Training Binary Neural Network without Batch Normalization for Image Super-Resolution
2021/6/11
来源:AAAI2021
resource:github上备份的包括ipad标注的pdf版本。
作者还是ECCV2020上做BSR的西电的组,有Xinrui Jiang, Nannan Wang, Jingwei Xin, Keyu Li, Xi Yang, Xinbo Gao(或许可以去看下他们的主页)。
Summary:感觉文章挺虚的,这就是做应用的吗。文章的出发点还挺好的,觉得除了前后两个FP Conv之外中间的BN层也会引入大量的FP OP,所以想解决掉这个BN层(但是解决的方式有点南辕北辙了,你加个PReLU和BN其实区别不大吧,都是zero point/distribution shifting,而且这还是引入FP op啊)。文章提出了一种Binary Training Scheme(但是对BNN的训练没有启发,这里说是"训练方案"实际上只是一些BNN里常见设置的堆砌,没有什么参考价值),利用BNN里的一些fancy方法构建了个强baseline(同样没什么参考价值),最后提了一种BSR architecture(一种building block,里面的一种dilated conv concate的操作好像还有点参考价值)。此外这篇文章中BSR的训练还用了multi-step KD,同样是直接挪用了现在BNN工作的一些思路。
Rating: 3.0/5.0
Comprehension: 3.8/5.0
motivation:(不错的出发点,可是落脚点不太对劲?)BSR网络中的BN层虽然可以重中心化输入的分布从而减轻量化的影响提点,但是引入了很多FP op,对低精度硬件非常不友好,因此想移除这种层。
文章的贡献有:
- Binary Training Scheme(取代BN的方案,但本质上是BNN工作中的常用设置);
- 一种BSR building block(这种东西一般没什么很强的创新性可言吧)+ KD的使用。
1 Introduction
- 学到了一个新词:ill-posed problem(不适定问题),描述SR中的这种one-to-many mapping。
- SR研究的方向之
- 增加层数打点;
- 减少参数和资源消耗(比如recursive learning、parameters sharing、squeeze operation、 group convolution、 wavelet domain)。
2 Related Work
关于SR更详细的报菜名,或许还有点用。
3 Methodology
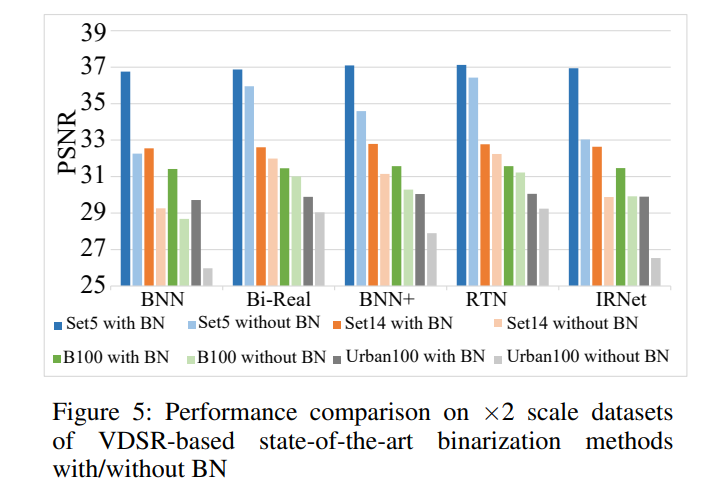
给了BSR model去掉BN层掉点的对比,有点意思:
3.1 Binary Training Mechanism(BTM)
基于以下考虑提出取代BN的BTM:BN可以re-centering输入的分布,从而减轻1-bit的量化效应;同时BNN里BN的输出会被推到{-1, +1}上,对称分布的数据被量化后效果和BN类似;第一层/最后一层(尤其是第一层)Conv之后的BN去掉之后点非常严重。
BTM的细节包括:
- Weight initialization: 用Xavier uniform distribution(而这早就在很多BNN网络中采用了,比如BMXNET框架中参数的初始化);
- Data initialization:用数据集的均值和方差对输入数据归一化(???这不是自然的吗,有不进行预处理的吗?这也可以写吗?);btw,作者强调的这一点很奇怪:在最后一层中加上输出图片的均值(we add the mean value from the output images in the last layer);
- Activation:introduce PRelu(这才是关键吧,PReLU在相当大的程度上可以当BN来用,这是去掉了个显示化的FP op,用隐式化的FP op代替?有点好笑)。
可以看到作者取代BN的操作有点迷惑。
3.2 Baseline
作者argue他们的贡献之一是用BNN的技巧堆砌了一个baseline,同样一言难尽:
- Network Settings: FP first/last Conv;
- Block Structure: Binary Activation → Binary Convolution → PRelu Function;
- Optimization:scaling factors + bi-real STE estimator。
这样就已经达到SOTA结果了。
3.3 Improved Binary Super-Resolution Network
Network Structure:这里有点意思。作者提了个multiple receptive-field block(MRB),如图所示:
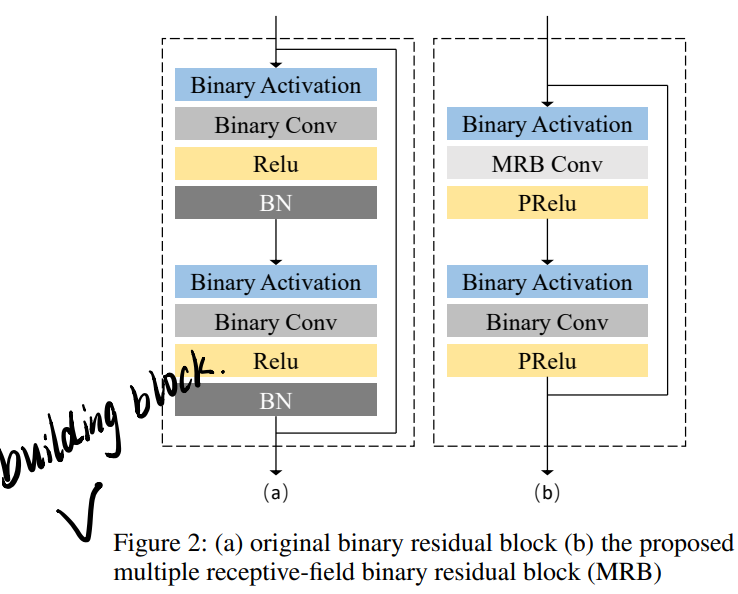
其中MRB Conv是一组并行的dilated Conv,其结果concate在一起作为该层的输出:
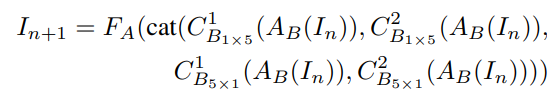
式中\(C_{B_{m\times n}}^r\)表示一个dilation rate为r,尺寸为\(m\times n\)的dilated Conv,为了保证通道数目不增长,每个\(C_{B_{m\times n}}^r\)的输出通道有一个1/4的系数。后面的Conv是个一般的\(3 \times 3\)。(用different sized dilated Conv并行提取特征的想法感觉还挺新颖的,这样不会增加params)
Multi-stage Knowledge Distillation:MRB的训练还加上了multi-step KD,这是在模型的不同位置引入loss term实现的:
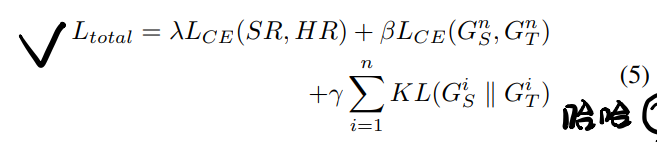
(这公式还给打错了),\(G_T=softmax(z_t)\)和\(G_S=softmax(z_s)\)分别是模型不同位置老师/学生模型输出(activations)的logits的softmax。\(L_{CE}\)是SR和HR(超分图像及高分辨率图像)的L1 loss。又因为SR任务和每个像素值的准确性有关,因此又加了个老师学生模型输出逐比特的L1 loss(就是\(\beta L_{CE}(G_S^n,G_T^n)\)这项)。
Regulable Activation:这个有点不理解(前面写过PReLU这里为啥又写一次?)。大概的意思是为了减少老师和学生输出activations之间的差距,在每个这种output之后又加了个PReLU,前面的BTM和这里重复出现PReLU的原因我猜测是BTM和这里的architecture相对独立,但是两者都用了PReLU(上面的block示意图应该可以佐证)?
4 Experiments
- 训练集依然是DIV2K,测试集也依然是Set5、Set14、BSD100和Urban100。
-
两类SR网络:interpolation-based method(VDSR)和learning-based method(EDSR)。
实现baseline可能需要看这里对两种网络的改编和其他details. - 在VDSR上的结果:
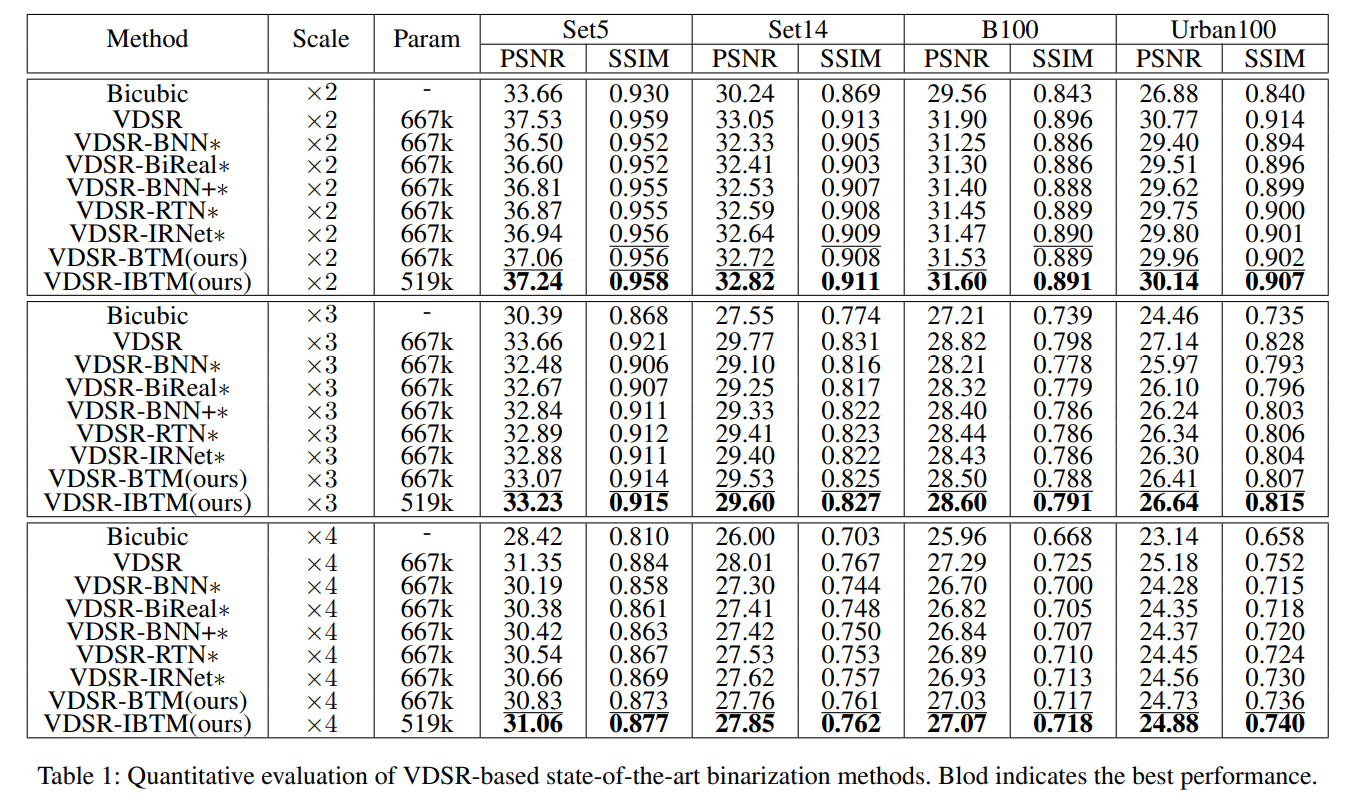
-
- 这里说和ReLU只生成正值激活,所以用Hardtanh代替(??这计算量引入的不止一点两点吧?但是是在Comparison with/without BN part说的,所以正常实现中也是用的这个吗?)
- 带"*"号的都是用BTM的(拿掉BN层用BTM方案):?所以这些方案和VDSR-BTM的区别在哪?而且BNN/BiReal/BNN+等方案是怎么套到VDSR上的?
- VDSR-BTM和VDSR-IBTM的区别是有没有用刚才说的building block。
- 这个比较中upscale modules似乎采用了sub-pixel convolution,其中weights都是binary的/activation仍然是FP的。
- 在EDSR上的结果:
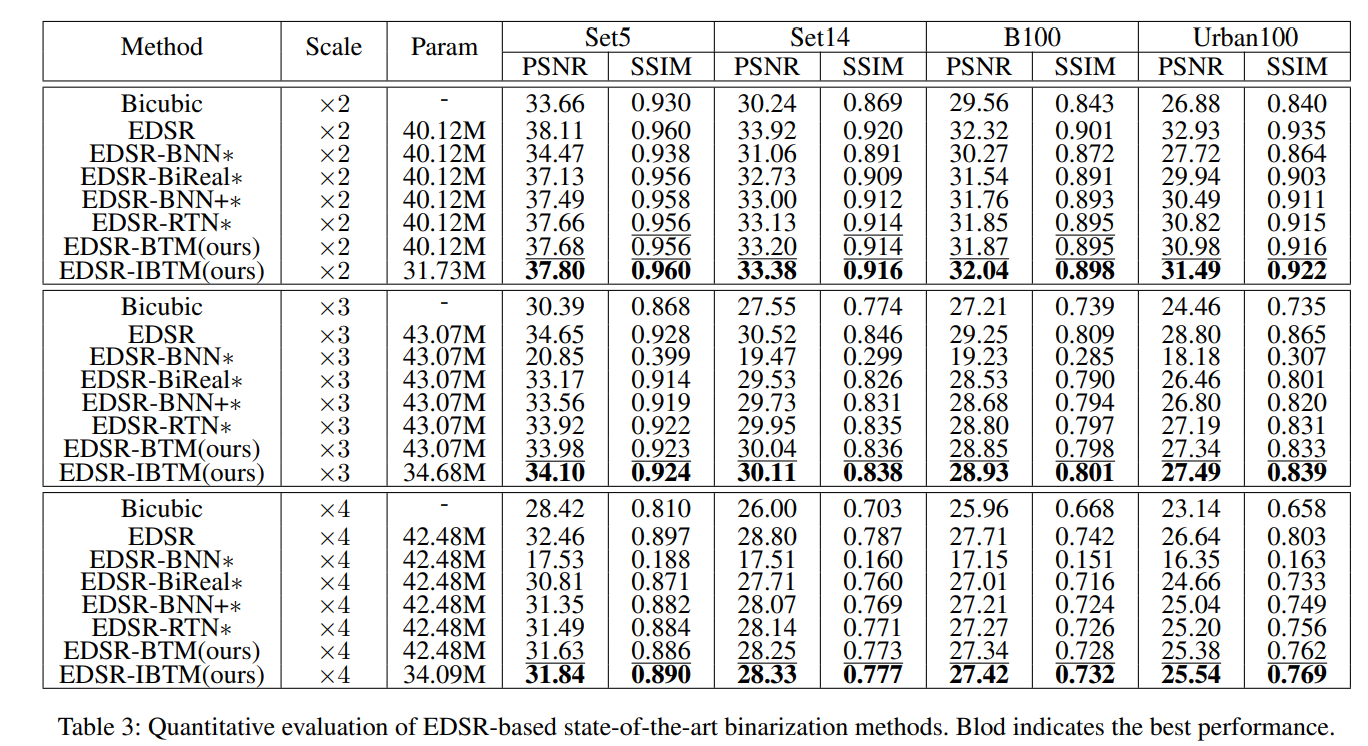
感觉其他的方案都好不明确啊?想不通BNN/BiReal/BNN+/RTN是怎么拿来改造VDSR/EDSR的?应该需要看一下后面这两个工作?