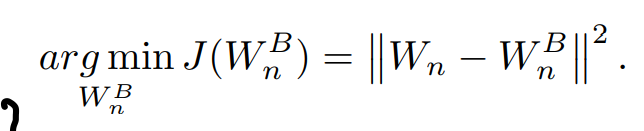
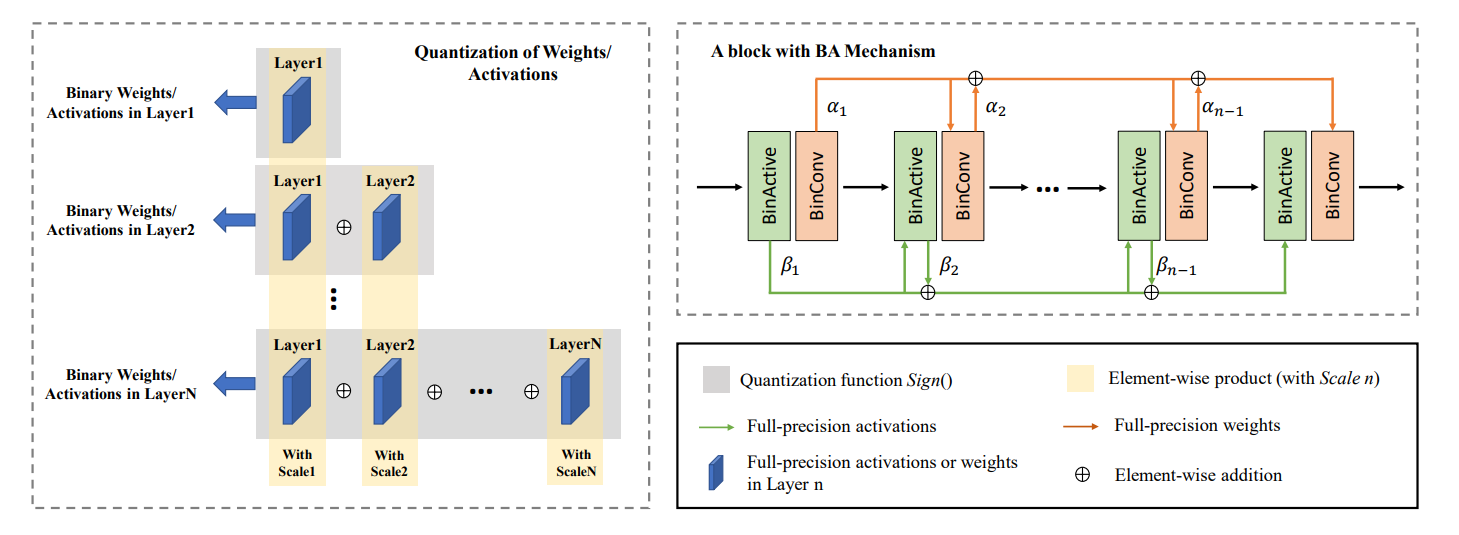
BAM算法,画得是相当抽象:
3.3 Quantization of Activations
对Activation的处理和weight的差不多:
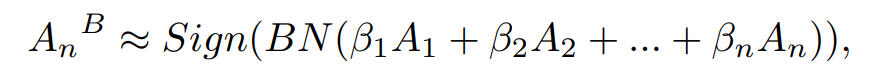
作者argue超分模型对图像的处理对中间activation的依赖很强,所以这里不用单一scale(对应weight的 \(E(\|W_n\|)\) ),而是用一种(可学习)two-dimensional array来scale activation:
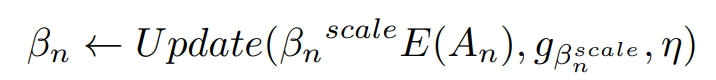
式中的\(\beta_n^{scale}\)是个scale factor而且只有它在训练的时候可以被更新(我想应该是相对\(\alpha\)说的)。
最后整体的BAM算法是:

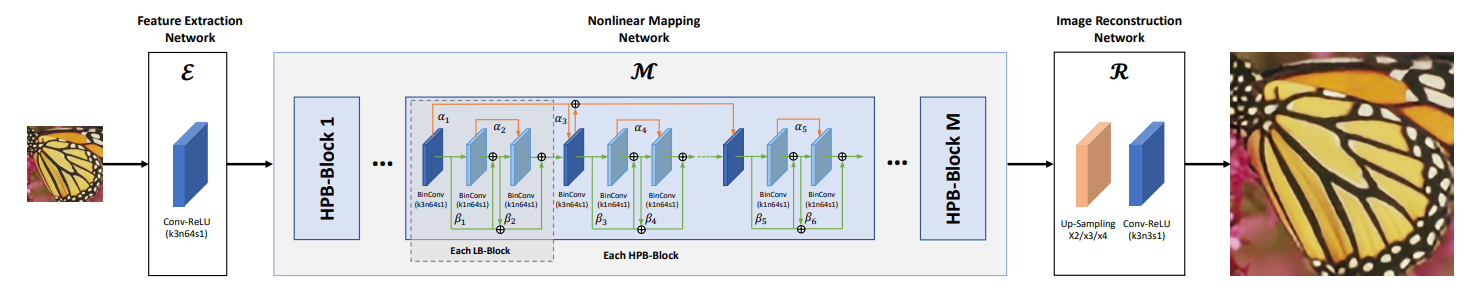
3.4 Binary Super Resolution Network
构造了个high-precision binarization (HPB) block作为这种SR model \(\mathcal{M}\)的building block:单个HPB block是由多个LB-block堆叠成的,每个LB-block由1个3x3 Conv和2个1x1 Conv组成(所以weight accumulation是在kernel一致的filter之间进行的,activation accumulation看图好像是不在3x3 Conv两侧进行,也就是文中所说的short-range accumulation&long-range accumulation)。
整体的网络结构如下所示:
4 Experiments
4.1 Datasets
两篇文章用的数据集好像挺一致,所以这是SR领域的通用设置吗?
- 训练集是DIV2K,由800张训练数据、100张验证数据和100张测试数据组成。
- 测试集是Set5、Set14、BSD100和Urban100。
- 输入LR图片是bicubic x2、x3、x4降采样HR图片产生的。
4.2 Implementations
Data augmentation、Batch size、optimizer等相关设置。
4.3 Evaluation
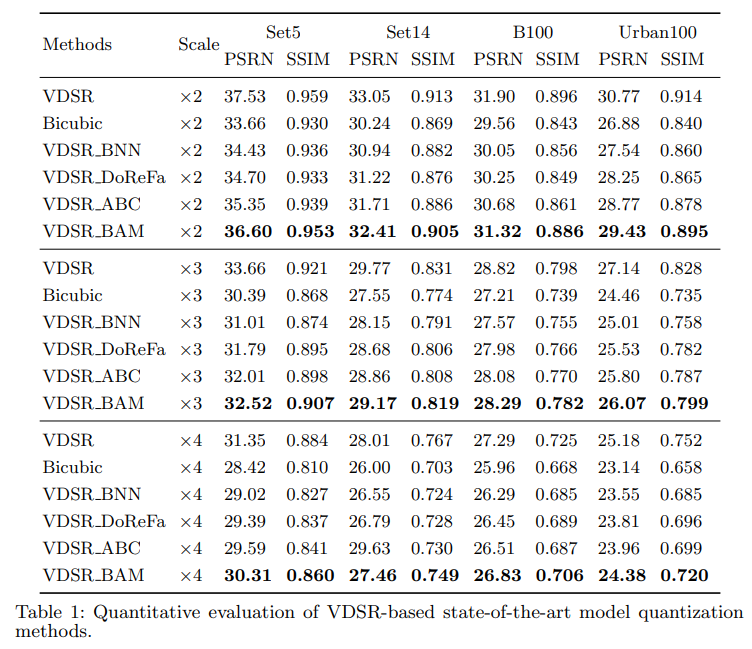
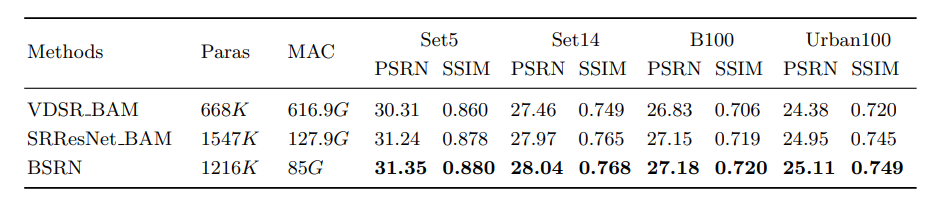
现在好像需要关注实验结果了。有三组结果,分别是用BAM在VDSR、SRResNet这两个传统SR model上的结果和BAM+BSRN的结果。
- VDSR实验结果:
- SRResNet实验结果:
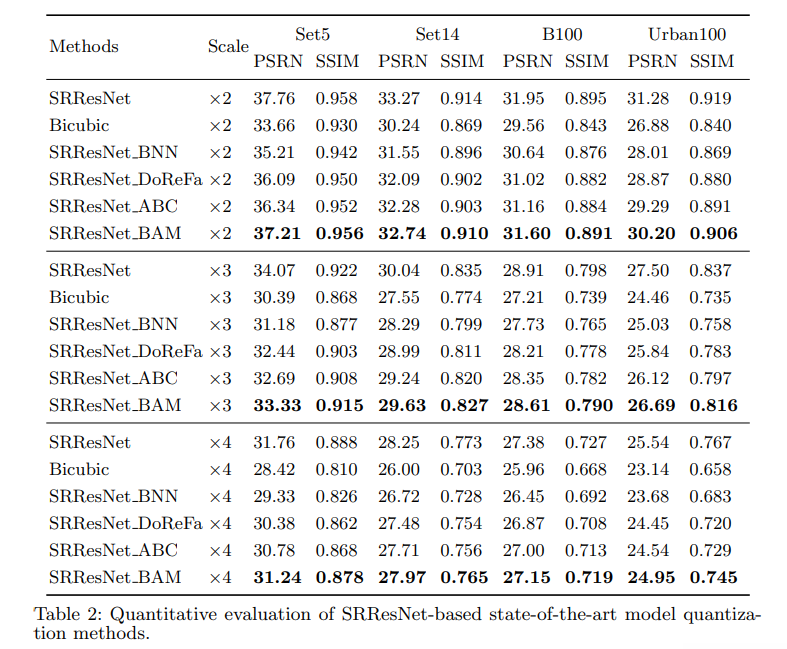
作者在比较VDSR和SRResNet实验结果的时候对模型结构有些阐发:SRResNet上的量化结果好于VDSR的原因有,SRResNet用的这种残差块的非线性映射能力要强于VDSR的(而且参数数量多),同时结构中的skip connection降低了反传梯度上的难度,也丰富了信息流。
把几张图拎出来比较的吹B写法可以学学,我是看不太出来图之间有什么区别,就嗯吹。
- BAM + BSRN实验结果:
- 消融实验说明了bit accumulation的效果要比中间的系数更重要一些:想不明白,这种不同layer参数按元素相加为什么会有用呢?