Training Binary Neural Networks with Real-to-Binary Convlutions
2021/3/19
来源:ICLR2020
resource:github上备份的包括ipad标注的pdf版本。
又是Brais Martinez&Adrian Bulat!总是Brais Martinez&Adrian Bulat!Brais Martinez&Adrian Bulat发文的神!
Summary:文章比较一般,最突出的贡献是提了2-stage的training scheme(之前应该有人提过,但是这个是第一个中的?有人也是这仨)。感觉 rating 3.7/5 的样子(还是要比BinaryDuo更有Insight一点的)。文章先通过堆料搭出了个SOTA的模型,接着提出用multi-stage的方法通过match FP model和binary model各个block输出的feature map来训,还提了个用输入数据计算activation scaling factor的添头,懂的都懂。
文章的贡献有:
堆料搭了个SOTA的baseline(这也好意思说?);- 一种2/multi-stage 的 training scheme,实际上这个应该是和他们的类KD方法(即缩小FP/binary model在对应位置输出的feature maps之间的差距:原文称是attention matching strategy)紧密耦合在一起的;
- 一种基于输入数据的activation scaling factor(与XNOR-Net的不同在于本文的scaling factor计算函数里有trainable para/XNOR-Net是一种analytic的方法,与19年一篇文献中可训练的scaling factor的差别在于,后者不是input-based)。
Abstract
本文核心论点:减少binary和其对应的FP conv之间输出的差距可以提点。
1 Introdution
基本上就是稍详细地展开了上面的contributions,有点有趣的是Figure1,囊括了本文的贡献:
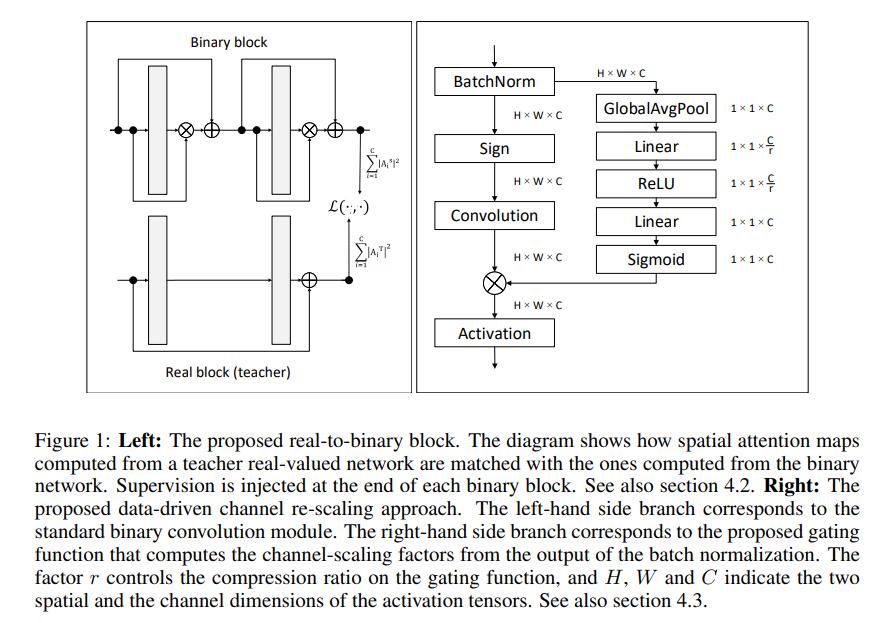
2 Related Work
作者在这里argue了一下和KD的区别,称Zhuang et al.2018
owever, (Zhuang et al., 2018) tries to match whole feature maps of the to-be-quantized network
with the quantized feature maps of a real-valued network that is trained in parallel with the
to-be-quantized network.
4 Method
4.1 building a stronger baseline
作者这里提了一个有点意思的结论,改变了block中的连接顺序后,BN中的bias成了一种可以训练的threshold。
4.2 Real-to-Binary Attention Matching
这边提了他们核心假设:
We make the reasonable assumption that if a binary network is trained so that the output of each
binary convolution more closely matches the output of a real convolution in the corresponding layer
of a real-valued network, then significant accuracy gains can be obtained.
4.3 Data-Driven Channel Re-scaling
这里有点细节,前面说的对activation rescale的只是个添头,实际上weights的scaling factor α还是照常用了的(实际上是主角吧)。
5.2 Ablation Studies
玄学之activation scaling单独不work,搭上attention matching才work。解释非常牵强:
It seems clear from this result that both are interconnected: the extra supervisory signal is necessary
to properly guide the training, while the extra flexibility added through the gating mechanism boosts
the capacity of the network to mimic the attention map.
"额外的监督信号对指导训练非常必要,gating mechanism(activations scaling)带来的额外灵活性提升了网络模仿attention map的能力"。那不是当然吗,XNOR-Net里面的scaling factor也可以啊?那你单独不work是怎么回事?
Remained Questions
待补充。