End-to-End Object Detection with Transformers
2023/9/22
来源:ECCV20
resource:github上备份的包括ipad标注的pdf版本。
作者是nuTonomy公司的Alex H. Lang, Sourabh Vora, Holger Caesar, Lubing Zhou, Jiong Yang, Oscar Beijbom。(这个公司是MIT的科技初创公司,13年就开始做DL了,16年被Delphi Automotive买了)
Summary:一篇很不错的经典文章,提了Lidar点云的一种编码方式(pillar)+ 一个backbone,实现了E2E且仅依赖于Conv2D的3D检测,并且取得了显著好的性能与效果:
- 设计了一种Lidar点云的编码方式(pillar, point clouds organized in vertical columns);
- 设计了一种3D检测backbone,利用learning-based encoder可以实现端到端的检测,任务效果与推理性能都显著优于此前的工作。
Key words:
- 3D Detection
Rating: 5.0/5.0 很不错,很经典的一篇3D检测的文章,内容很详实,主打一手开诚布公;无论是文章写作还是内容本身都非常优秀,今年以来读过最舒服的文章(其实是今年没怎么读文献!)。
Comprehension: 3.0/5.0 第一次读3D相关的文章,一头雾水。。!不懂的东西太多了,还要再摸摸。
来一张Teaser大图(虽然够呛用来总结全文):
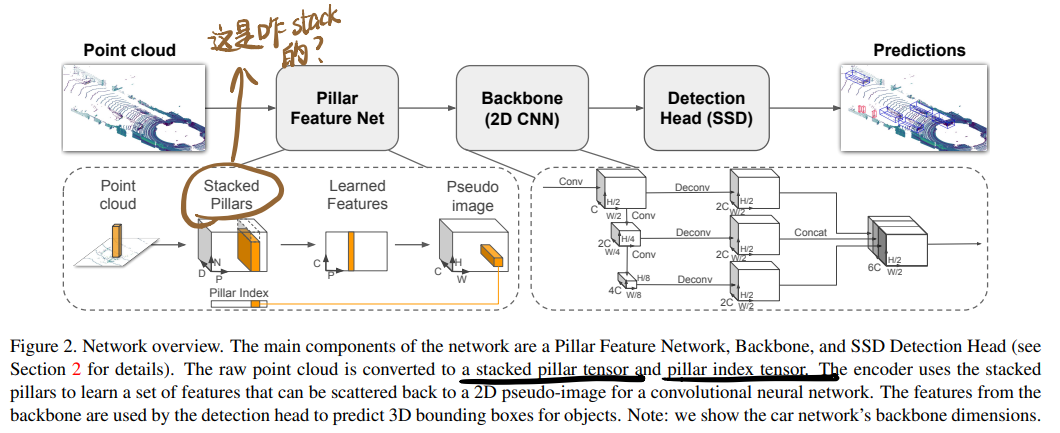
1. Introduction
- 一些比较零碎的背景知识:
- Lidar是自动驾驶中最重要的传感器之一,用一个laser scanner来测距生成稀疏点云;
- 传统的robotic bottom-up pipeline是这么处理点云的,先做背景剪除,再做时空聚类(spatiotemporal clustering)和分类;
- 图片和Lidar是3D检测中的两种常见模态,它们的区别是:
- 点云是一种稀疏表示,而图片是一种dense表示;
- 点云是3D的,图片是2D的;
- 传统的(19年及以前的)3D检测的思路是,用3D卷积(一个显著的劣势是慢)或者把点云映射到2D图像上;PointPillar同期的工作倾向于用Lidar点云的BEV视图(这个方法有两个好处,其一,BEV可以保持物体的尺度,scale;其次,BEV上作用的Conv2d可以保持"local range information");
- 但是,BEV的缺点是,这个视图也非常稀疏,计算效率不高 -> 一个workaround是,按照平面切分成若干格点,再做hand-craft encoding;(所以pillar+NN就是所谓的编码方案吗,区别于手工设计的某种计算规则?)
- 给出了pillar编码方案的几个优点:
- pillar的编码是基于学习的(意思是后面跟着learnable encoder?),比手工设计的固定编码方案更能充分利用点云信息;
- 用pillar而不是voxel就不用手动调垂直方向的binning了;
- 处理得很快;
- 不需要手工调不同的点云配置(requires no hand-tuning to use different point cloud configurations such as multiple lidar scans or even radar point clouds);
- 一些RW相关内容:
- 2D CV中的检测可以分成2-stage和1-stage的;
- 3D CV中的检测:
- 早期的工作base on 3D Conv,这种卷积非常慢;
- PointPillar同期的工作往往将点云映射到ground plane(我理解就是BEV试图)或者image plane;
- 一个主流范式(voxelization)是,将点云组织成voxel,并将每个vertical column中的voxel编码成定长、手工设计的特征编码,来形成一个pseudo image,再用2D检测backbone处理;
2. PointPillars Network
PointPillar接受点云作为输入,输出oriented 3D boxes作为汽车、行人和骑自行车的检测结果,包括三个部分,(1)特征编码器(feature encoder),将点云编码成稀疏pseudo image;(2)2D卷积backbone,处理伪图生成高级表示;(3)解码器,检测并回归出3D boxes:
2.1 Pointcloud to Pseudo-Image
PointPillar最关键的设计。 计点云中的一个点为$l$,它有三个坐标$x$, $y$, $z$,
- 第一步是在x-y平面均匀划分出grid,类似于voxel,区别是在z轴上的空间是无限的,也就不需要靠超参数控制z轴上的bin;Pillar的个数为$\mathcal{P}=B$;
- 接着对每个Pillar中的点做增强(augmentation,这里也叫decorate),给每个点增加6个新的维度$r$, $x_c$, $y_c$, $z_c$, $x_p$, $y_p$:
- $r$是reflectance;
- $c$下标是到每个pillar的算术平均点的距离;
- $p$下标是指到pillar中心$x$, $y$的偏移量;
- 这里是对Lidar点云点做的装饰,radar or RGB-D中的点也可做类似的处理;
- 这么处理出的pillar绝大多数是稀疏的,一个典型的数字是97%的稀疏度(
这里的稀疏度是指?相比最满的pillar,稀疏的pillar只有3%的点,还是97%的pillar是空的?-> 看起来是指空pillar);为此,可以限制每个样本中的非空pillar数(P)和每个pillar中的点数(N),来形成一个紧致的tensor (D, P, N);- 如果一个pillar里的点太多就sample,如果太少就填零;
- 第四步,用一个简化的PointNet(说是Linear+BN+ReLU)处理每一个点,生成一个(C, P, N)维度的tensor(看起来就是D个维度的信息抽成C个通道),然后在N维度做个max操作,生成一个(C, P)维度的tensor(给N干没了还行,每个pillar里的点这么不重要吗?还有,是在C维度上取最值吗,那每个通道的最值取完不是同一个点怎么办?);
- 最后,把处理后的点填回原来的位置,形成一张(C, H, W)维度的pseudo image。
2.2 Backbone
采用了U-Net架构的backbone,读文章的时候要注意,文中的$S$是指图像的"画幅"(resolution的意思)。
2.3 Detection Head
用了SSD作为3D检测头。用2D IoU做priorbox和GT的匹配。
- (尚且不懂的细节) Bounding box height and elevation were not used for matching; instead given a 2D match, the height and elevation become additional regression targets.
3. Implementation Details
超级多的实现细节,令人叹为观止!
3.1. Network
一些不是很重要的参数,直接就看代码就好;需要注意的是,PointPillar分成两个网络,一个负责car的检测,一个负责pedestrian/cyclist的检测,两者设置略有不同;
3.2. Loss
非常复杂,我的建议是我别手抄了,直接上图吧(看代码的时候好好对照下吧。。。):

- 一些已经想明白的点:
- $\theta$是指box的角度(可能是角坐标系,有个朝向,那么flipped是指车头的朝向);
- 那一坨&\delta&是做的放缩,应该是按照惯例,可能是直接回归想要的数比较困难吧,所以要做点编解码;
4. Experimental setup
连这里也有很多的细节!
4.1. Dataset
- Kitti数据集
- 数据集中的数据包括Lidar点云和图片;(PointPillar只在点云数据上训练,而有的方法是multi-modal的方式做融合)
- Kitti数据集原本分成7481张训练数据与7518张测试数据,PointPillar的实验包括两种自定义的划分方式(这个是practice吗?以及大表格中的划分方式是哪种?):
- 把官方训练集的数据进一步分成3712张训练数据 + 3769张验证数据;
- 在提交测试结果时,把官方训练集中的6733张训练数据作为训练集,在剩下的784张上做验证;
- 只有在图像中出现的物体才会被标注(我理解是点云中有部分数据没有被标注),因此作者采用了
only using lidar points that project into the image的practice;
4.2. Settings
- 一些实验设置的细节;关于Anchor的描述有诸多不理解之处:
- 关于PointPillar的超参数,选择x-y的间隔为0.16m, 最大Pillar数$\mathcal{P}=12000$, Pillar中的最大点数为$\mathcal{N}=100$。
- (anchor)采用了和VoxelNet中一样的Anchor(我现在还是不太理解中的检测中的Anchor的含义)设置,每个class anchor都有长、宽、高、z中心和{0, 90}两个角度(anchor是可能有物体的proposal吗,那按这个描述anchor是per-pillar的?),anchor和gt用2D IoU做匹配,一个正匹配是当前anchor和gt box的IoU最高,或者高于一个正匹配bar(positive match threshold);一个负匹配是低于负(negative)匹配bar的,其他的anchor不计入loss;
- 在推理时采用axis aligned non maximum suppression(NMS)(和普通NMS有啥区别吗?),overlap threshold取为0.5 IoU;这么做和rotational NMS(这个又是什么?)效果相当但速度更快;
- 另有一些box的选择metric,让人有点好奇这个是咋选的,box size还好说,可能是dataset提供的,但是threshold咋来的,手试出来的吗?:

4.3. Data Augmentation
- PointPillar的数据增强方法似乎也很有效,采用了一种背景与物体分离并随机放置的方法:
- 先按照SECOND的方式建了一张LUT,包括各个类的gt 3D box以及其中的点云点,对于每个sample,随机选(15, 0(不是打错了?0?), 8)个gt car, pedestrians, and cyclists并放到当前的点云中(这里有点好奇,意思是从当前sample中采样出这么多box,还是把其他sample里的box随机加到当前的sample中?);
- 对于每个gt box做单独的增强,每个box随机旋转$[-\pi/20, \pi/20]$个角度,并在x, y, z三个轴上"translate" ~ $\mathcal{N}(0, 0.25)$ 个单位;
- 最后,对点云和box做个全局augmentation,随机沿着x轴做镜像翻转,全局旋转和scaling;并做个全局translation with x, y, z drawn from $\mathcal{N}(0, 0.2)$ to simulate localization noise.
5. Results & Realtime Inference & Ablation Studies
哪怕连实验部分也有很多可以学的东西!
- 所有的检测结果都是按照Kitti官方的检测指标来的,包括BEV, 3D, 2D和average orientation similarity(AOS),其中,
- 2D检测是在图像平面中(image plane)的;
- AOS评价的是2D检测的平均方向(BEV视角下)相似度 - average orientation similarity assesses the average orientation (measured in BEV) similarity for 2D detections.
- 后文中指出,BEV和3D指标下都没有考虑方向,方向的检测是AOS,具体的做法是把3D box映射到图像中,做2D检测匹配,再评估这些匹配的方向;
-
来张结果大表:
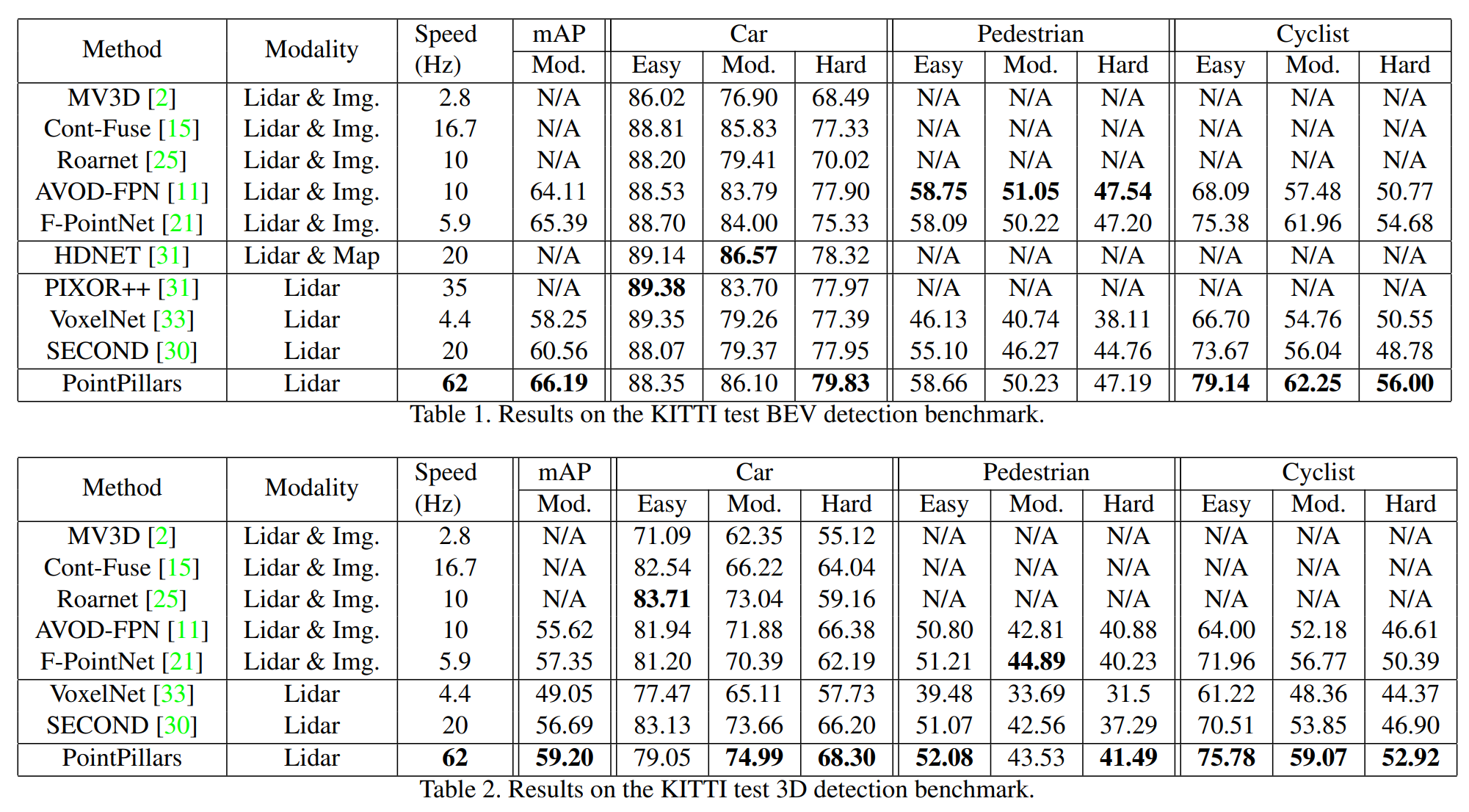
- 看起来BEV视角下的分数总体要比3D的高(可能和IoU的计算方式有关?)
- 三个类的难度差异比较显著,pedestrian > cyclist > car;
- 定性分析中给了个错误模式分析,有点意思;
- Inference部分给了各部分延时的分解,体现出了整个处理的pipeline,很不错:
- 加载点云,根据范围和visibility过滤(1.4ms);
- 将点云组织成pillar并decorate(2.7ms);
- 将PointPillar tensor加载到GPU上(2.9ms),做encode(1.3ms),再散列成pseudo image(0.1ms);
- 用backbone和检测头处理(7.7ms);
- 在CPU上做NMS(0.1ms);
-
后面还详细分析了encoding方案、模型slimming、TRT部署,分析很详实;
- Ablation部分,
- spatial resolution可以影响性能-效率 trade-off;
- 作者发现在有gt采样的前提下,minimal box aug就已经很好用了(extensive aug会导致精度损失);
- 解释了下decoration的选项并做了个ablation;
- learning-based特征编码方案严格好于手工设计的方案;作者给出了几个复现结果优于原文的可能性:
- advanced data aug(引入gt采样、更好的超参设置);
- 各个超参选择的组合(网络参数设置、anchor box设计、localization loss w.r.t. 3D & angle、classification loss、optimizer参数等);