202604 Working Progress
By 2026/4/5
验证模块的设计思路(持续迭代中):
- 设计的宏观思路:
- 流程层面示意图如下:
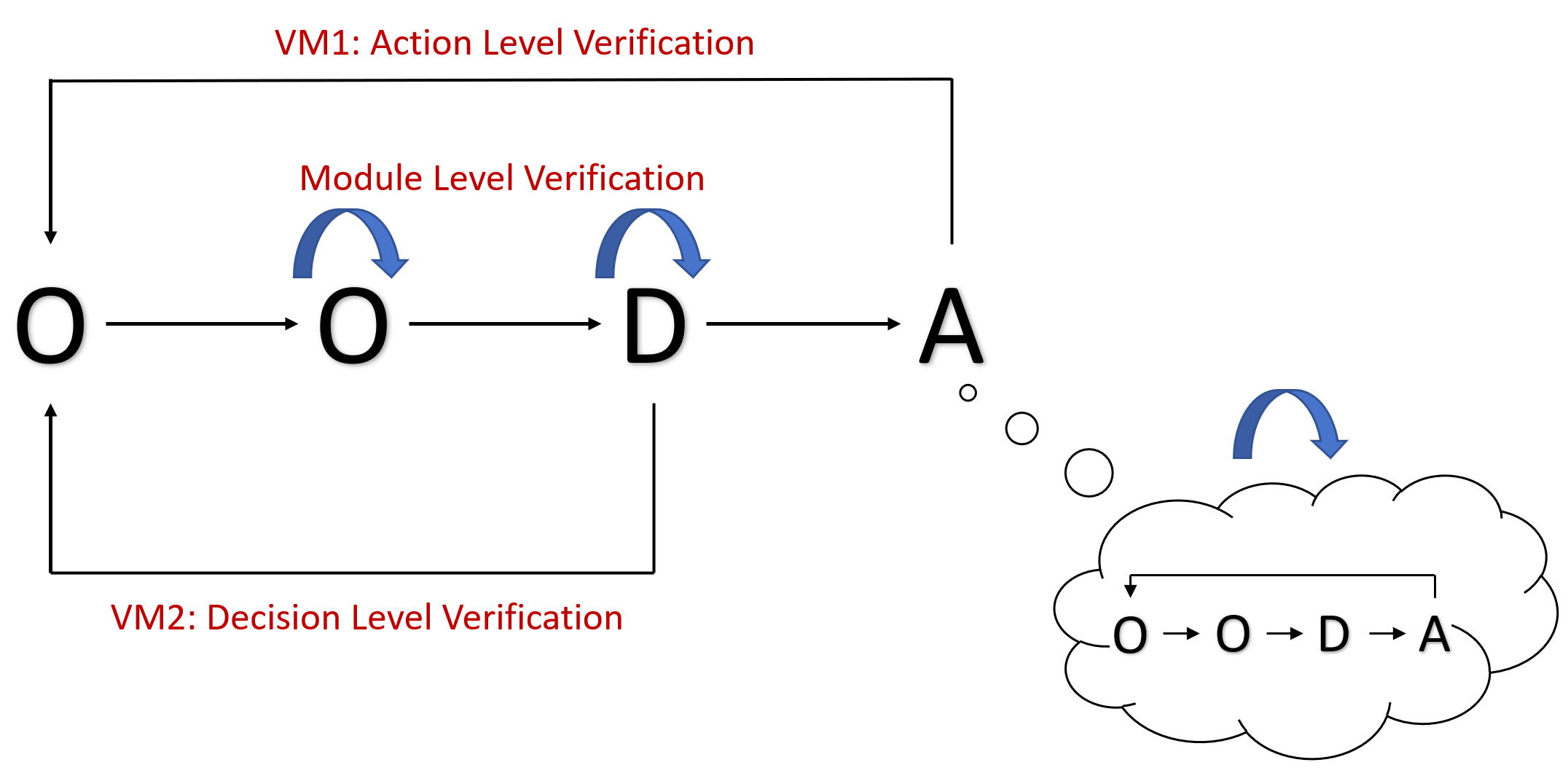
- 模块层面示意图如下:
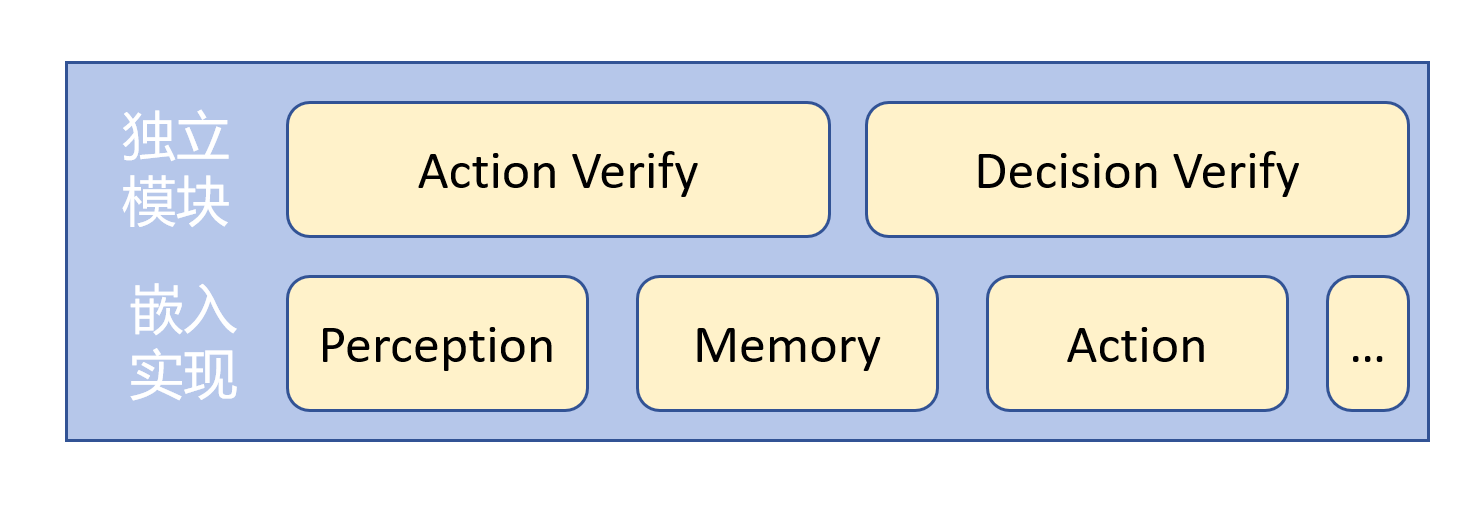
- 按照独立模块 + 嵌入验证的方法组织整体的验证模块。对于流程中的重要环节(任务执行闭环、任务规划闭环),应设计专门的模块负责验证。该模块主要包括一些抽象类,对验证输入输出、验证行为等进行一定抽象(在应用中,实例化该模块的具体实现并挂载到agent上,在流程关键环节调用该实例并做控制)。对于流程中的关键步骤,应在对应模块的实现中增加含有验证的版本,早发现早治疗。
- 可以按照大流程 + 小环节的思路考虑验证对象:
- 在大流程(OODA)方面,需要关注两个层次的验证:① OODA的闭环情况(Action->同循环的Observe),验证当前的能满足本轮循环一开始的观察直到决策层面的目标(即验证行为是否满足需求);② OOD的(Observe->Orient->Decision),验证基于当前的观察与系统状态,agent制定的plan是否合理(即验证规划)。
- 在小环节方面,框架中各个模块可以内置具体的、带有验证的实现。例如,在agent做reasoning的时候,可以设控制条件(如果是关键步骤)的同源twice-thinking机制,提高agent对即将采取的行为的把握程度;又如,在做memretrieval的时候,也可以设计对memory内容的反思 + double-retrieval之类的机制,减少hallucination的情况;又如,可以修改action模块,对action的结果做一步验证,确保action已按照self-claimed的结果完成。即验证关键步是否正确;
- 模块输入输出:模块输入基本对齐至待验证环节/模块的输入,包括总体任务规划、当前任务步骤、当前环境信息与本体状态、输入图像、来自记忆的上下文等;此外,还可设法由历史执行结果中获取一定验证经验,用于指导当前步骤的验证。输出为对于任务执行/规划的状态评价(文本信息)或实际流程控制信号(tool calling等,终止或重复当前步骤)。
- …
- 流程层面示意图如下:
- 具体的设计原则:
- 分层验证,即上述"独立模块+嵌入验证"的思路;
- 分级验证,对于不同重要程度的模块按照不同的力度来验证,实现验证(执行正确性)与执行效率的权衡;可设计不同的验证水平,在不同水平下,不同的验证模块具有不同的验证行为。
- …
- 可采取的设计选项:
- 自我反思 + 第三方验证的验证形式;
- 在基本的
react迭代循环中引入reflection环节,让LLM/VLM自己反思循环中的问题; - 在流程中某些关键位置引入基于其他模型的复核机制,避免self-claim;
- 在基本的
- 离线 + 在线结合的验证形式;
- 离线:offline policy learning, prompt engineering, etc.
- 在线:通过流程编排动态判断规划、执行等情况,并进行流程控制;
- 基于推理 + 基于证据 并存的验证形式;
- 基于推理:根据LLM/VLM reasoning的方式进行验证;
- 基于证据:将执行中的artifacts作为依据,用以增强LLM推理,提高可信度;
- …
- 自我反思 + 第三方验证的验证形式;
- 工作进展:
- 在dimos里接入VLN,目前可实现"LLM下发导航指令 -> VLN接收导航query + 当前1张相机图像,生成导航原子动作 -> 解析原子动作并操控机器狗"的链路了。
- 存在问题1:目前是单指令控制,仅做VLN接入流程验证(说一句话动一下),还没能实现任务闭环(说一句话,VLN做若干次动作规划,直到任务完成);
- 存在问题2:VLN的能力似乎有些弱(每次输出的指令都非常像,基本都是向前走xx cm),暂时没确定是VLN真的弱,还是现在的调用方式有问题(
NaVILA官方脚本一次性传入8张图像给VLN,目前受到显存的限制,仅传入1张图像)。
- 在dimos里接入VLN,目前可实现"LLM下发导航指令 -> VLN接收导航query + 当前1张相机图像,生成导航原子动作 -> 解析原子动作并操控机器狗"的链路了。
By 2026/4/12
- 实现在isaac sim/lab中接入云深处M20机器狗资产,并完成底层控制器训练。在底层运控的基础上封装一层原子动作,目前可在isaac sim医院环境中加载M20机器狗资产,并通过命令行交互控制机器狗运动。在机器狗身上绑定相机,捕获第一人称环境信息。接入dummy VLN控制流程,实现闭环控制。
- 在isaac sim中迭代VLN控制:
- 实现VLN复杂控制指令(并且具有多张图像拍摄+多轮迭代的能力),完成了一个VLN控制机器狗爬楼梯的demo。
By 2026/4/19
- VLN表现
- NaVILA表现出了一定的场景探索能力,如让它寻找画面中不存在的物体时,它会旋转、前进,看起来似乎是在探索场景,但是更像是一头无头苍蝇(只用图像序列且没有完善的提示词、没有历史执行记录效果很差,几乎可以说没有什么记忆)。
- 几乎可以完成一次长程的上楼梯控制(8f + 高渲染;32f时又会原地打转),但是在上楼梯的时候还是会输出转向的指令,尤其是快到顶的时候,会频繁触发左转>右转>左转的循环,或许是视角的问题?
- 目前VLN控制存在很大的问题:
- Q1 - summary: 以下问题已通过对齐serve设置 + 模板部分解决。
VLN很蠢,在Isaac Sim中,哪怕图像序列很大,VLN经常输出原地转圈的命令,或者一直往前走(哪怕已经抵到墙面上了)的命令。这个情况经常发生在场景中没有要找的物体的时候。在场景中有要找的物体的时候,则会有另一种情形:VLN看到目标物体就立马停止,而不考虑离它还有多远;又或者,VLN会一直输出前进的命令(此时已经和物体接触了)。
- Q2 - NaVILA对历史信息的利用很差(表现为会反复执行历史上已经执行的命令,或者转了一圈而不自知),而且会有卡在一个地方的情况(已经顶到墙上了,但是就在那重复执行同样的命令,比如向前走75cm,其实也很好理解,观测+query不变,输出的动作自然很可能一样)。
- Q3 - 当机器狗面对一面全反射的玻璃墙时,无论让它导航到哪里它都认为自己已经到了目的地。
- Q1 - summary: 以下问题已通过对齐serve设置 + 模板部分解决。
- 目前做过的尝试:
- (Q1)调低仿真质量,对齐到以前有比较好的导航结果的设置。
- 无改变,VLN还是原地转圈。
- (Q1)检查传输给VLN的query,确认图像序列和prompt。
- 确认了图像序列,图像选择逻辑是正确的;确认了图像内容,反归一化后的图像是正常的(但是,图像分布本身会不会和NaVILA的训练分布不一致?);
- 确认了prompt,文本内容是正确的,但是推理的时候是将图像stack成了一个多batch的tensor,不知道这个图像该怎么和prompt对应。(prompt里只留了一个图像占位符)。
- (Q1)尝试在输入prompt中加入动作限制,例如"不能连续执行三次转弯",
- 发现NaVILA几乎没有指令跟随能力,该转还是转。
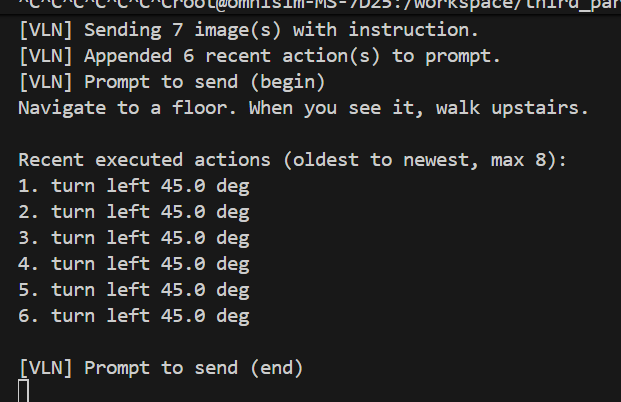
- (Q1)在prompt中追加已执行的动作队列。
- 实现的方式是,记录最近的8个动作,作为prompt的追加部分一起喂给VLN;
- 没用。动作模式有一定改变,以前是原地顺着一个方向转圈,现在是原地转圈,但是会换个方向转了(一会往左一会往右)。
- 很可能是因为训练的时候没见过这种提示词,VLM没办法利用这个信息。
- (Q1)改造出来一个基于VLM(Kimi-2.5)的导航模型。
- Kimi-2.5也会在全反射的镜子前停止;
- Kimi-2.5基本上不具有导航能力,它似乎只会输出前进命令(目前的prompt对齐了NaVILA的,而且也传输了8张历史图像+最近8次历史动作);
- 还经常报429 engine overloaded错误。
- (Q1)(怀疑)VLN的输入图像真的越多越好吗?NaVILA有能力处理好这种长序列上下文吗?
- 当最长图像序列为1时,导航效果显著优于图像序列为32的情况。(因为后者不是在撞墙就是在原地打转,虽然单张图像的成功率体感只有20%-30%,但好歹也有成功的例子)此外,8f的效果与1f的差不多。
- 进一步发现,目前使用的ckpt是 8f SFT(8-frame) 的,所以序列长(32/64)了效果不好也情有可原?(原文中的表格有8f与64f两种情况,64f的纸面效果优于8f,但是没有开源)
- 检查VLM serve服务,发现和NaVILA的不同之处仅在于,NaVILA固定输入8张图像的序列,如果图像不足则补全黑帧,我们是变长输入。
- [] (Q3)利用VLM丰富历史信息,例如给历史图像打个标签。
- [] 是不是现在的prompt内容和NaVILA的实现不一样导致的gap?
- 我们的测试用例:"Navigate to a floor." (沿用自dimos的导航模块,简短的"to object"指令,object还不在画面内)
- NaVILA demo中的prompt:"Walk forward out of the room. Turn right and enter the other room and stop in front of the table." (明确的路线规划,且事先知道场景中有什么物体)
- (Q1)调低仿真质量,对齐到以前有比较好的导航结果的设置。
- 其他:
- 测试了VLNVerse中的场景003,机器狗能够在该场景中正常交互与导航。
By 2026/4/26
- 会后TODO
- 转向角度
- 可以先检查运行成功情况,从运动指令中找一下原子动作,再考虑检查训练数据(即便训练数据里有不同的动作,如"转向30度",但开源的NaVILA模型不能输出也白搭,最多可以用训练数据做后续微调的补充)。
- 有除了45度以外的转向角度!
- 检查tokenizer
- 转向角度、前近距离等(如"45")在tokenizer中是特殊符号!
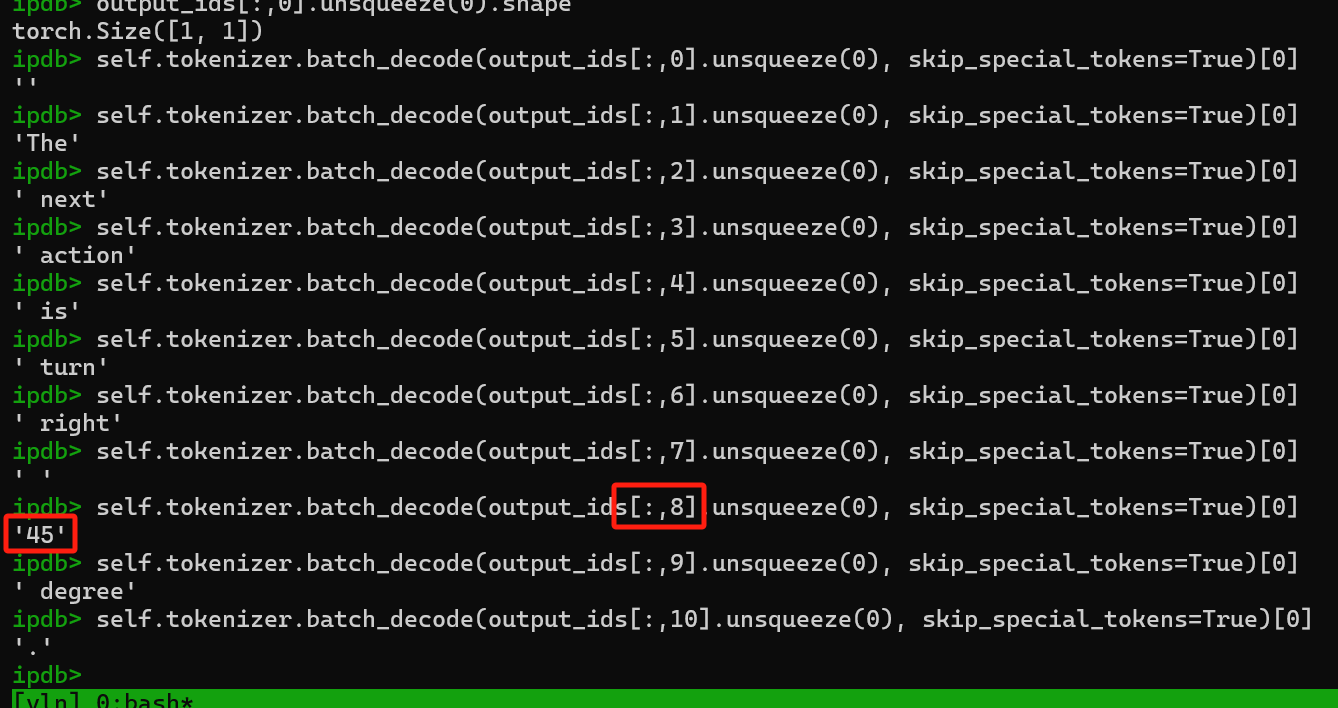
- tokenizer的vocabulary里有很多数字的编码,但它们彼此并不邻接:
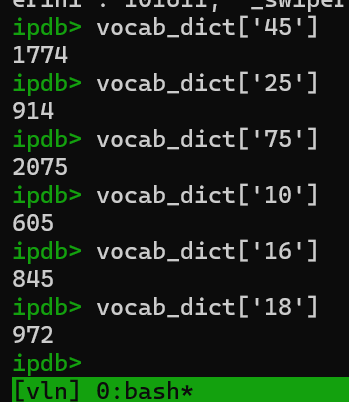
- 分词器中包含不同前缀空格规则的token:
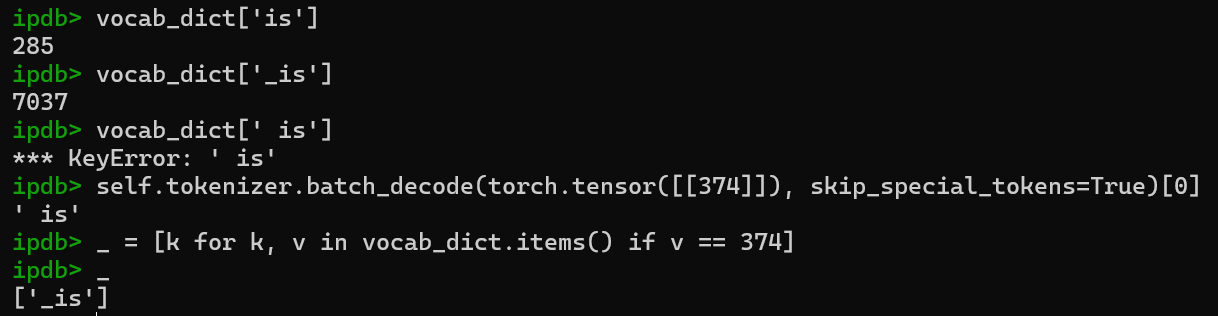
- 转向角度、前近距离等(如"45")在tokenizer中是特殊符号!
- 转向角度
- NaVILA精细指令测试
- 现象梳理
- 发现NaVILA对准确的指令,如转向等指令跟随效果较好(尤其是在指令开头就有左右转向的指令时)。
- 后来发现长程任务的执行几乎都不怎么样(尤其是直行 + 条件转弯的组合,应该没成功过),看起来只有第一个动作能比较忠实地完成。
- 可以用语言较为精细地控制VLN,例如,VLN会根据"slightly turn left"生成出"turn left 15 degrees"的命令。
- 提供停止条件(stop at xxx等)可以一定程度上改善任务成功率。
- 中间过程也应该提供比较明确的停止条件,即两个动作应该在什么条件下切换(比如"做XXX直到看到XXX,随后XXX")。
- NaVILA似乎不能在精确的数字运动指令下生成控制命令("前进3米" -> 直接stop)
- 发现NaVILA对准确的指令,如转向等指令跟随效果较好(尤其是在指令开头就有左右转向的指令时)。
- 成功条件总结:
- NaVILA的输入导航指令应该尽可能简洁、简短,尽量不要超过两个动作。例如,
- ❌ "先直行走到厨房,随后左转,再直行走到水槽旁边" -> 动作过于复杂,NaVILA handle不了;
- ✅ (画面中有桌子)"朝着桌子前进,在桌子前停下";
- ✅ "先左转直到你看到一张床,随后朝着床前进,在床前停下,越近越好";
- 输入的导航指令中应该有明确的中间条件 / 终止条件。例如,
- ❌ "先直行,随后右转,进入餐厅" -> NaVILA无法判断该在什么地方切换动作;
- ❌ "左转后直行,进入走廊" -> NaVILA无法判断该在什么地方停止;
- ✅ "先直行,在一张桌子前停下,随后左转,直到你看到一个书架";
- ✅ "左转,直到你看到一张茶几"
- 注意减少导航指令的歧义性。例如,
- ❌ (画面中有两个带有花瓶的桌子) -> "走到带有花瓶的桌子前"
- NaVILA的输入导航指令应该尽可能简洁、简短,尽量不要超过两个动作。例如,
- NaVILA问题梳理(包括但不限于):
- 空间理解能力较弱,很多时候无法判断和物体的远近关系,经常怼到墙上或者离目标物体很远就停止(这点可以通过明确"as close as possible"等改善)
- grounding能力较弱,很多时候NaVILA无法把指令中的物体和画面中的物体对号入座;
- 指令跟随有时会跑飞,比如明明让它(甚至是第一个动作)直行,它非要转弯;明明让它左转,它非要右转。跑飞的概率体感在20%。
- NaVILA在运动途中(比如一段长直线运动)很少会调整角度,经常一条道走到黑,直到怼到墙上(也观察到过中途调整15度的情况,但是占比很低)
- 现象梳理
-
NaVILA的训练
- 继续设法优化NaVILA任务表现
By 2026/4/30
- StreamVLN短指令测试
- 现象梳理
- StreamVLN的成功率,尤其是1-2动作的短指令的成功率体感显著高于NaVILA,在不会因场景太小而卡住的情况下,成功率~70%;
- 在前进过程中,StreamVLN有时会输出调整方向的命令(是期望的,可以避免朝向错误),但是不够稳定,暂时没发现调整方向与否的规律;
- SFT后的StreamVLN的指令跟随能力很强,尤其是在一开始就转向的指令中。StreamVLN可以很准确地 follow (slight / normal / sharp) 等转向幅度控制信号。
- 在少数情况下(指令形式通常为"先直行,再转弯"),StreamVLN会有跑飞的现象(只直行不转弯),暂时未发现规律,所有测试案例中只有 2~3 case。
- StreamVLN似乎有某种停止机制,看起来是前后两张图的相似度比较高就停止(在很多卡住所以画面变化不大的case中观察到了这个现象)
- 问题梳理
- 不会上楼梯!每次输入上楼梯的语言指令,VLN都会控制狗在楼梯前停住!
- StreamVLN的空间感知能力有些弱!在执行类似"在XX前转弯后XX"的动作时,几乎总会在离目标物体很远(~5m?)的位置开始进行下一步操作!如果没有精确的指令引导("当你离得足够近时停止"等),StreamVLN输出停止信号的位置也会离目标位置较远。
- 当画面中出现遮挡物时(比如,画面中一半是墙,一半是目标物体),StreamVLN总是不能绕开障碍,会一头撞上去。
- 现象梳理