Generalized Deep Image to Image Regression
2021/9/10
来源:CVPR17
resource:github上备份的包括ipad标注的pdf版本。
作者是马里兰大学的Venkataraman Santhanam, Vlad I. Morariu, Larry S. Davis等人,这写作水平给我看吐了,是不是不会好好说话!喜欢摆弄"高级"词汇是吧。
Summary:一篇比较菜的文章,贡献仅仅是模型结构设计,用一种循环分支+各分支上采样复用以提高scale的方法去做多任务(去噪、色彩恢复、人脸灯光增强)。创新点非常有限,还喜欢整点花里胡哨的词和晦涩难懂的句子,实在让人没有好感。
Key words: 模型结构设计、循环结构、参数复用
Rating: 2.0/5.0
Comprehension: 3.8/5.0
一张图总结模型结构:
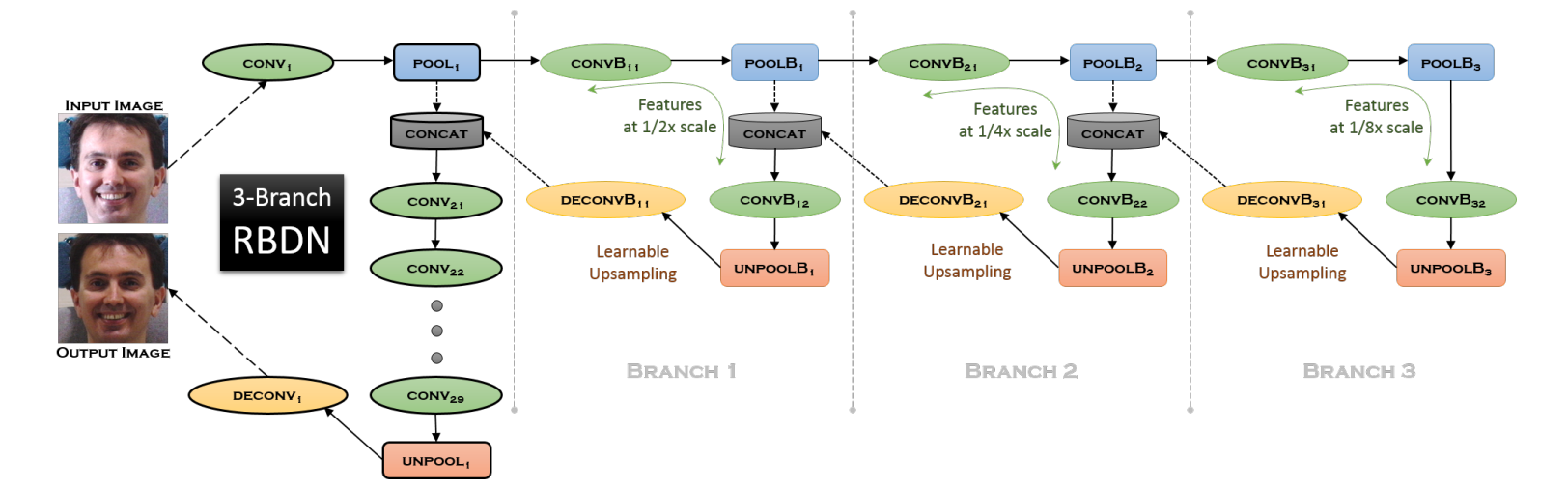
要点:
- 用recursive branching方案+参数共享(实际上就是走一样的路径)+可学习上采样(实际上就是deconv)去算不同尺度的特征,起了个fancy的名字叫multi-context representation
- 在卷积层前concate起来这些不同尺度的特征
- 就这么简单的事他们说了什么diao话呢?我无言以对:
the Recursively Branched Deconvolutional Network (RBDN) develops a cheap multi-context image representation very early on using an efficient recursive branching scheme with extensive parameter sharing and learnable upsampling. This multi-context representation is subjected to a highly non-linear locality preserving transformation by the remainder of our network comprising of a series of convolutions/deconvolutions without any spatial downsampling
1 Introduction
讲一般的分类网络VGG和ResNet在图像回归任务上为什么不work的故事:
- 由于分类任务只需要输出最后一个标签,所以这类网络的设计目标是捕捉strong global image features
- 图像分割任务是逐像素预测标签,所以和图像分类任务有些类似,但是标签具体到每个像素(所以有些中间态的感觉),因此需要达到locality-context的平衡(前者可以理解为局部特征,后者可以理解为全局语义),而图像分割任务偏向全局语义,所以需要根据全局激活重建局部依赖(
trade-off was skewed in favor of incorporating more context and subsequently reconstructing local correspondences from global activations) - Image-to-Image (Im2Im) regression任务则更倾向于locality
- 所以architecture在locality-context平衡上的偏好与任务不匹配决定了这类模型表现不太好。
3 Generic Im2Im DCNNs
3.1. Classification DCNNs are a bad starting point
同意。
- 分类DCNN有很多downsample层,需要修改设计以恢复/发掘local correspondences
- 重复上采样对pixel-wise预测有害(这里应该指的是downsample-upsample pair?)
- 把前面的act merge到后面的层有缺点:前面层的act建模非线性的能力很差,从而限制了模型全局建模局部非线性变换的能力(
activations from very early layers (which contain the bulk of the local correspondences) have a poor capability to model non-linearity, which limits the overall capacity of the network for modeling localized non-linear transformations) -> 所以在模型前期就把不同尺度的特征提取出来
3.2. Proposed Approach: RBDN
- The key feature of this network is the multi-scale composite map and how it is efficiently generated using recursive branching and learnable upsampling
- 结构可以分为两部分,主支B0和循环分支B1…BK
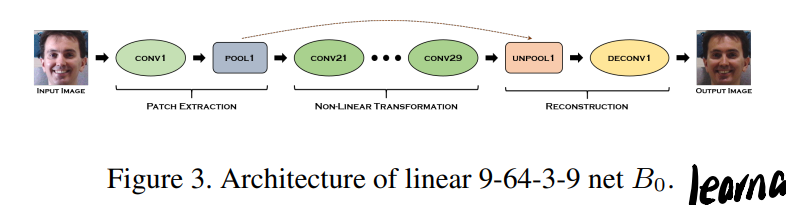
3.3 The Linear Base Network B_0
正常的CNN结构,原文有些参数设置,每个Conv/DeConv后接ReLU和BN
3.4 Recursive Branches B_0, …B_K
主支感受野比较小,但是又不能用downsample,所以这里用了循环分支:
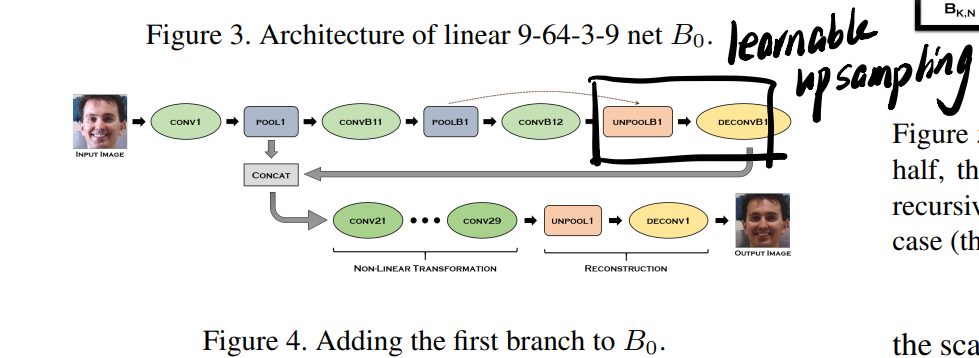
而所谓的可学习的上采样其实就是DeConv。
循环分支的构建有点抽象,不如直接去看3分支case:
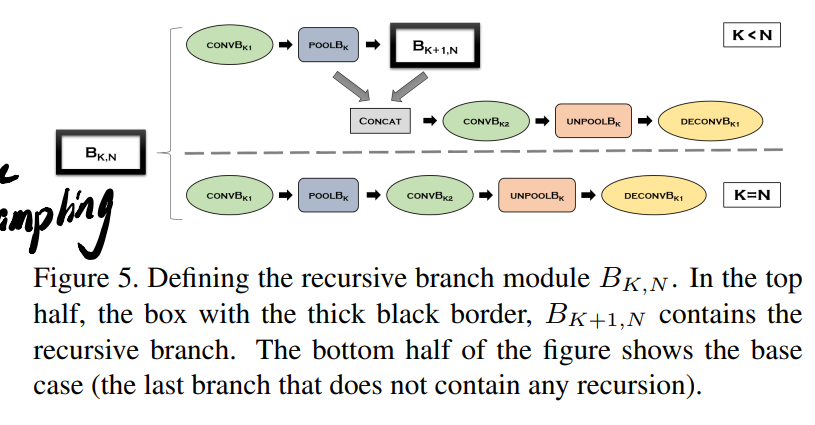
循环构建的好处有两方面:
- 参数共享,最远路径的尺度特征会走遍之前的上采样层
- 深层分支可以建模更多非线性(model more non-linearity),感受野更大,和全局特征相关(注意到经过了很多pool了吗?先pool再unpool!)
5. Result
实验设置完全无聊,除了:
- 去噪实验是盲去噪
- 每个任务只是结构一样,得分开训
- 填色有两套设置RBDN-YCbCr和RBDN-Lab,不懂,也不关心
- MSE loss会限制填色表现(dull&highly under-saturated)