Deep Learning on Image Denoising An overview
2021/7/13
来源:不知名杂志?这玩意写得也很不行啊。
resource:github上备份的包括ipad标注的pdf版本。
作者是哈工大博士Chunwei Tian。
Summary:比之前那篇辣鸡综述稍微好点的,感觉也就是篇扩写,重点放在了加性白噪声上,参考价值仍然很低。九折也好意思找人宣传??
rating:2.0/5.0
comprehension:4.0/5.0
文章的贡献有:
- 一些进阶的background knowledge,但是参考价值很低(不过部分表格看起来还可以)。
1 Introduction
传统方法报菜名:
- sparse-based methods
- a non-locally centralized sparse representation (NCSR) method used nonlocal self-similarity to optimize the sparse method( Nonlocally centralized sparse representation for image restoration, TIP12)
- To reduce the computational cost, a dictionary learning method was used to quickly filter the noise(Image denoising via sparse and redundant representations over learned dictionaries, TIP06)
- To recover the detailed information of the latent clean image, priori knowledge (i.e. total variation regularization) can smooth the noisy image to deal with the corrupted image(An iterative regularization method for total variation based image restoration. Multiscale Modeling & Simulation 4 (2), 460–489.)
- Markov random field (MRF)
- cascade of shrinkage fields(Shrinkage fields for effective image restoration, CVPR14)
- weighted nuclear norm minimization(WNNM, Weighted nuclear norm minimization with application to image denoising, CVPR14)
- learned simultaneous sparse coding(LSSC, learned simultaneous sparse coding,ICCV09)
- trainable nonlinear reaction diffusion(TNRD, Trainable nonlinear reaction diffusion: A flexible framework for fast and effective image restoration. IEEE transactions on pattern analysis and machine intelligence 39 (6), 1256–1272)
- gradient histogram estimation and preservation(GHEP, Gradient histogram estimation and preservation for texture enhanced image denoising, TIP14)
但是它们有这三个问题:
- 测试阶段有复杂的优化;
- 需要手工设置参数;
- 一个模型对应一个去噪问题。
2 Foundation frameworks of deep learning methods for image denoising
问题也不给个好好的数学定义,实在太拉了:
\[y = x + \mu\]一大堆nonsense,但是GAN的入门介绍稍微还可以看一下:
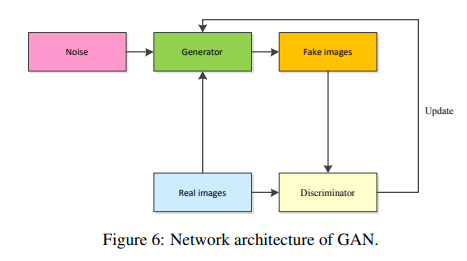
Generative Adversarial Networks (GAN) was developed based on this reason. The GAN had two networks: generative
and discriminative networks. The generative network (also referred to as generator) is used to generate
samples, according to input samples. The other network (also as well as discriminator) is used to judge
truth of both input samples and generated samples. Two networks are adversarial. It is noted that if the
discriminator can accurately distinguish real samples and generate samples from generator, the trained model is
regarded to finishing. The network architecture of the GAN can be seen in Fig. 6. Due to the strong ability of
constructing supplement training samples, the GAN is very effective for small sample tasks, such as
face recognition and complex noisy image denoising.
3 Deep learning techniques in image denoising
也就分类有点用。
3.1 Deep learning techniques for additive white noisy-image denoising
因为缺少真实数据,早期人们用人工合成的加性白噪声图片(additive white noisy images, AWNI)训练模型,AWNI包括Gaussian, Poisson, Salt, Pepper和multiplicative noisy images。
- CNN/NN for AWNI denoising(纯NN的方法)
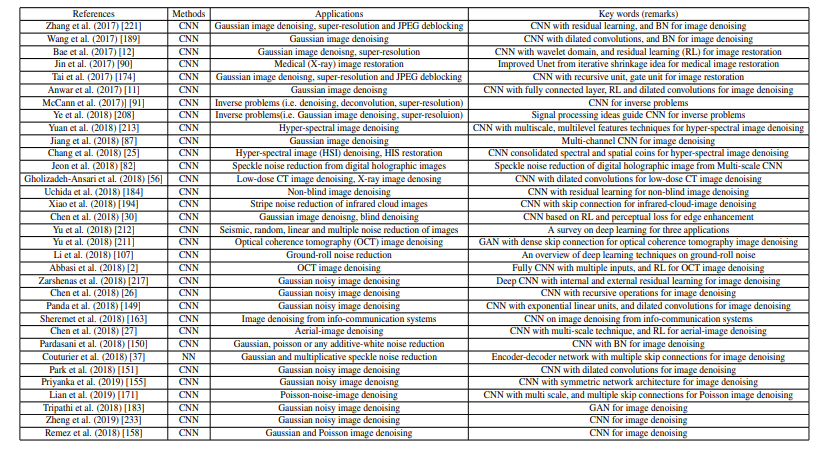
改变网络结构有以下的思路:
-
- fusing features from multiple inputs of a CNN
- different parts of one sample as multiple inputs from different networks
- Different perspectives for the one sample as input, such as multiple scales
- Different channels of a CNN as input
- Changing the loss function
- characteristic of nature images to extract more robust features, e.g. jointed Euclidean and perceptual loss functions
- Increasing depth or width of the CNN
- Adding some auxiliary plug-ins into CNNs
- activation function, dilated convolution, fully connected layer, pooling operations, etc.
- Using skip connections or cascade operations into CNNs
- fusing features from multiple inputs of a CNN
- CNN/NN and common feature extraction methods for AWNI denoising(和特征提取结合的NN方法)
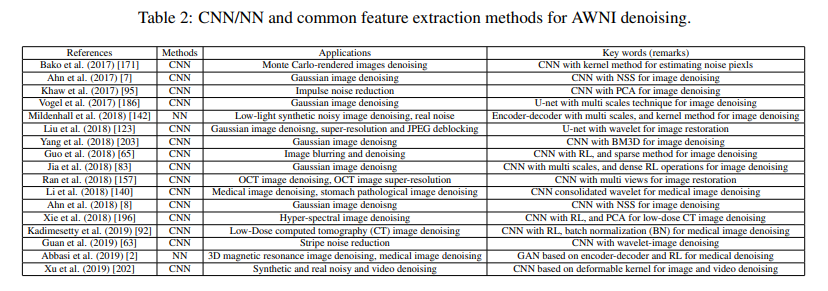
-
- weak edge-information noisy images
- CNN with transformation domain method
- non-linear noisy images
- CNN with kernel method(分为三步,第一步用CNN提特征,第二步用核方法把非线性特征转换成线性特征,第三步重建图像)
- high dimensional noisy images
- CNN + dimensional reduction method(也是三步,第一步用CNN提特征,第二步用PCA等方法降维,第三步重建图像)
- non-salient noisy images
- CNN + signal processing idea(e.g. skip connection)
- high computational cost tasks
- CNN + nature of image
- weak edge-information noisy images
- The combination of optimization method and CNN/NN for AWNI denoising
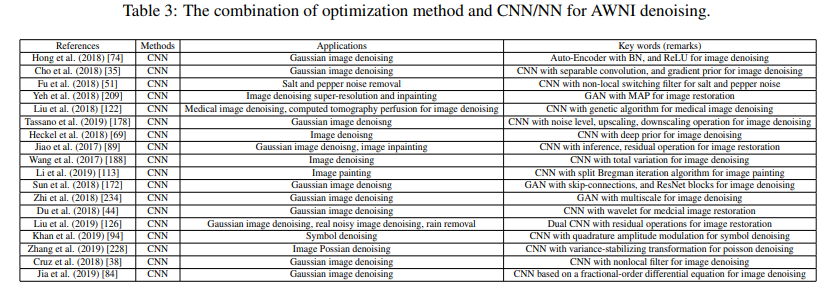
optimization methods(不清楚到底指什么,可能是传统方法?)在low-level vision方面表现不错,但是需要手工调参非常费时;discriminative learning methods(同样指代不明,麻了,就不能不介绍模型多讲讲这两个的定义吗啊)速度快,但是不够灵活,这两者结合在一起可以trade-off。
-
- improving denoising speed:CNN + optimization method(e.g. MAP)
- improving the denoising performance
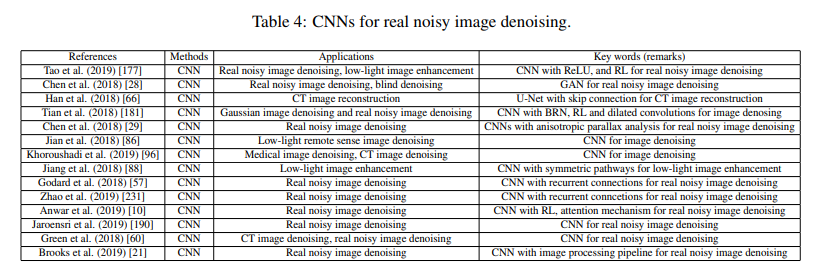
3.2 Deep learning techniques for real noisy image denoising
- single end-to-end CNN
- combination of prior knowledge and CNN
3.3 Deep learning techniques for blind denoising
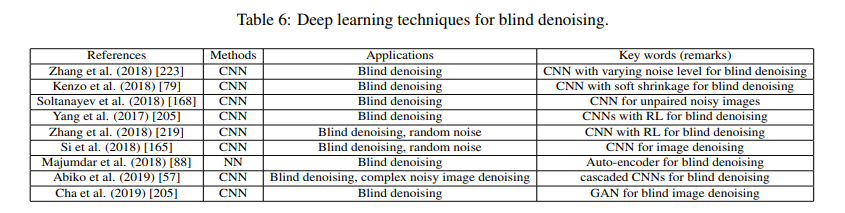
3.4 Deep learning techniques for hybrid noisy image denoising

4 Experimental results
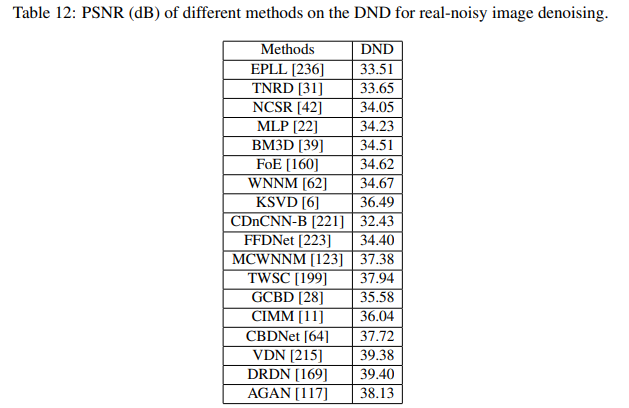
一些dataset上的测试结果:
- DND上benchmark
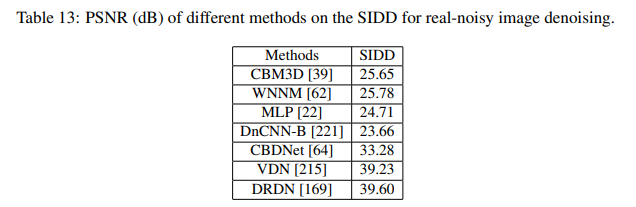
- SIDD上benchmark
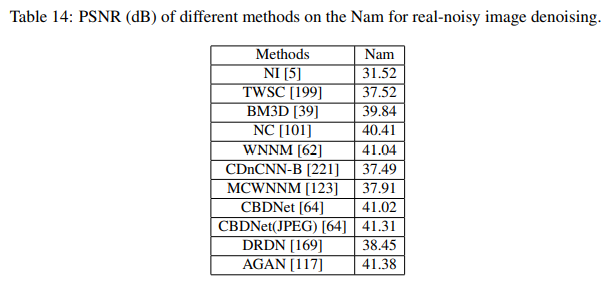
- Nam上benchmark
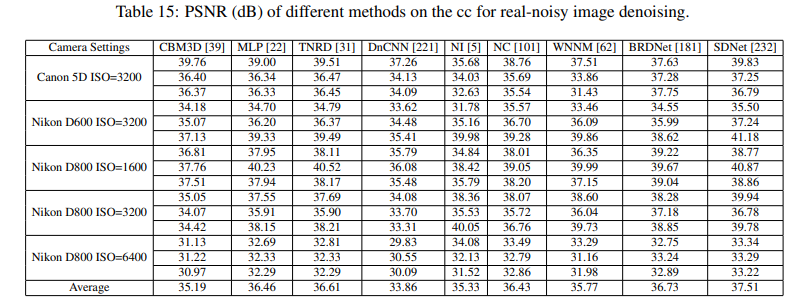
- cc上benchmark