Hardware-Aware Efficient LLCV
2022/5/3
记录一下本次投稿的一些思考。
TODO-List
2022/5/3 update
目前需要考虑的几个问题:
- 方法设计
- 目前的peak mem估计方法是否合理
- 从优化的角度来看应该足够,peak mem的分析和我们能优化的空间一致(我们除此外也无法优化其他部分,不在本层能力范围内);
- 从实际应用来看内存估计偏低,推理框架会额外预留大量内存空间(取决于使用的推理框架与模型结构),当前估计结果约为实际情况的1/2;
- 实验现象是,按照Feature Mem Budget算出来的batch size推理,在GPU上Peak Mem显著高于mem budeget(11~15G)
- 实际应用要考虑推理框架,可能不是hardware-blind,需要对估算mem做一定scale,否则需要trial-and-error试出来一个合适的budget?
- 额外带来的困难是,我们
可能来不及在硬件上实际测加速效果(试出来一个合适的mem budget与其对应的batch size时间不可接受)
- 问题是,估计mem和实际mem之间的gap会对我们产生什么影响
- 大故事不会有影响,peak mem是bottleneck,要改进;
- 方法上没影响,我们估计的内容在当前层是充分的,优化对象选择应该没问题;
- 实用性有影响,硬件实验很难开展,问题在于mem与依赖的推理框架紧相关,必须考虑更低一层才能做出来实用的方案,但这种方案通用性又更差。
- patch size需要训练与推理一致(否则会影响Mem估计)。LLCV的practice是分patch训练,整图测试,不过既然我们讲大图切分的故事,那就可以忽略这个事情了?
- 目前的peak mem估计方法是否合理
- 实验与比较
- Oracle实验拓展
- Pipeline形式?
- 怎么比较其他方法 / 需要提供哪些实验结果
- 问题分析:
- (先得有个结果)时间上来不及:这些方法没考虑硬性内存限制,我们得手工分析各个对比对象的peak mem,调出来不同的点,再训练作图;
- (再考虑结果好不好)关注点不同,我们是优化内存的剪枝方法,期待改善内存并提高throughput,其他方法主要刷点;
- 我们的base性能不够,剪枝出来的结果不可能好于原始U-Net,而原始U-Net就已经比较差了,在注重性能的LLCV领域会很吃亏(pruning社区更关心什么?);
- 大表格
- 一些LLCV领域大表格的参考
- 纯刷点类的工作,表格be like:

- 高效架构设计的大表格,be like:
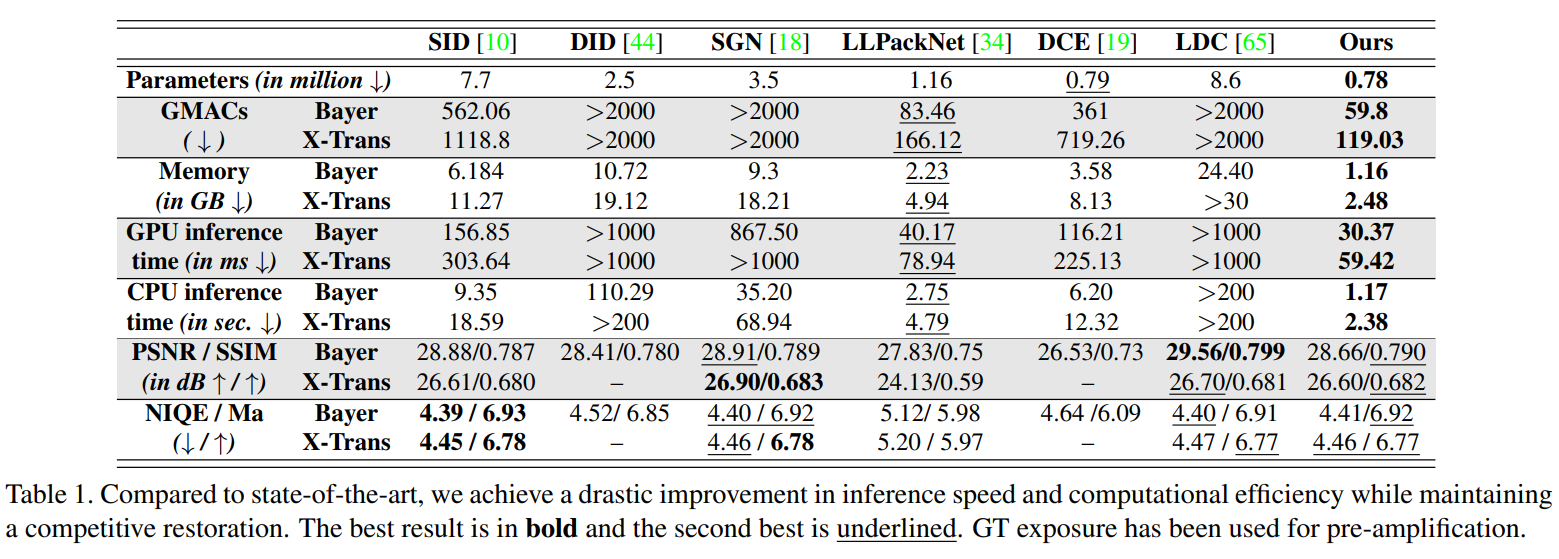
- pruning + LLCV的工作,表格be like:
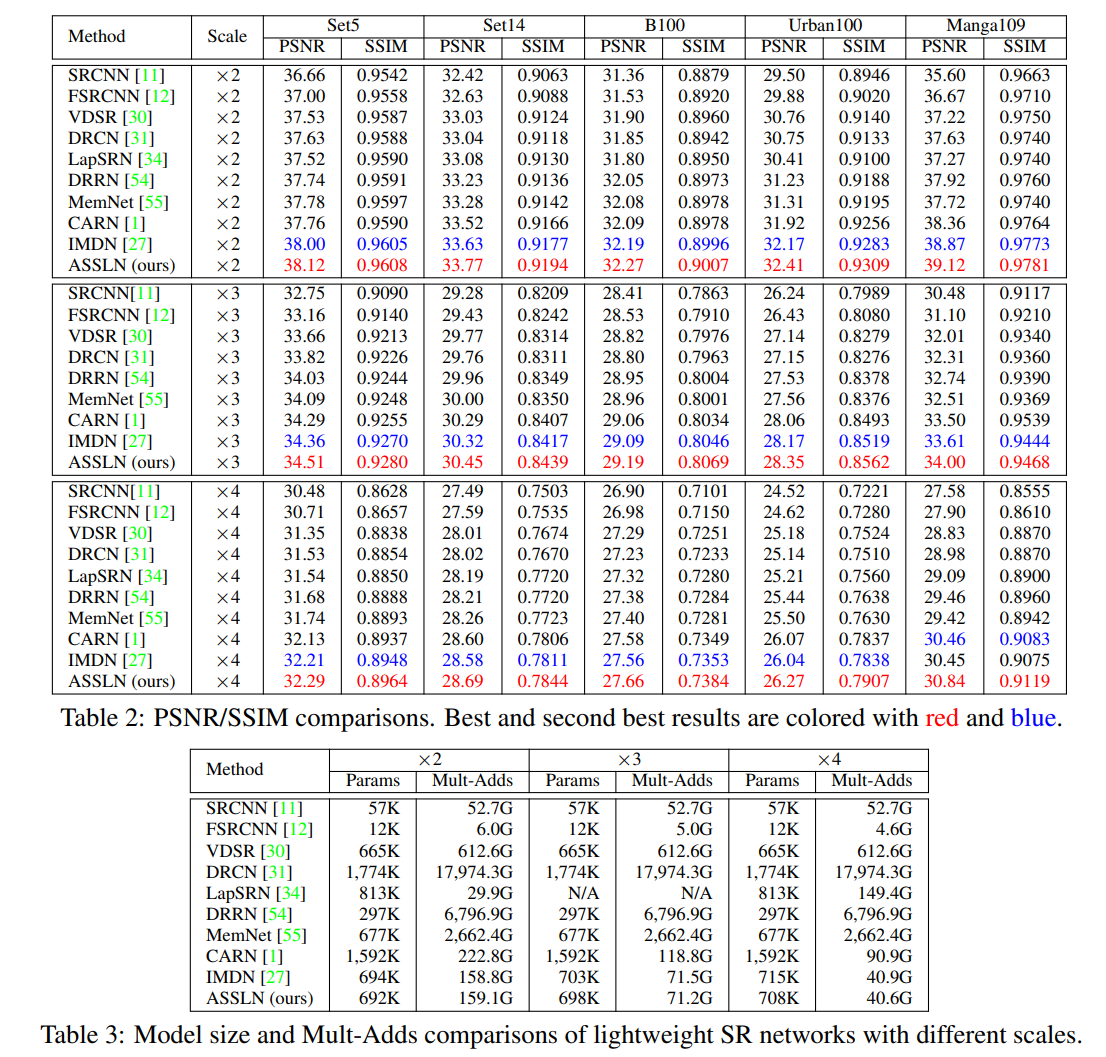
- NAS + LLCV的工作,表格be like:
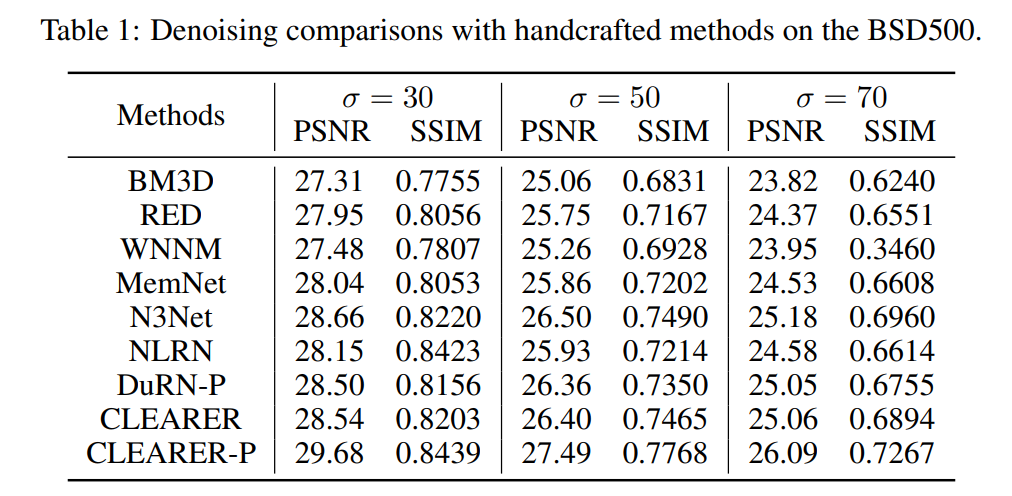
- 纯刷点类的工作,表格be like:
- 问题:
- 如果纯拼性能,我们肯定比不过SOTA(列不成纯刷点类的表)
- 如果对齐peak mem比,我们需要重跑所有baseline,时间上来不及。
- 一些LLCV领域大表格的参考
- 曲线图
- 希望有条pareto曲线展示结果,纵轴性能,横轴整体延时,希望证明我们通过剪peak mem,能在overall latency - task performance中取得一个良好的trade-off / 找到一个更好的pareto frontier
- 难点一:我们没有1E像素的noisy-clean图像对
- 解决方法:能不能找个折中的方法,纵坐标是在数据测试集(例如,真实图像去噪就是SIDD)上的task performance,横坐标还是1E像素的推理时间?
- 这种方式未必只有坏处:对比需要专门的数据集,但是目前没有大图数据集;就算我们手头有少量1E像素图像pair,会被质疑variety不够?现有数据集起码variety不会被喷?
- 难点二:画这种图时间开销很大:
- 每条曲线需要若干点,这些点我们都得自己跑,此外,还需注意:
- 如果比较其他LLCV高效设计模型,我们还得手工分析peak mem,再用均匀scale的方式把peak mem降低、训练不同模型?
- 不同scale的模型 / 不同剪枝率的模型能否连成一条曲线?估计是个trial-and-error的问题;而且打出来的点未必均匀?
- 每条曲线需要若干点,这些点我们都得自己跑,此外,还需注意:
- Cherry Pick 图像细节对比
- LLCV领域常用的占空方法,be like:

- 我们选的三个任务(3 in Real Denoising/Enhancement/Deblur/Derain)各比一个,正文里只放SIDD上cherry pick的图,其他放到Appendix里;
- 预计很好生成,只需要手工挑比较好的图就好,图像crop代码也很好写。
- LLCV领域常用的占空方法,be like:
- 硬件实验
- 难点在真的把不同模型的实际消耗内存对齐到Budget下,分析见方法设计 - peak mem估计
- 问题分析:
- 比哪些方法
- 最基础的均匀缩小
- 经典的剪枝算法剪出来的模型
- 高效设计LLCV模型
- A+B LLCV模型
- Oracle实验拓展
- 文章撰写
- Abstract
- Intro
- Related Work 以下分类是否合适?会不会搬起石头砸自己的脚
- Deep Image Restoration Models
- Lightweight Image Restoration Models
- Pruning / A+B尝试
- Method
- Exp
- Analysis
- Conclusion
- 人员分工
方法准备好后,我们有什么要做的?- 写文章,这个可以分开来吗,比如我和妃哥写,两个学弟不动,还是我们四个人一起写?
- 如果方法验证有望,先把文字都填好,空出来表格和图
- 准备实验,我们的方法、调baseline、硬件实验
- 我们的方法相关
- 能否完全交给立栋来做?需要跑以下实验,在pareto曲线上打若干点;在不同task上对齐后表格中的数据;
- Ablation部分,我们在讨论好Ablation内容后,由他来跑实验、写分析文字;
- baseline(机时、人力)
- 我和恩庶一起,按优先级攒baseline,提供pareto曲线的对比曲线、(如果不直接引的话)表格中的其他点;
- 如果立栋那边挂上了我们的方法,拉他一起?我和恩庶可以准备高效LLCV模型,立栋看些剪枝相关的baseline;
- cherry pick图
- 由恩庶模仿一般的LLCV文章画cherry pick图,给出一小节/一小段的分析文字;
- 硬件实验
- 如果需要硬件分析,讨论后由恩庶执行硬件测试实验,提供表格数据,可能给一小段分析文字;
- 我们的方法相关
- 写文章,这个可以分开来吗,比如我和妃哥写,两个学弟不动,还是我们四个人一起写?