Unprocessing Images for Learned Raw Denoising
2021/12/13
来源:CVPR19
resource:github上备份的包括ipad标注的pdf版本。
作者是Google和UC Berkeley的Tim Brooks, Ben Mildenhall, Tianfan Xue, Jiawen Chen, Dillon Sharlet, Jonathan T. Barron等人,做得还不错,scholar上160+引用。
Summary:一篇还不错的论文,把ISP的流程讲得比较清楚,而且介绍了我关心的PG Noise Model。文章思路非常简单,就是将sRGB图像还原成raw(手工inverse pipeline),在raw里面加噪声,再通过pipeline还原成sRGB图像成pair,进行监督训练,后面的CycleISP就是在这篇文章的基础上改的吧,把前后向pipeline改成网络,但是不知道为啥我读到后面感觉有点失望,我在期待什么呢233
Key words:
- Noise Model - PG -> heteroscedastic Gaussian
- raw2raw denoise
Rating: 4.0/5.0 还可以,主要是比较全面地介绍了ISP,还讲了我比较关心的PG Noise Model,但是又似乎没有特别合我心意233。
Comprehension: 4.0/5.0 文章思路我清楚了,但是一些细节没有弄清楚,主要是ISP的组件,我实在没有经验。
用一张图总结全文:
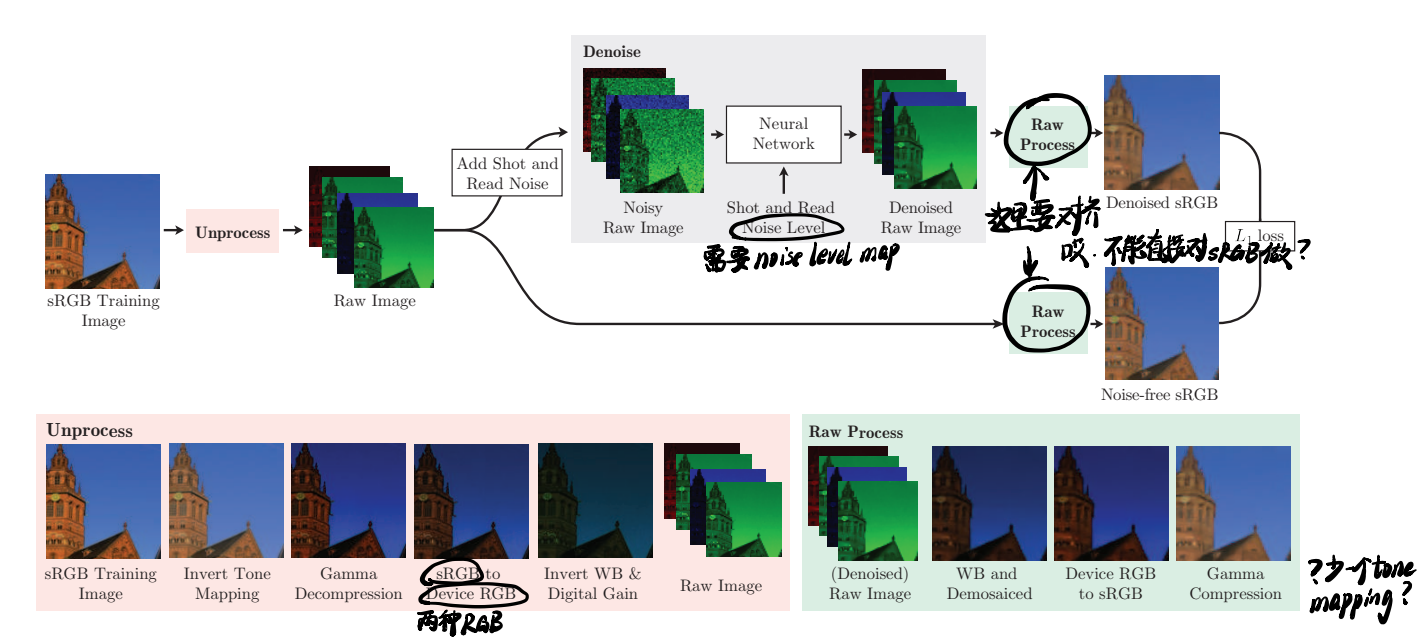
Motivation
在Introduction里讲了,勉强还不算硬凑的:从合成数据到真实数据的泛化需要考虑①相机传感器的噪声属性和②ISP的影响,但是一般的工作只考虑了前者。(但是理论上之前的合成噪声工作都只是在sRGB图像上加高斯噪声啊)
2 Related works
很不错的survey!写出了发展脉络!
大概可以分成四个阶段,但总之是从简单的分析方法转向数据驱动的方法:
- 第一阶段的工作如anisotropic diffusion、total variation denoising、wavelet coring,这些方法假设信号和噪声都表现出特定的统计性质,采用手工设计的算法从噪声图像中恢复出纯净图像,这些方法简单有效,但是这些参数模型(parametric models) capacity和expressiveness有限;
- 接着是nonparametric、self-similarity-driven的方法,例如BM3D、non-local means;
- 然后出现了dictionary-learning 和basis-pursuit algorithms,也是在分析方法->数据方法的转变中,例如KSVD和Fields-of-Experts,"operate by finding image representations where sparsity holds or statistical regularities are well-modeled";
- 最后是现在的数据方法/基于学习的方法。
爆杀了一波高斯合成噪声的方法:These datasets enabled the observation that recent learned techniques trained using synthetic data were outperformed by older models, such as BM3D
新视角——成pair数据的另一个缺点(除了贵):难以捕捉运动物体(水、云、生物等)。
据说这篇文章ISP讲得不错,有空学下:Burst photography for high dynamic range and low-light imaging on mobile cameras
3 Raw Image Pipeline
3.1 Shot and Read Noise
先介绍了他们的PG(heteroscedastic Guassian)噪声模型,对于shot&read noise的定义我想起来应该在网管ECCV20论文里读到过。
- 一个常识:raw域的噪声比sRGB域的噪声容易刻画;
- shot noise - photon arrival statistics; read noise - imprecision in the readout circuitry;
- 下面的公式搭配着网管的图应该更好理解(那么为什么不直接去读网管的文章呢233):

- 还是PG->异方差高斯分布,$\lambda_{read}$和$\lambda_{shot}$分别是模拟和数字增益,这两个增益由相机设定,直接作为ISO light sensitivity的函数,具体的数值可以在特定曝光下测试出来,作为元数据和raw file储存在一起。
- 为了给定合成数据的噪声等级,作者从从DND图像里建模了shot/read噪声的联合分布(那么我应该能从SID图像里找到类似的元数据?):
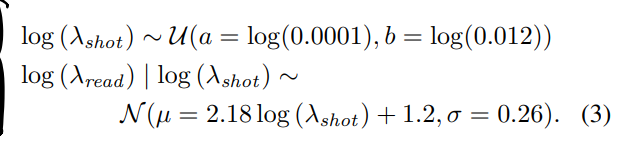
- 以及它对应的一张图:
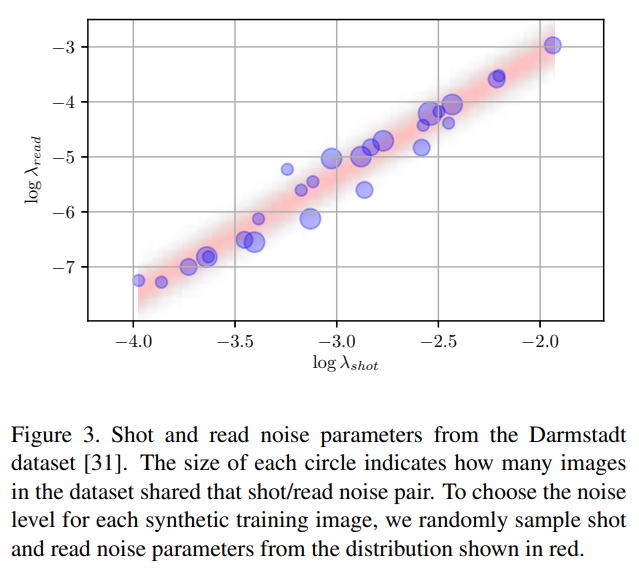
- 以及它对应的一张图:
3.2 Demosaicing
去马赛克/彩色插值 - 很好理解,Bayer pattern -> RGB.
inverse方法忽略不计,下同。
3.3 Digital Gain
对图像亮度的处理,和曝光时间相匹配,这一块看得尤其迷惑,但是不重要:

3.4 White Balance
相机记录的图像是光线的色彩乘以物体的色彩,白平衡的作用是去掉光线颜色的影响,让它看起来更像自然光照下的情况,具体会对蓝色和红色通道乘以一个系数。考虑到digital gain和white balance环节的增益乘积通常小于1(inverse时就大于1),这会导致还原raw图中高亮部分缺失,所以又额外设计了一个变换函数。
3.5 Color Correction
从device RGB变换至sRGB。具体做法是用一个3 × 3 color correction matrix (CCM),不过似乎每个相机/传感器会对应一个这种矩阵。
3.6 Gamma Compression
因为人眼对亮度的感知和物理功率不成正比,所以要压缩一部分人眼不敏感的区间,给人眼敏感的low intensity pixel分配更宽的动态范围。
3.7 Tone Mapping
进行大幅度的对比度衰减,将场景亮度变换到可显示的范围,同时尽可能保留图像中的细节。
4 Model
网络是个残差学习的U-Net,同时输入noise level map作为辅助信息:
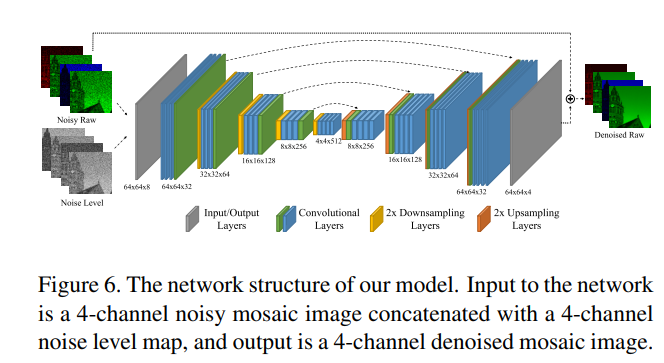
4.4 Training
一些细节:
- 合成的基底是MIR Flickr,降采样2x以减少噪声等的影响;
- 做了sRGB和raw两个track,Abstract里强调的对loss的改进实际上就是在denoise之后又过了遍ISP,只是这个ISP看起来可导;
5 Results
结果:
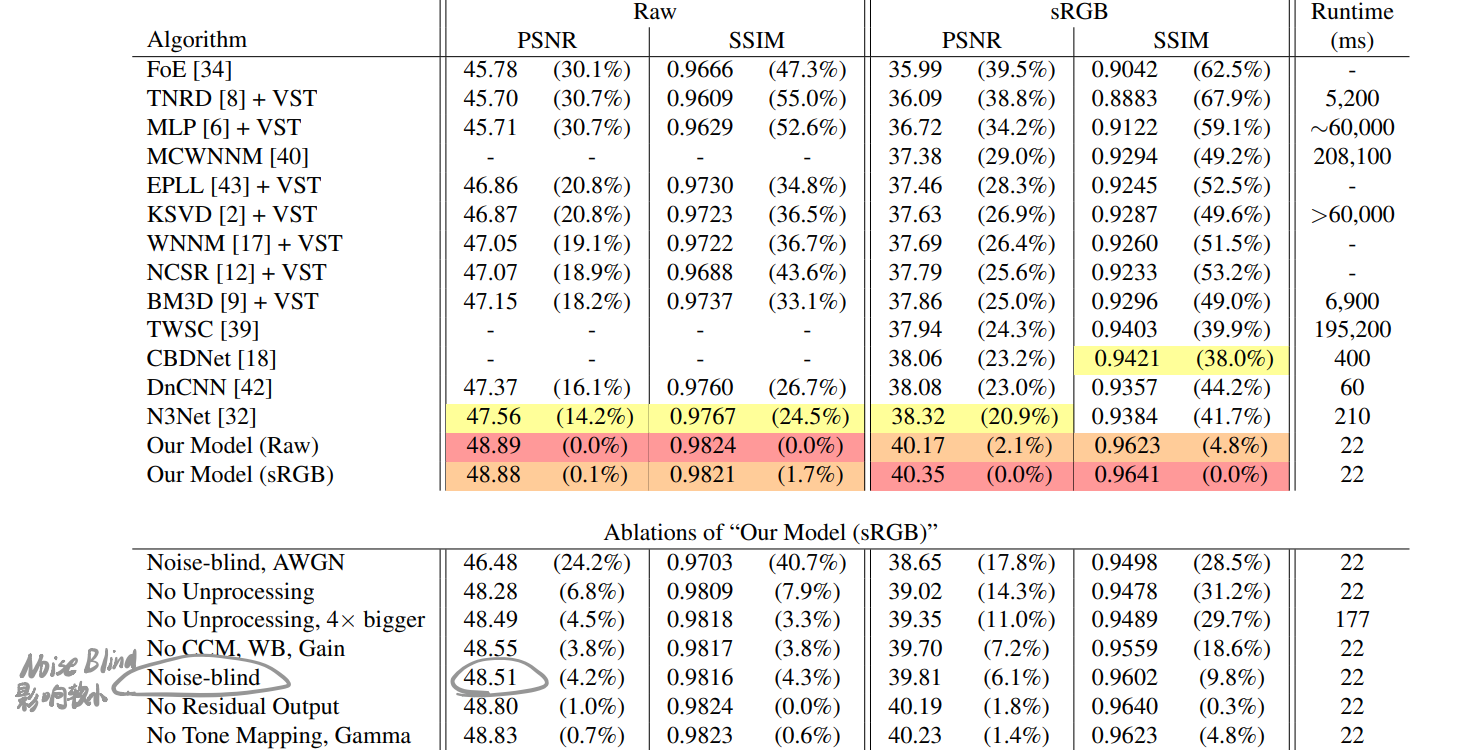
发现blind-denoise效果差不多。
然后有两个新指标,看起来可以让结果好很多:
- RMSE
- DSSIM