MAI2022记录
2022/6/30
Intro:Deep Learning on Mobile Devices: What's New in 2022?
- 部署的两种选择
- Android NN API:
- pros:API调用形式,硬件层blind,不用自己考虑底层硬件,会自动选择并加速
-
依赖硬件提供商的driver
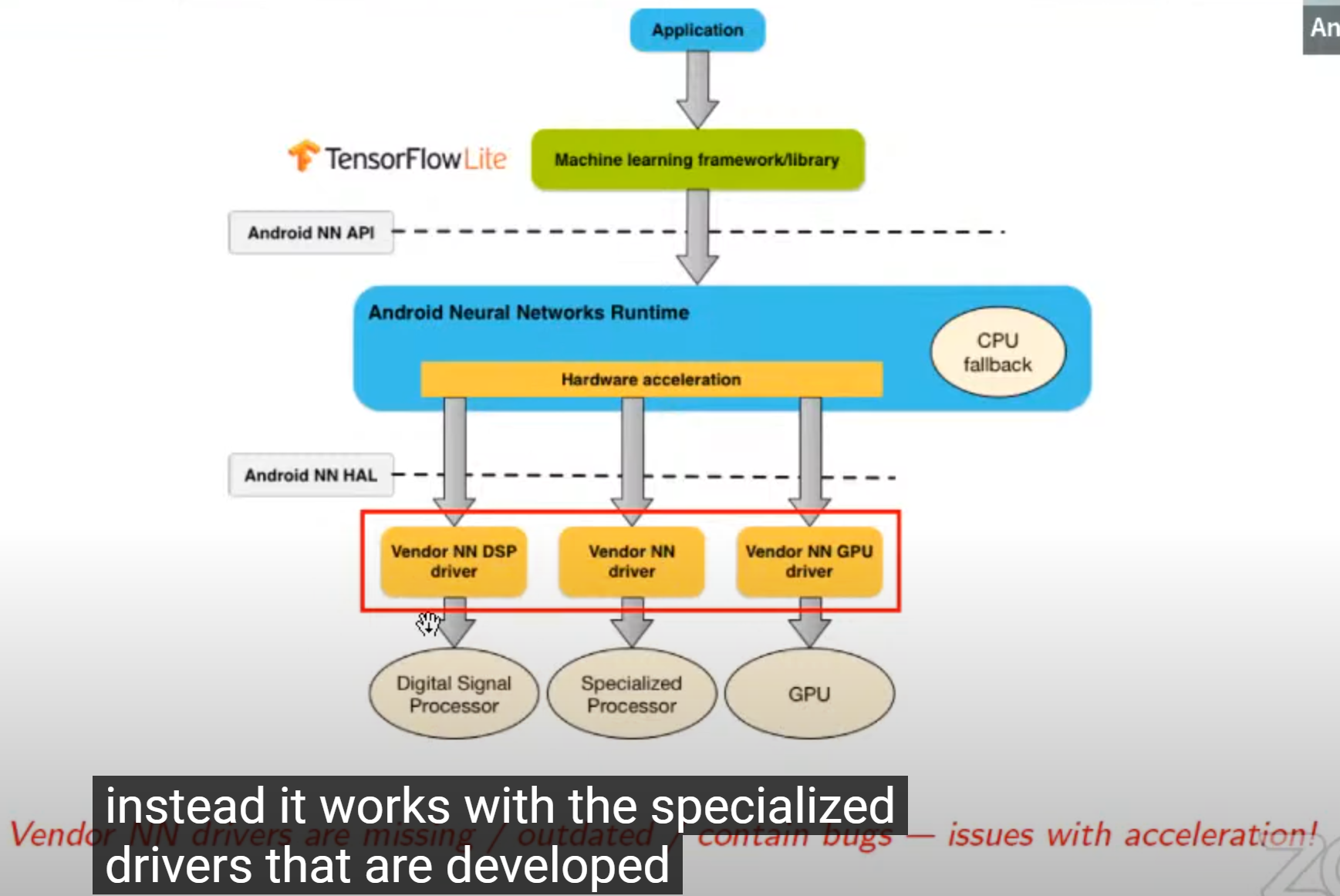
- con 1:NNAPI HAL碎片化现象严重

- 生态很差,各种driver和版本各行其道(api难对齐;可能有bug;结果不一致)
- con 2:只支持一定数量的TFLite op
- TensorFlow Lite Delegate:
- 本质上是vendor给不同soc提供的lib?
- pros:
- 使用便捷,只需要把binary lib粘到proj(还是其他什么地方)里?
- 独立于Android OS sys (version),能在任何支持OpenCL的GPU上加速推理,对于一些古老机型也能有用
- 大多数架构都能加速,能支持大模型(上GB的ram)
- Pytorch Mobile:
- op覆盖广;CPU加速效果明显;依赖于NNAPI;不太推荐
- 推理类型
- 不同推理类型
- FP32
- balabala…1符号位+8指数位+23分数位;NPU不支持FP32
- FP16
- 1符号位+5指数位+10分数位;在所有mobile lib中FP32->FP16自动发生;
- Int8
- 几乎对所有硬件都能加速推理,减少RAM消耗,提高能效;许多mobile NPU只支持Int 推理;
- 在图像分类任务中works well
- 在SR这类简单的图像处理任务重works so-so
- 在ISP&NLP中不work
- 一些Int8类型
- Dynamic range quantization: 精度高,没加速效果
- 伪量化(参数从int换回float再运算)
- Full integer quantization: 精度高,没加速效果
- 输入输出和一些op没有量化
- Integer only:精度最低但是能在所有INT8的NPU上跑
- Dynamic range quantization: 精度高,没加速效果
- 几乎对所有硬件都能加速推理,减少RAM消耗,提高能效;许多mobile NPU只支持Int 推理;
- Int16
- FP16的良好替代,尺寸不变但是可以整数推理;
- 没有显著的精度问题,适合图像处理;
- 许多NPU不支持,TFLite不支持;
- 一些chipset
- Qualcomm Chipsets
- Classic Hexagon DSPs
- Hexagon Tensor Processor(HTP)
- Hexagon Tensor Processor(HTP)v2
- Qualcomm Hexagon TFLite Delegate
- 支持所有含有classic NN-Compatible Hexagon DSP的Qualcomm SoC
- op支持覆盖比NNAPI好
- 任务性能好
- 一些厂商不允许外部调用Hexagon DSP;即将被弃用;
- (看起来是升级版)Qualcomm QNN TFLite Delegate
- 支持带Hexagon HTP的Qualcomm SoC;支持Qualcomm Adreno GPU的推理;
- op支持和覆盖好;runtime result好;有很多performance & power consumption 的trade-off选项;
- 但是经典Hexagon DSP的支持还不到位,即将不支持老版的Hexagon DSP
- MediaTek Chipsets
- MediaTek Neuron TFLite Delegate
- Samsung Chipsets
- Huawei Chipsets
- Google Chipsets
- 总结:
- 大部分没有NPU
- Qualcomm Chipsets
- Benchmark
- IOS 生态
- AI hardware的一些关键要素
- 计算资源(TOPs/TFLOPS, etc.)
- 支持不同推理类型(FP16, INT8, …)
- 支持op
* TensorFlow Lite CoreML Delegate
- Burnout
Talk1: Mobile AI Trend and Power Performance Metric
by Allen Lu, Jimmy Chiang from Mediatek
- Mobile AI application Evolution
列了个发展趋势,挺有意思的: - 2017-2018 Perception - Face Unlock
- 2018-2019 Construction - Photo bokeh(背景虚化)
- 2019-2020 Quality - Image noise reduction(原来这个已经过时了?)
- 2020-2022 Motion - Video & Game frame rate conversion(加上时间轴,计算量++,比如插帧)
-
2023-2025 depth - VR & MR 3D interaction

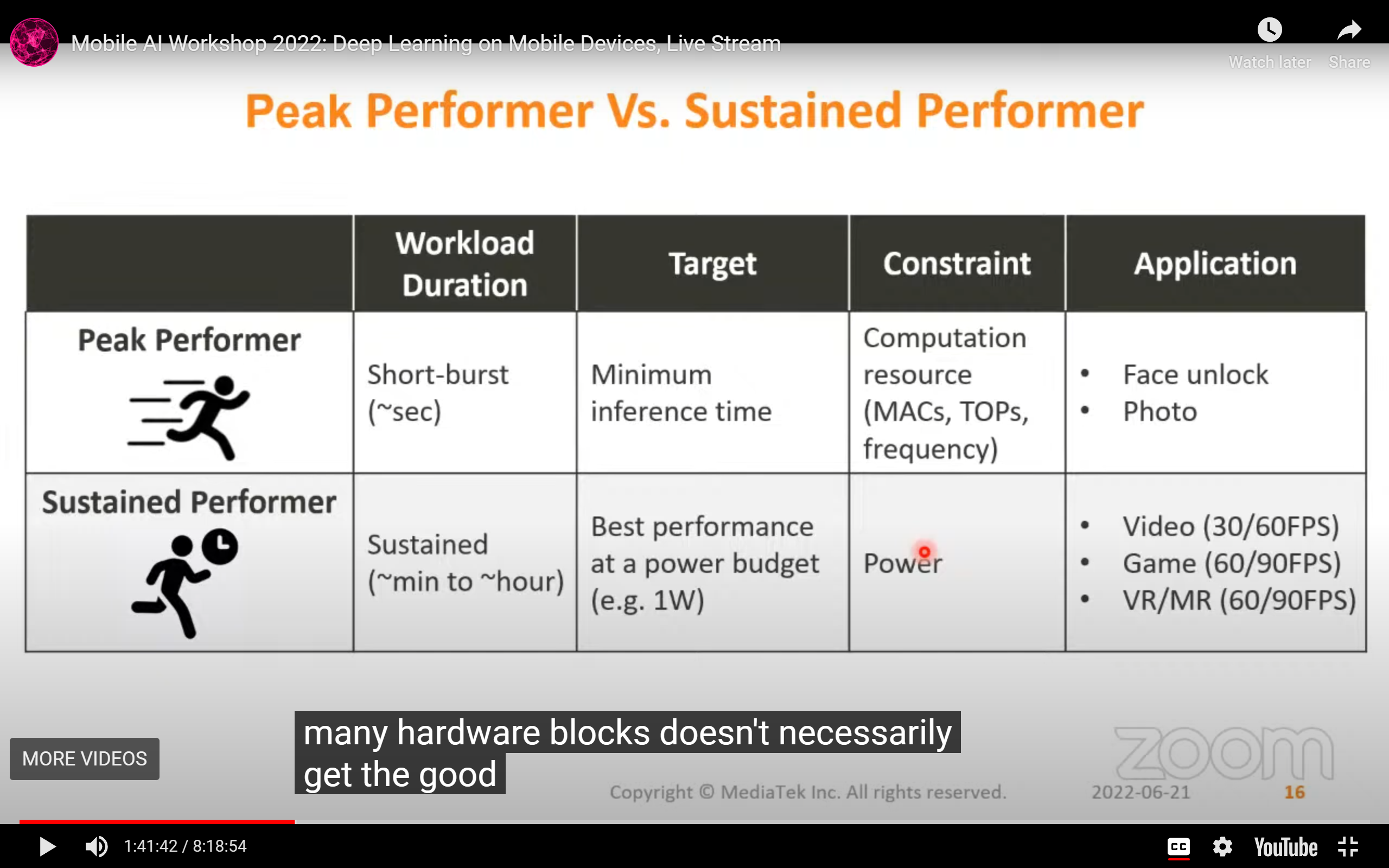
- 最重要的insight:Mobile AI app最重要的是sustainable ability (在一定能耗下达到指定的帧率,延时是对"瞬时任务"而言的):

Talk4:SyNAP framework: Optimizing the AI model inference on the Edge
by Abdel Younes from Synaptics
-
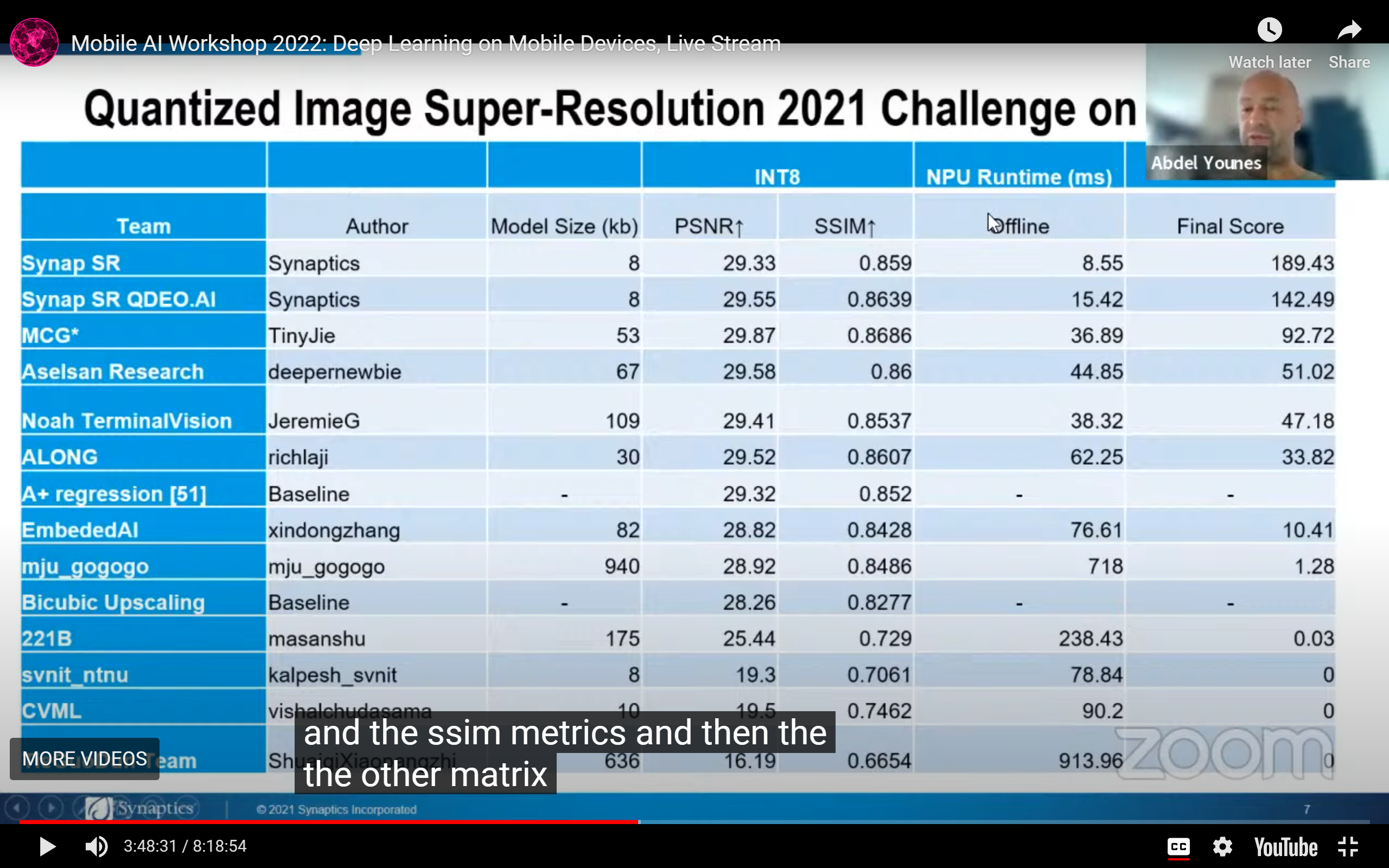
用NN做超分是因为它能比传统的CV方法好,最关心的还是帧率:

-
对于工业应用,延时需求远大于性能需求:
Talk6: Denoising as a Building Block for Imaging, Inverse Problems, and Machine Learning
by Peyman Milanfar from Google Research
-
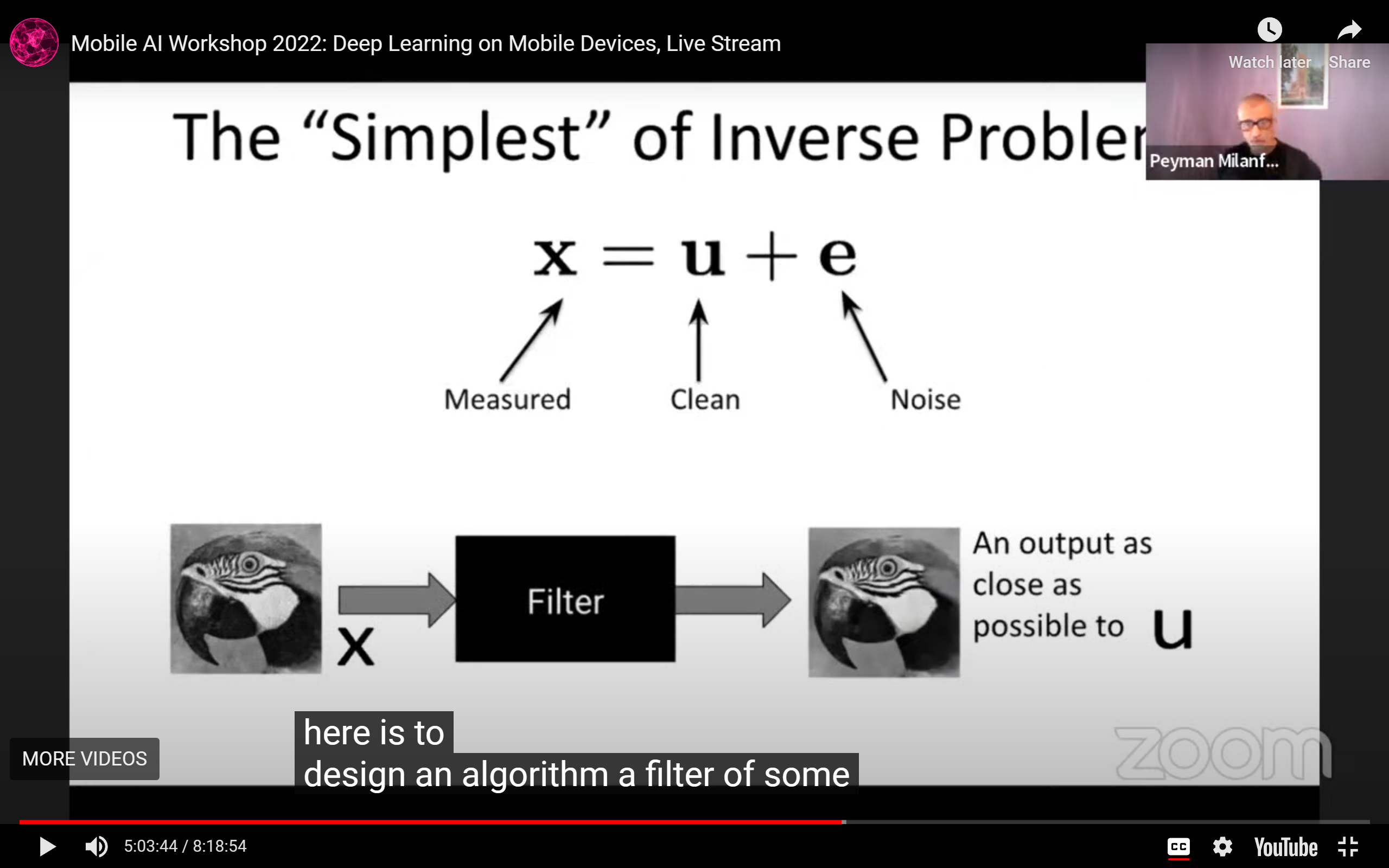
图像去噪的基本定义:
-
手机上的图像去噪任务性能已经很好了:

-
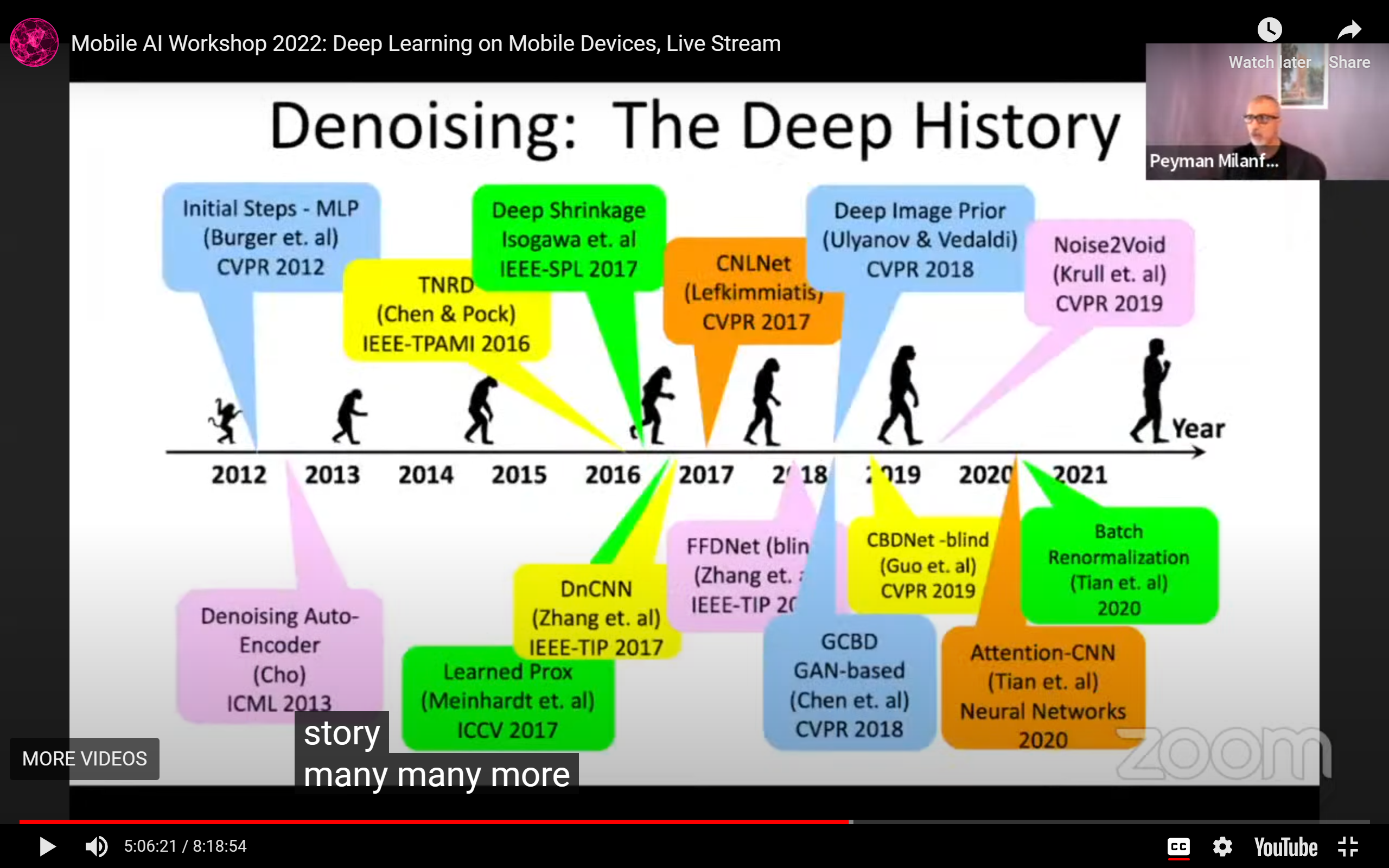
上古图像去噪timeline:

-
图像去噪:死过一次:
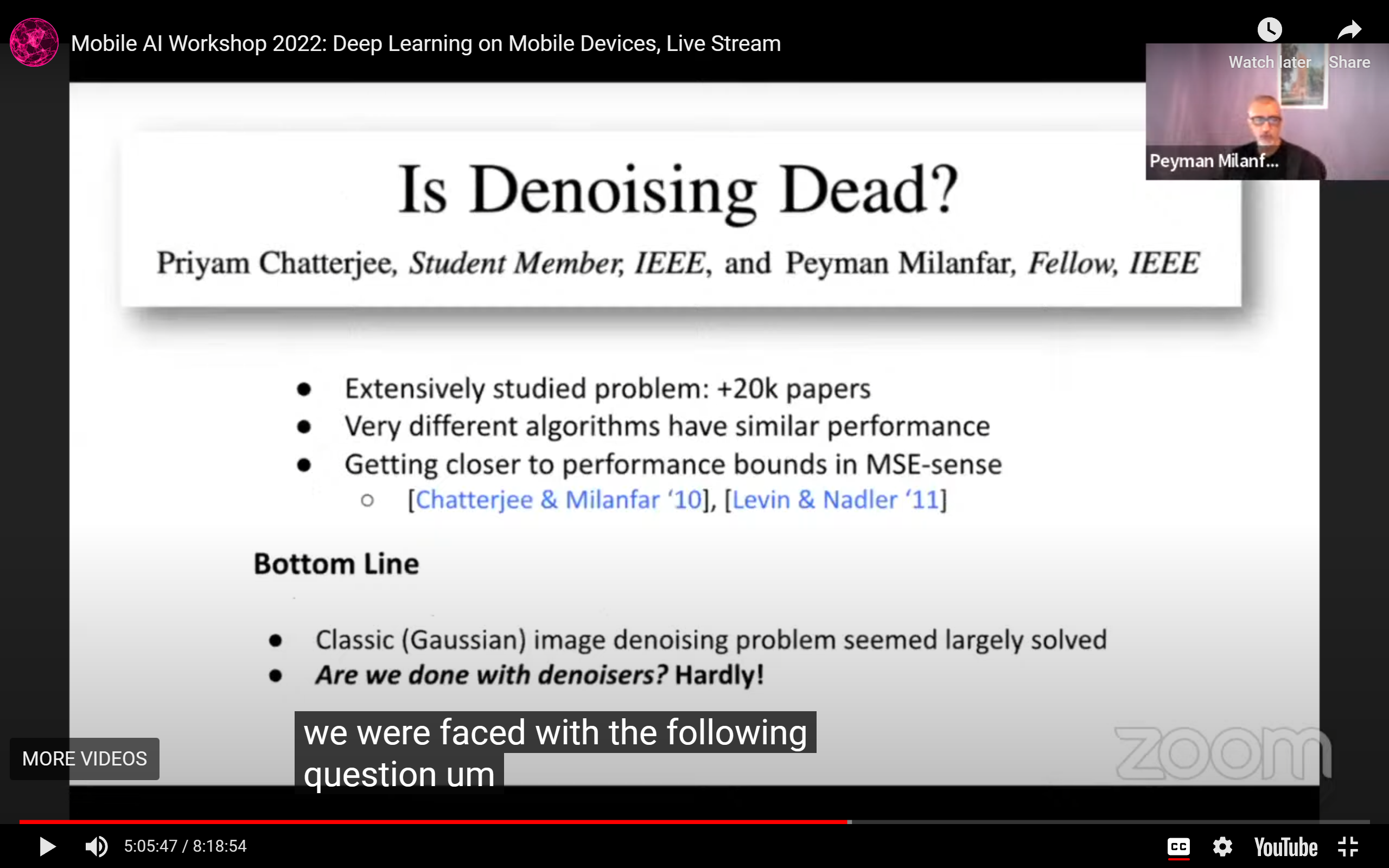
- DL救了一次图像去噪:
- 目前的这些算法在L2意义上已经非常好了
- 去噪器有许多其他用途,例如:

- 解其他非定适问题(图中的例子是用中位数filter做deblur)
- 作为其他NN的building block(这里提了diffusion);
- 可以视为一种非线性低通滤波器:

- Denoiser as "perfect reconstruction image decomposition":

- 似乎提了一种用denoiser做图像处理的pipeline;
- 在图像上应用n次去噪器,可以展开成:

- 用去噪器做图像处理的pipeline(building block),为什么不直接end-2-end训一个网络出来呢?

- 意思是可以复用组合起来?

- 去噪器的分类:

- pseudo-linear,伪线性,pixel之间权重加权:
TRBAYA336DE(G%5D6%7EYVMH.png)

- 贝叶斯去噪器:
-
分成MAP去噪器:
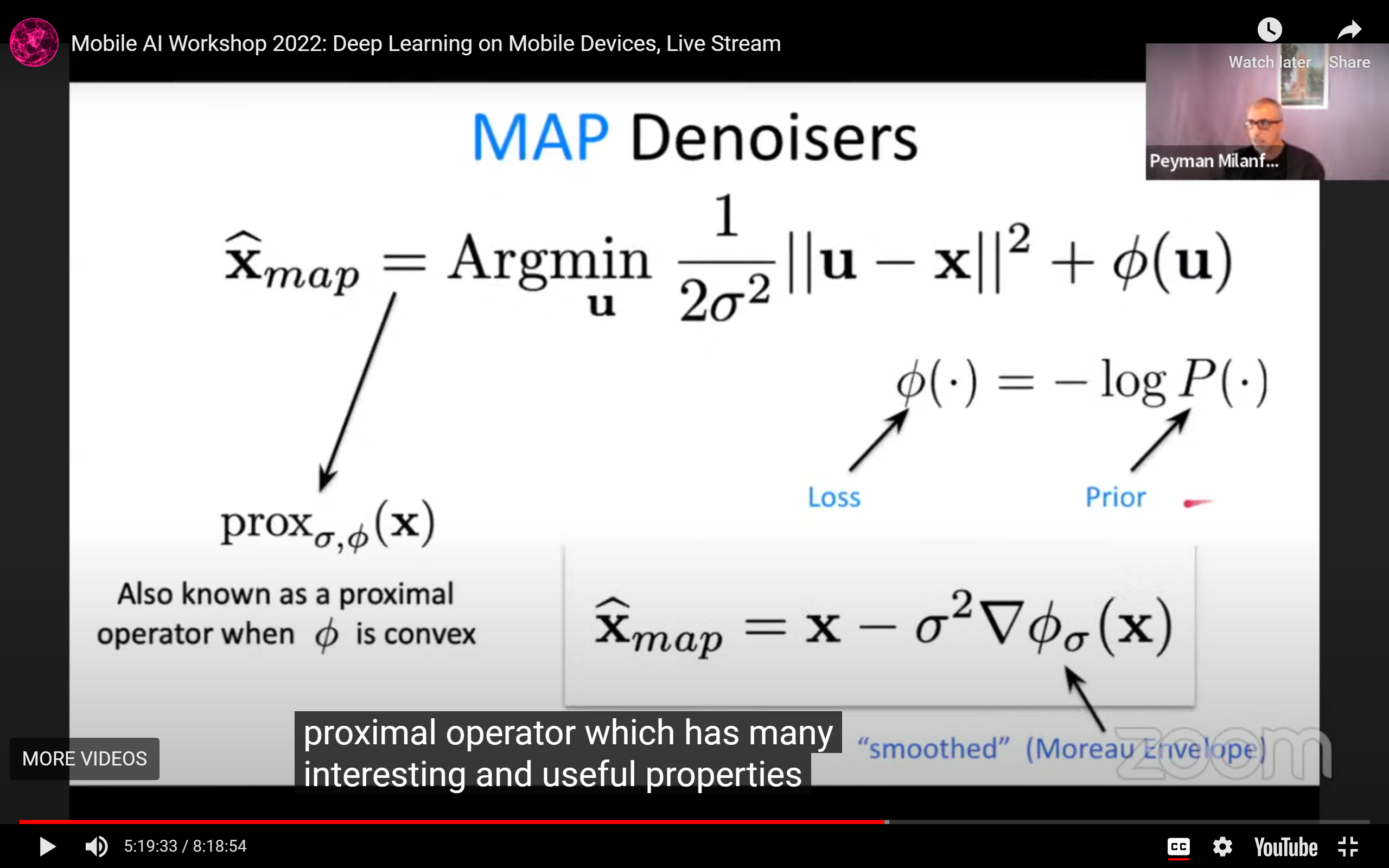
-
和MMSE去噪器:

-
-
总结:去噪器可以写成x^ = x - f(x)的形式:

- 结论:好的去噪器可以学习图像流形的局部几何(diffusion是个应用):

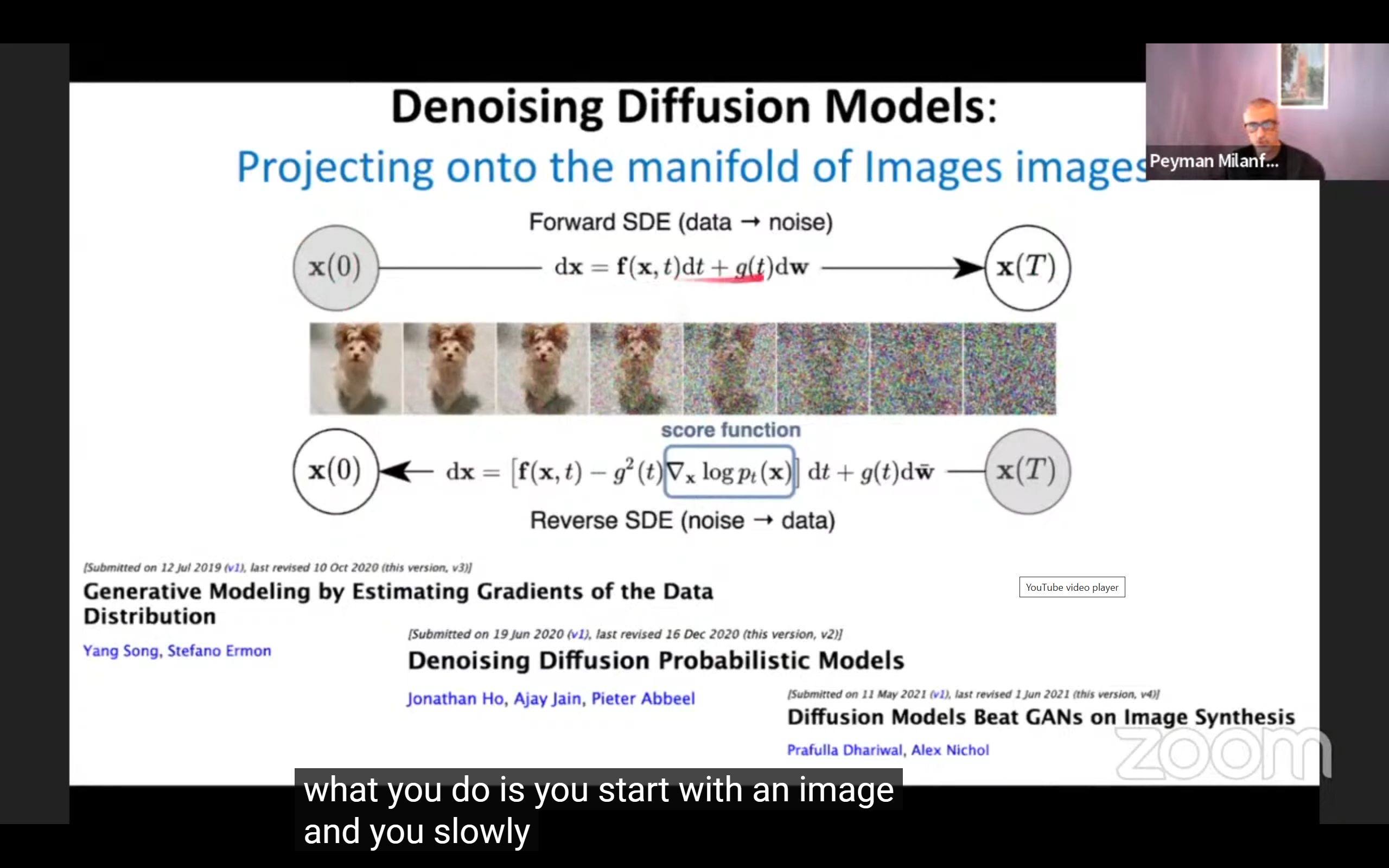
- pseudo-linear,伪线性,pixel之间权重加权:
Paper2: RenderSR: A Lightweight Super-Resolution Model for Mobile Gaming Upscaling
- 对于超分任务,单独Y通道训练要比RGB三通道训练差(理所应当?)
- 在游戏渲染中可以获得depth数据,补充为RGBD数据后训练效果会更好:
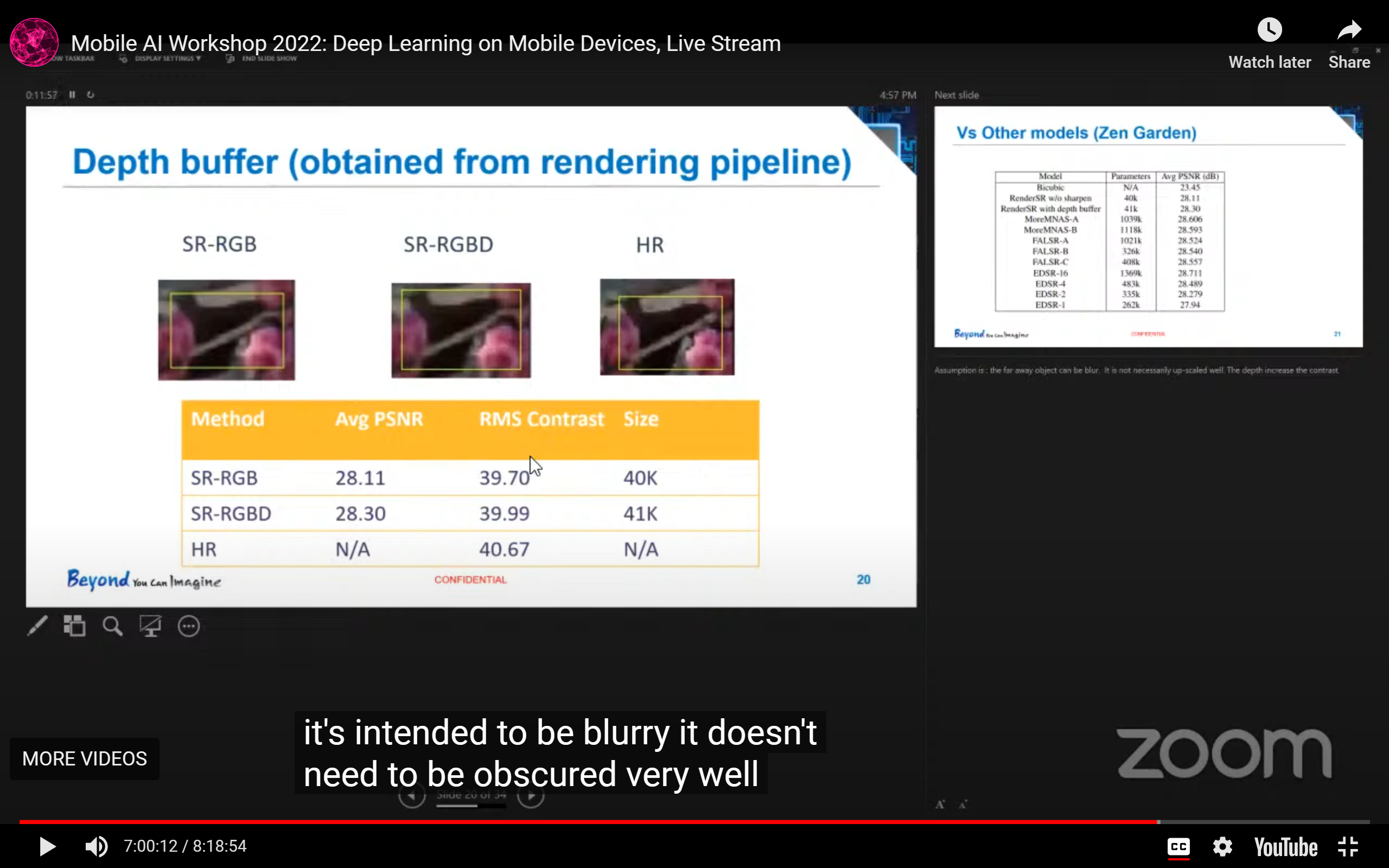
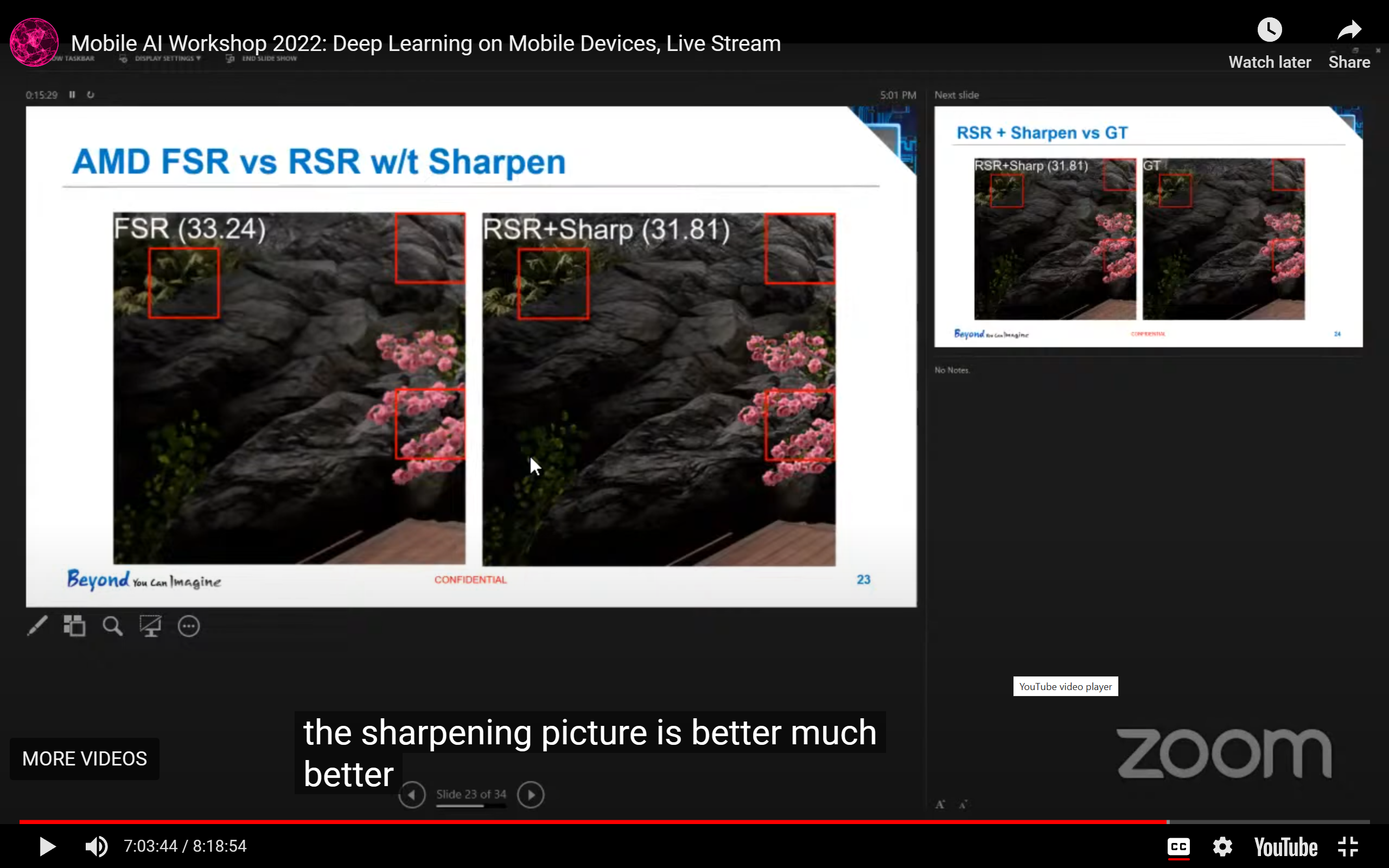
- 在游戏渲染中,边缘锐化可能会让PSNR数值下降,但是视觉效果会更好:
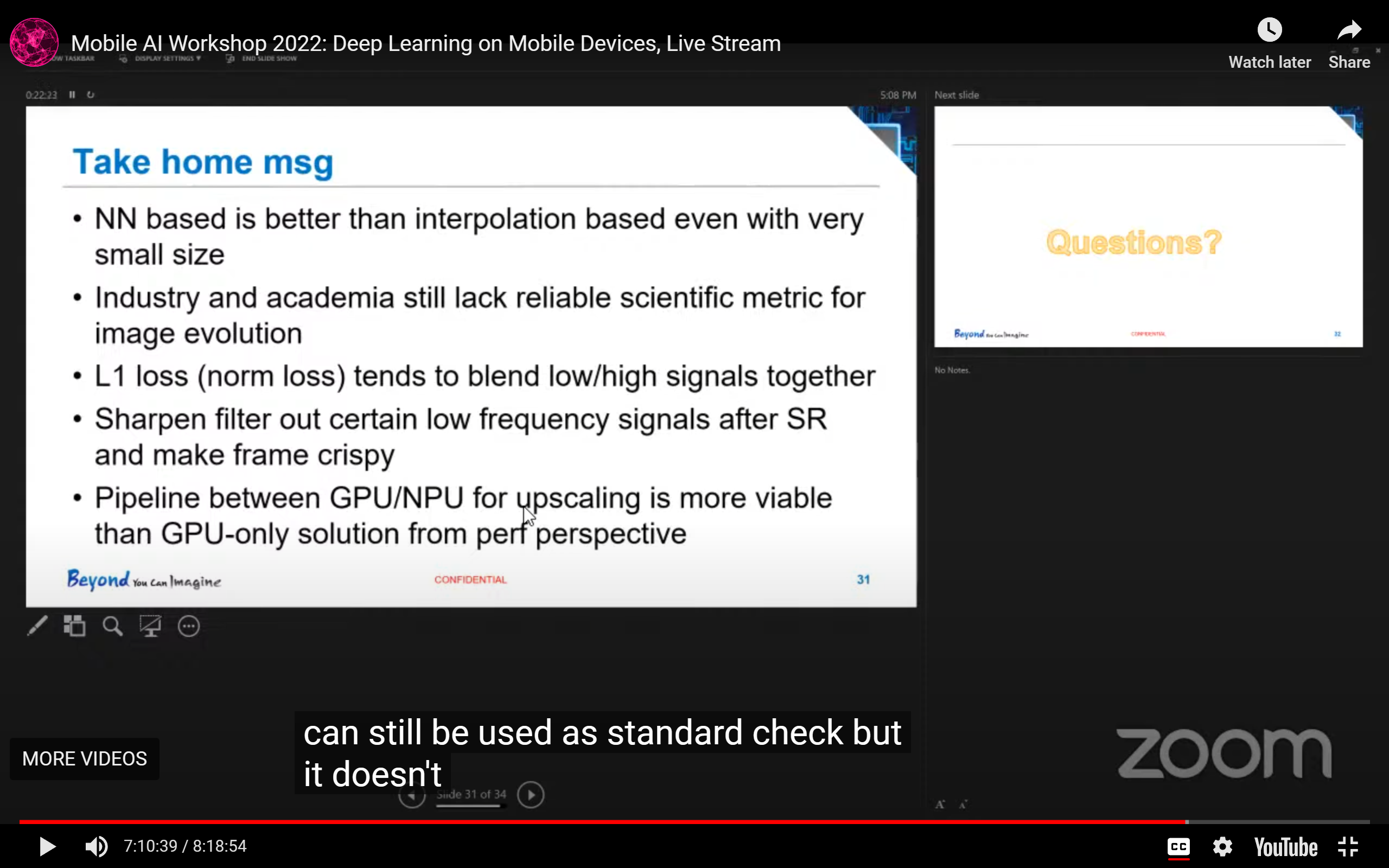
- 一些take home message:
Paper3: An Efficient Hybrid Model for Low-light Image Enhancement in Mobile Devices
-
提供了一些效率数字,内存开销小于500MB,1440*1080的图像帧率应大于15:

-
老生常谈:传统方法速度快(?)效果差,NN-based方法效果好速度慢需要采集数据:

-
提出的策略:混合传统方法 + NN-based方法:

-
一些在端侧部署LLCV模型的经验:

- 普通Conv2d和可分离Conv2d有性能效率trade-off;
- loss func上讲的什么没听清(大意是metric不够有效?);
- 双线性上采样和Deconv效果差异不大;
- 在低光增强任务上,用max pooling可能会有过曝;
- 可分离Conv2d + padding可能会在边缘出现artifact(用reflect padding能缓解这个问题);
- 如何利用Raw数据(Y,U,V通道,结合其中的语义信息)还需要研究;
-
IQA仍然是个关键问题:
