A Survey of Quantization Methods for Efficient Neural Network Inference
2021/6/7
来源:arxiv2021.4.22(Book Chapter: Low-Power Computer Vision: Improving the Efficiency of Artificial Intelligence)
resource:github上备份的包括ipad标注的pdf版本。
作者是Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer,都是不认识/不熟悉的名字呢…不过有资格写综述的大概都是行业大佬?以后请多指教(?)
Summary:关于量化的纯知识性的文章,不过关注点似乎放在了inference阶段(大概和训练量化并列吗),有点可惜,而且里面的分类感觉和非神经网络的量化没什么大区别?真就移植呗?
Rating: 4.0/5.0
Comprehension: 5.0/5.0
1 Introdution
首先是经典的模型压缩方法分类,包括设计高效的NN结构、协同设计NN结构和硬件、剪枝、知识蒸馏、量化、量化和神经科学(玄学范畴)。
第II部分的历史介绍基本上没用,一些琐碎的点:
- Rounding and truncation(舍入和截断)是量化的典型方式。
- 一些新名词:
- well-posed problem(适定问题) & well-conditioned problems
- numerical stability
- forward error & backward error
但是II.A部分神经网络量化的历史还有点意思:
NN量化问题的一些新特性:
- NN的训练和前传都需要消耗大量的计算资源,因此需要好好量化表示(?不是废话?)
- NN有大量的冗余参数(heavily over-parameterized),提供了一种新的"自由度",因此对量化甚至是极端量化比较鲁棒,量化过程不会对精度有太大影响。在NN量化里,我们想解决的不是某个well-posed or well-conditioned problem,因为前传有特殊的度量(比如交叉熵) + 参数有冗余,能达到我们希望的目标(前述度量损失较少)的模型不止一个,因此可能量化后的模型和原来的模型有较大的差别,但是性能仍然很好。
- NN的分层结构使得mixed-precision成为可能。
III Basic Concepts of Quantization
III.A. Problem Setup and Notations
III.B. Uniform Quantization(均匀量化)
III.C. Symmetric and Asymmetric Quantization(对称量化和非对称量化)
- 选择截断区间(clipping range)的过程被称作校正(calibration)。
- 对称量化在量化参数中比较常用,因为"zeroing out the zero point"(大概意思是零点在区间中点?)可以减少前传中的计算花销。
- 有一个量化区间选择的讨论。即最大最小值(受到离群值的影响)还是percentile等。
- 结论比较空洞:对称量化使用对称的量化区间,易于实现,但是对非对称的值不友好。
III.D. Range Calibration Algorithms: Static vs Dynamic Quantization(动态量化区间和静态量化区间)
- 结论(同样空洞):动态量化区间通常结果比较准确,但是需要消耗计算资源,静态反之。
III.E. Quantization Granularity(量化粒度)
大概意思是按照不同分组选量化区间/量化方法:
- Layerwise Quantization(分层量化,每个层中的所有通道都用同一种量化方法)
- Groupwise Quantization(多个channel绑起来做一个量化)
- Channelwise Quantization(每个通道同一种量化方式/量化区间)
- Sub-channelwise Quantization(一个通道内的一组参数绑起来,更细粒度)
结论:现在channelwise的多些。III.F. Non-Uniform Quantization(非均匀量化)
- 量化间隔和量化值(量化的结果)都不是均匀排布的(绝对吗?)。
- 对于给定比特带宽非均匀量化accu会更高些(当然了。。量化区间的划分也是信息啊)
- binary-code-based quantization(二进制编码量化) - 指数量化阶的代表。
- rule-based v.s. optimization-based quantization(基于规则的量化和基于优化的量化),此外聚类clustering也可以用于减少量化的信息损失。
- 结论:非均匀量化可以通过分配非均匀地比特和离散区间来更好地捕捉信号信息,但是这种非均匀量化的方法往往难以部署到CPU/GPU上,因此均匀量化因其简洁性是de-facto的量化方式。
III.G. Fine-tuning Methods(调优方法)
两种重要的分类:Quantization-Aware Training(QAT) & Post-Training Quantization(PTQ).
比较重要的图:
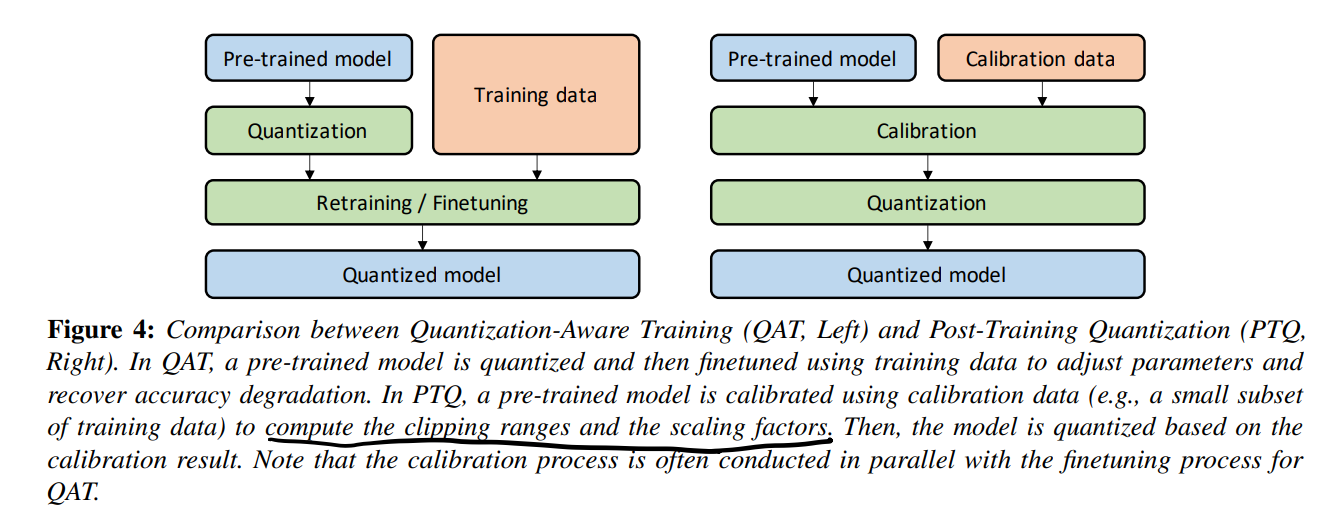
QAT里(倒不如说也有pretrained model)pretrained model先被量化然后再和训练数据一起调优。PTQ里用部分训练数据去算截断区间和缩放因子,接着量化。
- QAT:
- STE是主流方法,同时还提出了随机神经元方法(stochastic neuron approach)、组合优化(combinatorial optimization)、目标传播(target propagation)、Gumble-Softmax等方法。
- 结论:QAT点更高些,但是重训花时间太多,对于一些生命周期短的模型不太友好(不会吧,不会真有这么短命的模型吧!)
- PTQ:
- PTQ的精度相比QAT稍微拉一些,但是除了训得快之外别有只需要部分数据的好处。
- Zero-shot Quantization(ZSQ): 完全不需要训练数据,哈人。(可以利用BN里存储的统计数据来生成数据)
III.H. Stochastic Quantization(随机量化)
可以参考的随机量化形式:

IV. Advanced Concepts: Quantization Below 8 Bits
IV.A. Simulated and Integer-only Quantization(模拟量化和整型量化)
量化的模型还可以分成simulated quantization(fake quantization,模拟量化)和integer-only quantization(fixed-point quantization,整型量化/定点量化)。模拟量化中的参数用低精度存储,但是在计算之前需要去量化,计算还是用浮点算(感觉只是节约存储空间,不能减少运算/甚至会增加运算)。
- 在integer-only quantization里有个工作把BN混到了Conv里(看样子这种工作很早就有人探索过了啊)。
- Dyadic quantization(二价量化)是integer-only quantization的一种,这种量化在运算的时候只需要整数加、乘、移位,不需要整数除法。具体做法是:
...all the scaling is performed with dyadic numbers, which are rational numbers with integer values in their numerator and
a power of 2 in the denominator
- 结论:simulated quantization并不是一无是处,在bandwidth-bound的场景中(比如推荐系统)更有用些。
IV.B. Mixed-Precision Quantization(混合精度量化)
IV.C. Hardware Aware Quantization(硬件感知量化)
IV.D. Distillation-Assisted Quantization(蒸馏辅助量化)
IV.E. Extreme Quantization(极端量化/二值量化)
IV.F. Vector Quantization(向量量化)
聚类的感觉,大概是找几个向量当聚类中心这样。
V. Quantization And Hardware Processors
Don't Care.
VI. Future Directions for Research in Quantization
感觉总有些牵强:
- Quantization Software:software packages,这种工具链还能算发展方向?
- Hardware and NN Architecture Co-Design
- Coupled Compression Methods
- Quantized Training