STONNE: Enabling Cycle-Level Microarchitectural Simulation for DNN Inference Accelerators
2023/9/5
来源:IISWC21
resource:github上备份的包括ipad标注的pdf版本。
Summary & Takeaways
- 背景:新一代AI加速器支持多种层类型、支持灵活的dataflow、稀疏计算与数据依赖的计算模式,正在逐渐取代第一代"rigid"加速器。传统的基于分析建模的形式已经不能满足这类新型加速器的仿真需求,所以提出了本文所设计的时钟级、模块化的加速仿真器STONNE。
- 设计了一种模块化的时钟级AI加速器仿真器STONNE,现已开源:https://github.com/stonne-simulator/stonne
- 基于C++实现,能够实现时钟级的推理性能仿真;
- 参考现有加速器的模块化方式,将整个架构拆解成"Distribution Network"、"Multiplier Network"、"Reduction Network"与配套的"memory controller"、"buffers"等若干模块,各模块可独立开发与互相组合,以灵活支持不同架构的AI加速器;
- 和现有的深度学习框架Pytorch结合,将现有DL框架作为前端,该模拟器作为实际执行计算的计算后端(作用等同于pytorch中的
device),实现了功能级仿真。
- 个人评价:
- 很有价值的开源AI加速器仿真器,既有研究又有工程实用价值;
- 模块化设计与时钟级仿真的实现都非常straight forward。
STONNE Framework & Details
- STONNE框架与计算流
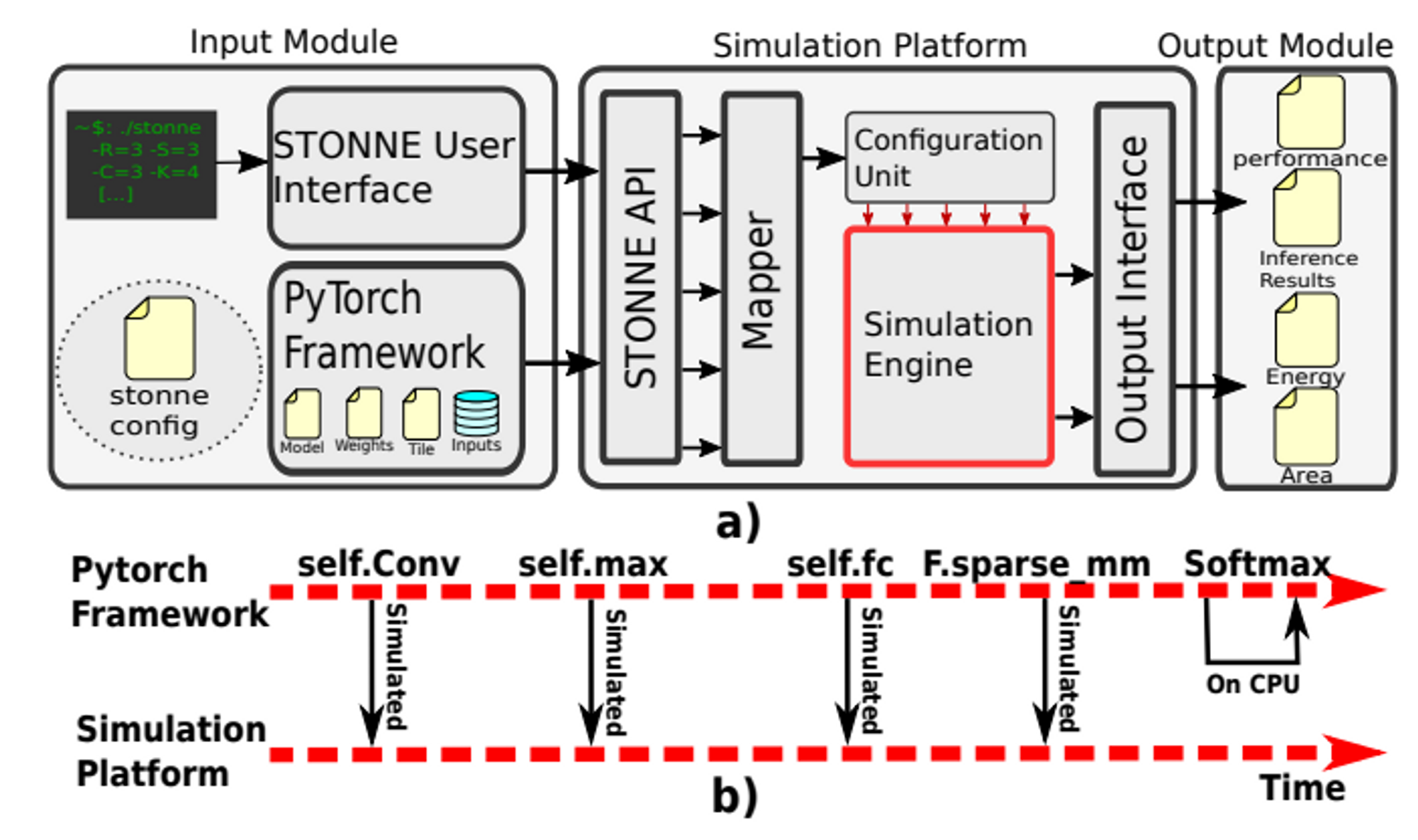
- 整个框架可以分解成三个部分:Input Module, Simulation Platform, Output Module
- Input Module: STONNE框架调整了Pytorch框架,在Pytorch框架内添加了STONNE仿真引擎作为计算后端,用户需要调整前端中DNN的定义方式(追加指定的STONNE仿真计算后端与对应的配置文件)、提供预训练的权重和模型输入、以及提供待仿真的加速器的硬件配置文件;
- Simulation Platform: 根据配置文件生成仿真引擎(simulation engine),其中仿真引擎又由若干可配置的微架构模块构成。用户传入硬件配置(各个微架构模块的选择与相应参数),结合DNN layer的类型与数据尺寸,由mapper映射成对应的配置信息,再由configuration unit实例化成仿真引擎。
- Q:DNN的编译发生在什么位置,Mapper吗?
- Output Module: 当某一层的计算完成后,由该模块提供性能仿真结果。性能仿真结果包括performance、计算单元利用率、活动计数(wires, FIFOs, SRAM等);仿真器会根据活动计数与各个活动对应的LUT来计算能耗和面积。LUT是根据Synopsys DC & Cadence Innovus测出来的。
- 基本的仿真流程:如上图(b)所示,在pytorch框架中按层执行DNN时,需要模拟的计算负载会加载到仿真引擎上进行计算。
- 仿真平台(Simulation Platform)的实现细节
- STONNE根据先前文献的分隔方式,将加速器拆解成以下三个模块"Distribution Network"、"Multiplier Network"、"Reduction Network",与相应的"memory controller"、"buffers",并分别建模:
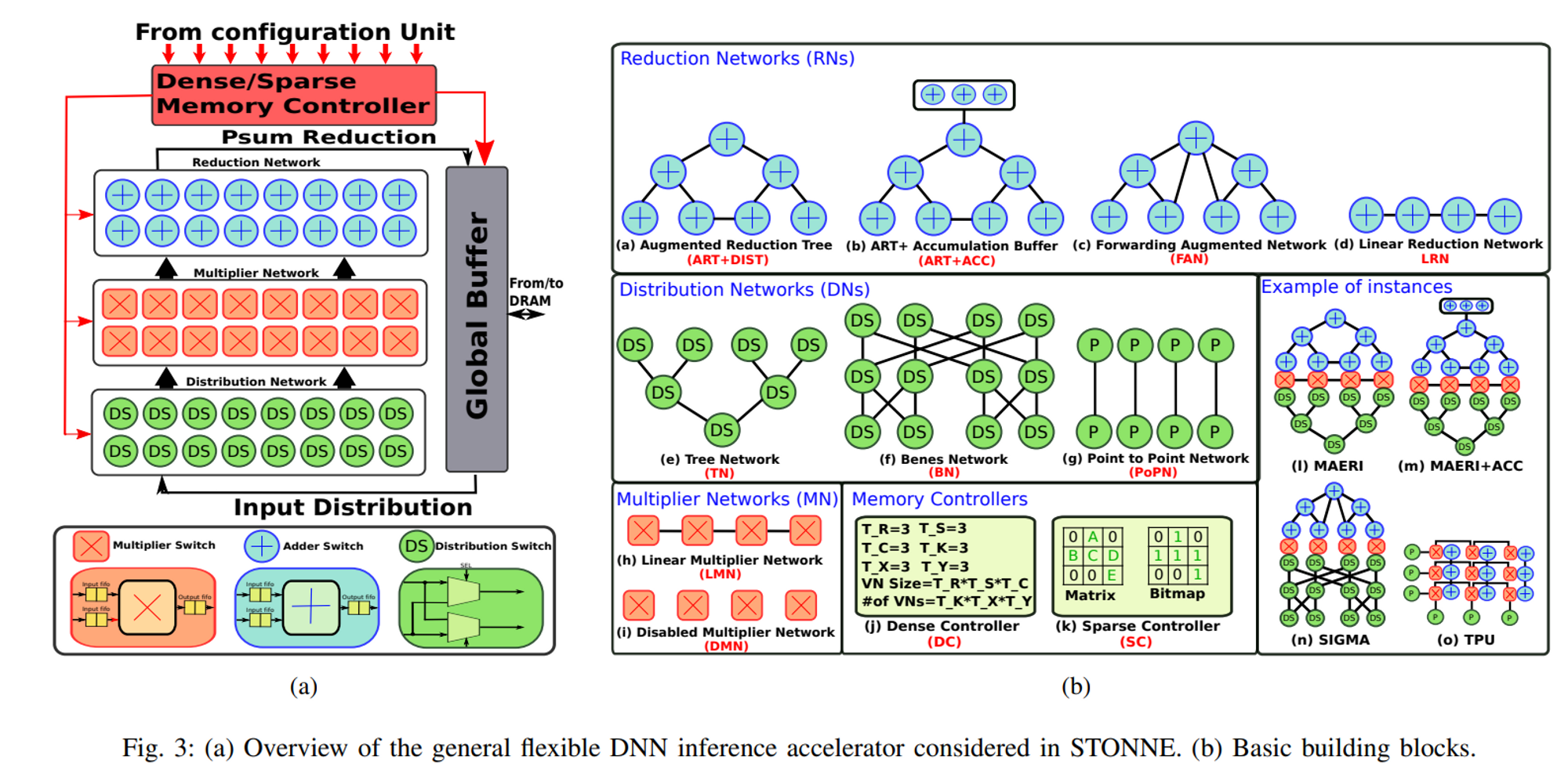
- Distribution Network: 负责从全局buffer取数据到乘法器网络,目前支持以下三种类型:
- Tree Network (TN)
- Benes Network (BN)
- Point to Point Network (PoPN)
- Multiplier Network: 由乘法器开关(Multiplier Switches, MSs)构成,可以实现forwarder(将部分和由GB直接传入RN) or multiplier(W与A运算)功能,支持以下类型:
- Linear Multiplier Network (LMN)
- Disabled Multiplier Network (DMN)
- Reduction Network: 加法器网络,用于累加部分和。支持以下类型:
- Reduction Tree (RT) and Augmented Reduction Tree (ART+DIST)
- ART + Accumulation Buffer (ART+ACC)
- Forwarding Augmented Network (FAN)
- Linear Reduction Network (LRN)
- Memory hierarchy: 包括local storage, on-chip global storage, off-chip DRAM三层,可由用户配置带宽、FIFO尺寸、GB(Global Buffer)尺寸、DRAM尺寸等。GB和DN/RN之间的数据调度由memory controller实现,根据数据的稀疏情况分成dense controller和sparse controller两类。
- 各个模块均含
cycle()函数,用来模拟该模块在一个时钟周期内的行为。最顶级的Accelerator类在仿真时会迭代调用其每个组件的cycle()函数,来实现时钟级别行为的拟真。
- STONNE根据先前文献的分隔方式,将加速器拆解成以下三个模块"Distribution Network"、"Multiplier Network"、"Reduction Network",与相应的"memory controller"、"buffers",并分别建模:
- 整个框架可以分解成三个部分:Input Module, Simulation Platform, Output Module
Experiments
提供了三个使用案例来展示STONNE对AI加速器的仿真能力:
- Evaluation of DNN inference in TPU, MAERI and SIGMA
- 建模了三个经典的AI加速器,TPU, MAERI和SIGMA,仿真其性能、能量开销和芯片面积,并和先前的工作对照结果。
- Back-End Extension for Data-Dependent HW Optimizations
- 建模数据依赖型的加速器SNAPEA以说明STONNE后端的可拓展性。
- Front-End Extension for Filter Scheduling in Sparse Accelerators
- 证明STONNE对稀疏网络推理的支持能力。