PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
2023/9/20
来源:CVPR17
resource:github上备份的包括ipad标注的pdf版本。
作者是Stanford的Charles R. Qi, Hao Su, Kaichun Mo和Leonidas J. Guibas。L J. G组做了相当多的3D CV方面的工作,而且出了Hao Su、Li Yi、He Wang等一大批学术新星,堪称3D CV界的黄埔军校。
Summary:一篇很不错的经典文章,提出了直接feed on point cloud的3D Backbone PointNet,该工作到目前为止已有12K+引用量,可以算是3D领域的基石文章了;这个backbone直接将点云作为输入,输出分类/分割label;本身非常简单,基本上由MLP拼成,靠类似于注意力机制的模块在线计算"增强矩阵"来实现transformation-invariant特性、利用maxpooling来支持inordered input;可以面向3D分类、分割、场景分割任务。文章贡献主要有:
- 设计了一种3D CV领域的backbone,可用于3D分类、分割、场景分割;模型基本上基于MLP实现,直接将点云作为输入,输出分类logits/segmentation label。为了实现输入与特征两个层次的变换不变性引入了类似注意力机制的模块、为了实现非固定顺序的点云输入(同一个点云,按照不同的顺序输入模型,所得结果应一致)利用MaxPool实现特征聚合;
- 给了一些简单的理论证明(网络鲁棒性相关),但是和理解文章关系不大所以没细看;
- backbone基于MLP实现,复杂度和输入点云的尺寸呈线性关系(O(n)复杂度),所以计算效率还挺高的。
Key words:
- 3D Backbone
- 3D Classification
- 3D Segmentation
Rating: 5.0/5.0 很不错,经典文章,读起来非常舒服;基本上细节都能get到。
Comprehension: 4.0/5.0 读起来比较简单,除了两个理论证明的bonus之外基本上都看懂了。
一张图总结全文:
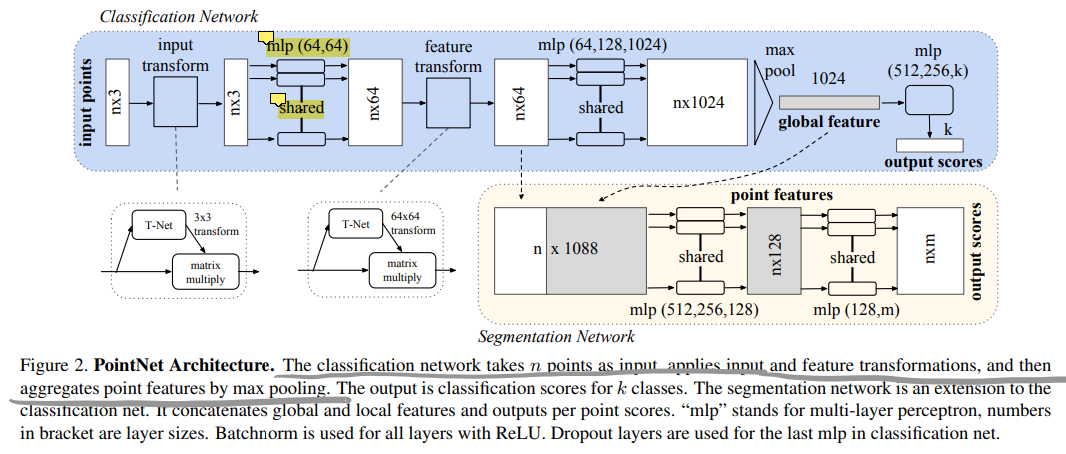
* MLP(*, **)的意思是每个点的维度经过一层MLP后变成*、**(这里是两层);
* `shared`意思是对点云中的每个点都apply同一个MLP。
* T-Net是个mini版的PointNet,根据输入feature预测一个变换矩阵,再把这个矩阵乘回当前的feature(类似于注意力机制);
* 分割网络是在分类网络的基础上追加一部分,有local & global feature的融合(这里是per-point地把局部和全局特征concate在一起了);
1. Introduction
- 一些比较零碎的信息:
- 点云和mesh是"不规律"(irregular)的数据格式,大家往往先将它们转换成规律的3D voxel或者不同视角下的一系列图片再做处理;
- 相比mesh数据,点云数据更加简单和统一,更适合作为NN的输入;
- 一个很有意思的Insight:
- 对点云数据的处理应考虑其对称性,即同一片点云数据,不同点按照不同的顺序输入,得到的结果应该是一致的;
2. RW
- 点云特征:PointNet之前的点云特征往往是面向特定任务手工设计的,会在每个点附上一些统计属性,这些属性往往对某些变换是不变的,可以分成:
- intrinsic & extrinsic
- local & global
- 但是通过手工设计找到特定任务的最佳属性非常麻烦;
- 3D数据上的DL工作分类:
- Volumetric CNNs:先体素化再处理;早期的用Conv3D的工作就是此类,但是这类方法的计算复杂度受点云规模影响较大,计算成本较高;
- Multiview CNNs:将点云投影到不同平面形成不同视角的图像,再用Conv2D处理,缺点是不易拓展到更多的3D任务上;
- Spectral CNNs:利用spectral CNNs处理mesh数据;缺点是constrained on manifold meshes and it's not obvious how to extend them to non-isometric shapes;
- Feature-based DNNs:先把3D数据转换成vector再处理,易受提取得到的特征的表示能力的限制。
4. Deep Learning on Point Sets
4.1 Properties of Point Sets in \mathrf{R}^n
总结了点云的一些性质和相应的对NN的要求:
- Unordered:点云的顺序不应该影响NN的处理结果;
- Interaction among points:点云中的点和它附近的点之间存在一些关系,NN应该能利用这些关系;
- Invariance under transformations:某些变换(比如全局旋转、translation)应该不影响点云的处理结果。
4.2 PointNet Architecture
网络总体架构见Summary部分。作者指出三个关键设计包括:(1)用Maxpooling层作为一种对称函数来聚合特征;(2)在3D Segmentation中利用局部与全局信息;(3)两个joint alignment networks,在输入(raw point)和特征两个层级实现transformation invariant性质(图中的T-Net):
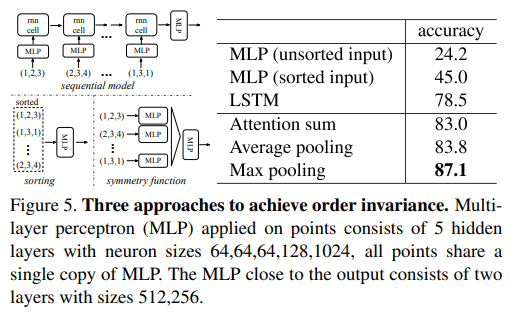
- Symmetry Function for Unordered Input:提了三个支持unordered input的方式,sort、RNN w. augmented data、aggregate information w. symmetric func. 分析后确定用Maxpool(对应第三类方案)
- sorting方案无法有效应对数据扰动问题,而且本身这种映射也不好学;
- RNN方案的出发点是,将点云视为连续信号,做一些随机重排作为数据增强,希望RNN能做到对输入顺序invariant;但是理论和实验都表明这种方式非最佳;
- 最后用"对称"(指对每个点的操作都是一样的,无论输入顺序如何计算后得到的set都是一样的,问题是后面的MLP分类头是怎么做到invariant的,看起来也没有shuffle)
- Local and Global Information Aggregation:
- 在Segmentation中需要用到全局和局部信息,方法是把全局feature逐点concate到局部特征上;
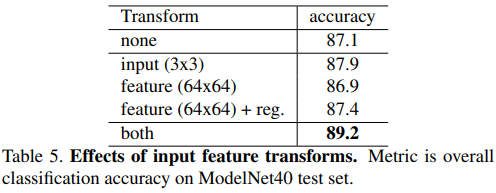
- Joint Alignment Network:
- 为了实现输入的生数据和经过一定处理的特征对某些几何变换保持不变性,一个自然但是复杂的方式是将这些输入点/特征对齐到一个规范(canonical)空间;
- 作者采用的方式更简单,设计了一个类似于自注意力机制的模块T-Net,从输入点/特征中预测出一个仿射变换矩阵,并乘回坐标/特征;
- T-Net的具体描述如下,是个mini版的PointNet:

- 在做特征空间的变换矩阵学习时,由于特征空间比较大,优化难度较高,于是加了个正则项:

4.3. Theoretical Analysis
给了一些理论分析没细看,大体说明(1)点云数据的扰动不会对预测结果产生较大影响;(2)模型的效果受到MaxPool后特征的维度限制;(3)模型可以学着从点云中总结一些关键点。
5. Experiment
在3D分类、3D物体部分分割、3D场景分割三个任务上验证了有效性。
- 3D分类:
- ModelNet40数据集,12,311 CAD models from 40 man-made object categories, split into 9,843 for training and 2,468 for testing.
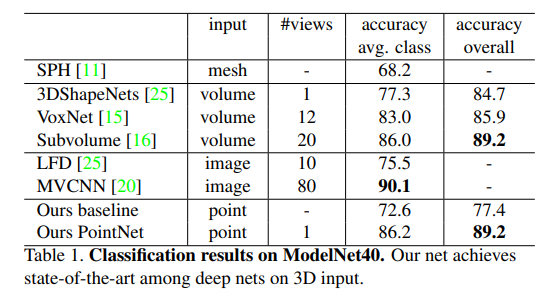
- ModelNet40数据集,12,311 CAD models from 40 man-made object categories, split into 9,843 for training and 2,468 for testing.
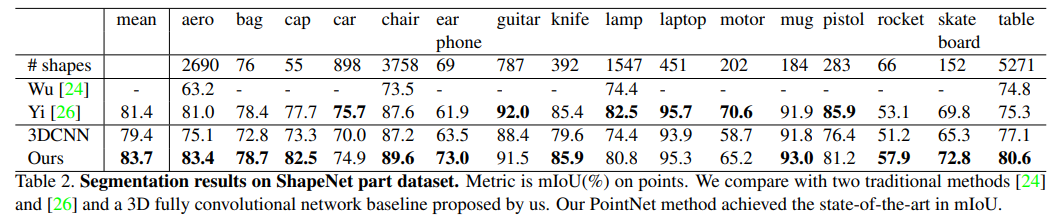
- 3D物体部分(Part)分割:
- ShapeNet part data set数据集,16,881 shapes from 16 categories, annotated with 50 parts in total;
- mIoU作为指标;
- 3D场景分割:
- Stanford 3D semantic parsing data set
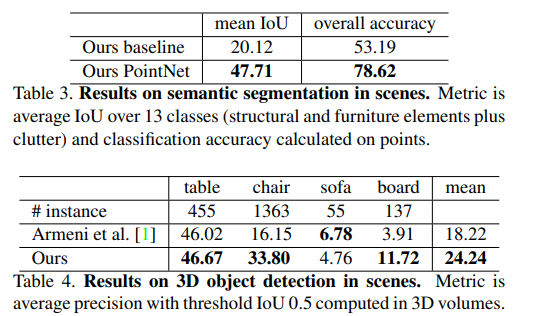
- Stanford 3D semantic parsing data set
- Ablations - 对其他的Order-invariant方法、输入与特征变换方式、鲁棒性做了消融实验。
- 实现输入顺序不变性的方式:
- 对输入与特征做变换不变性增强的效果:
- 一些鲁棒性结果:

- 实现输入顺序不变性的方式:
-
可视化 - 可视化了网络预测的关键点和upper-bound shape:

- 时间和空间复杂度分析 - PointNet的计算复杂度对点云规模呈线性,Conv2D类的方法是平方关系,Conv3D是立方关系。