Spatial-Adaptive Network for Single Image Denoising
2021/9/27
来源:ECCV20
resource:github上备份的包括ipad标注的pdf版本。
作者是浙大的Meng Chang, Qi Li, Huajun Feng, Zhihai Xu等人,很奇怪,在他们的网站上查不到这几个人。
Summary:一篇还可以的论文,最近也挺常作为比较对象出现在其他论文中,但是从这篇文章就可以逐渐看出来trick的堆积了。出发点是一般的Conv形状固定,就是从中心pixel出发,去取一个矩形框内的其他pixel进行运算,这样可能难以估计合适的feature(feature的分布不太会是这种规则的形状),因此提出了一种residual spatial-adaptive block,核心是里面挪用的Deformable Conv。此外还有自编码器的网络结构、Context Box的借用。这篇文章讲道理没太多自己的东西,可变性卷积(Deformable Conv)是引自别人的,里面的Context Box也是引的,好像就offset transfer是自己提出来的,感觉作用也很有限。
Key words:
- Fancy Operator(Dilated Conv和Deformable Conv)
Rating: 3.0/5.0 还行吧,主要是些新op的引入,没太有启发意义。
Comprehension: 4.3/5.0 比较简单。
用三张图总结全文:
-
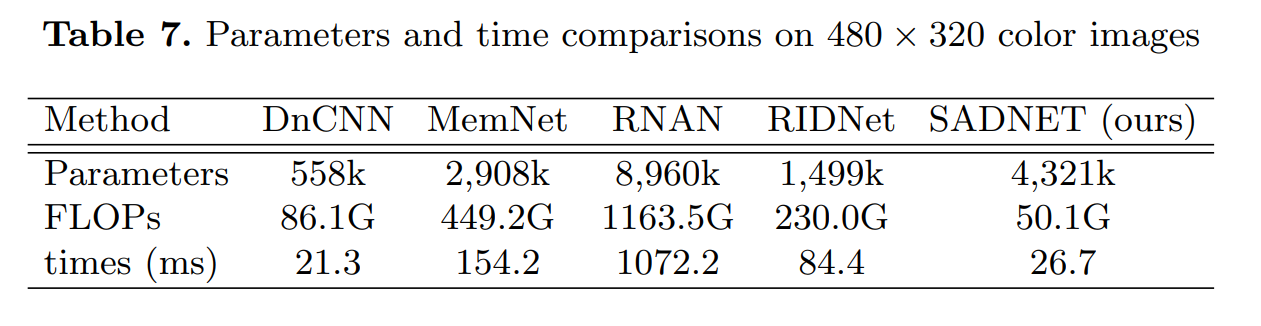
网络的总体结构,采用了一种非对称的building block堆叠方式,但是并不能说是Branched / Enhancement Path,后面知道这其实只是Deformable Conv的支持:
-
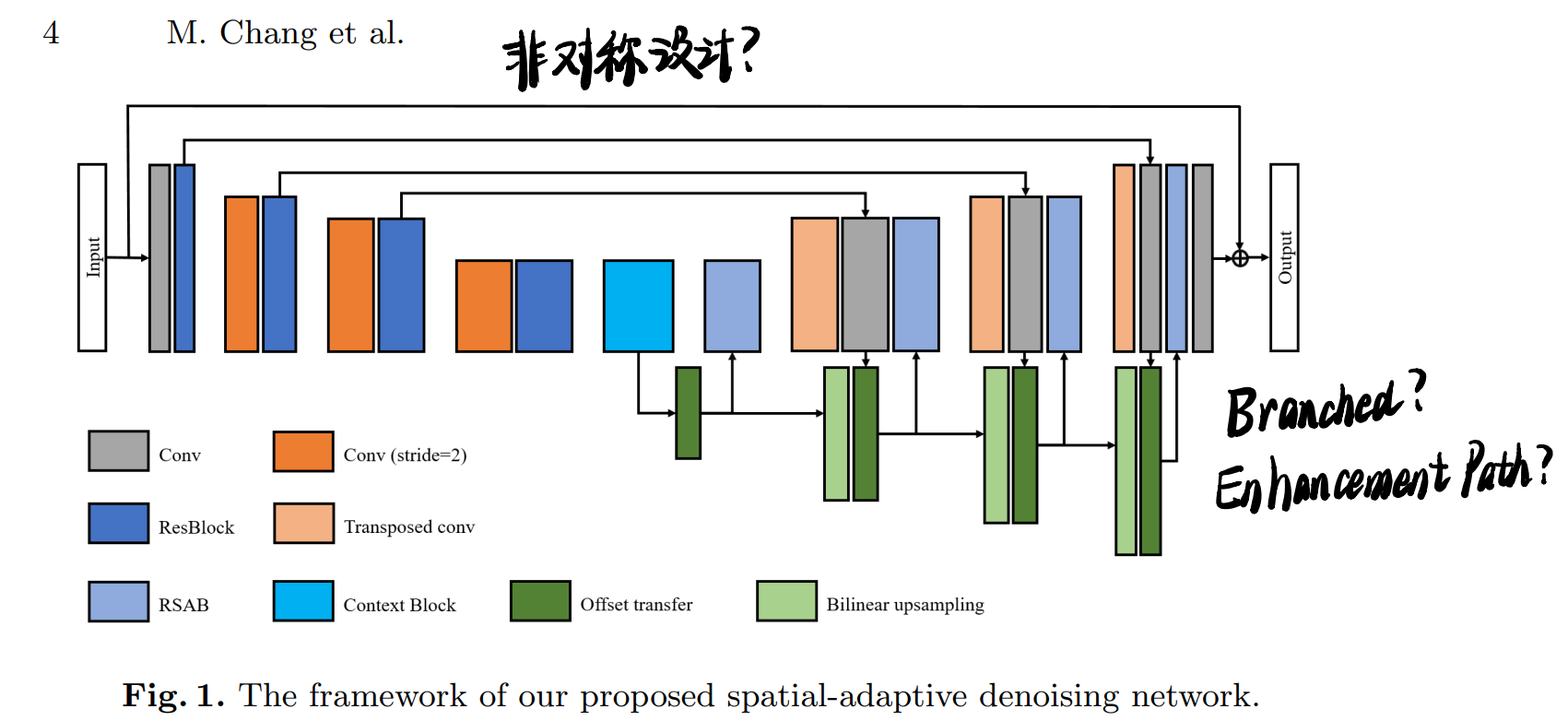
基本的建构块RSAB,画得挺清楚的:
-
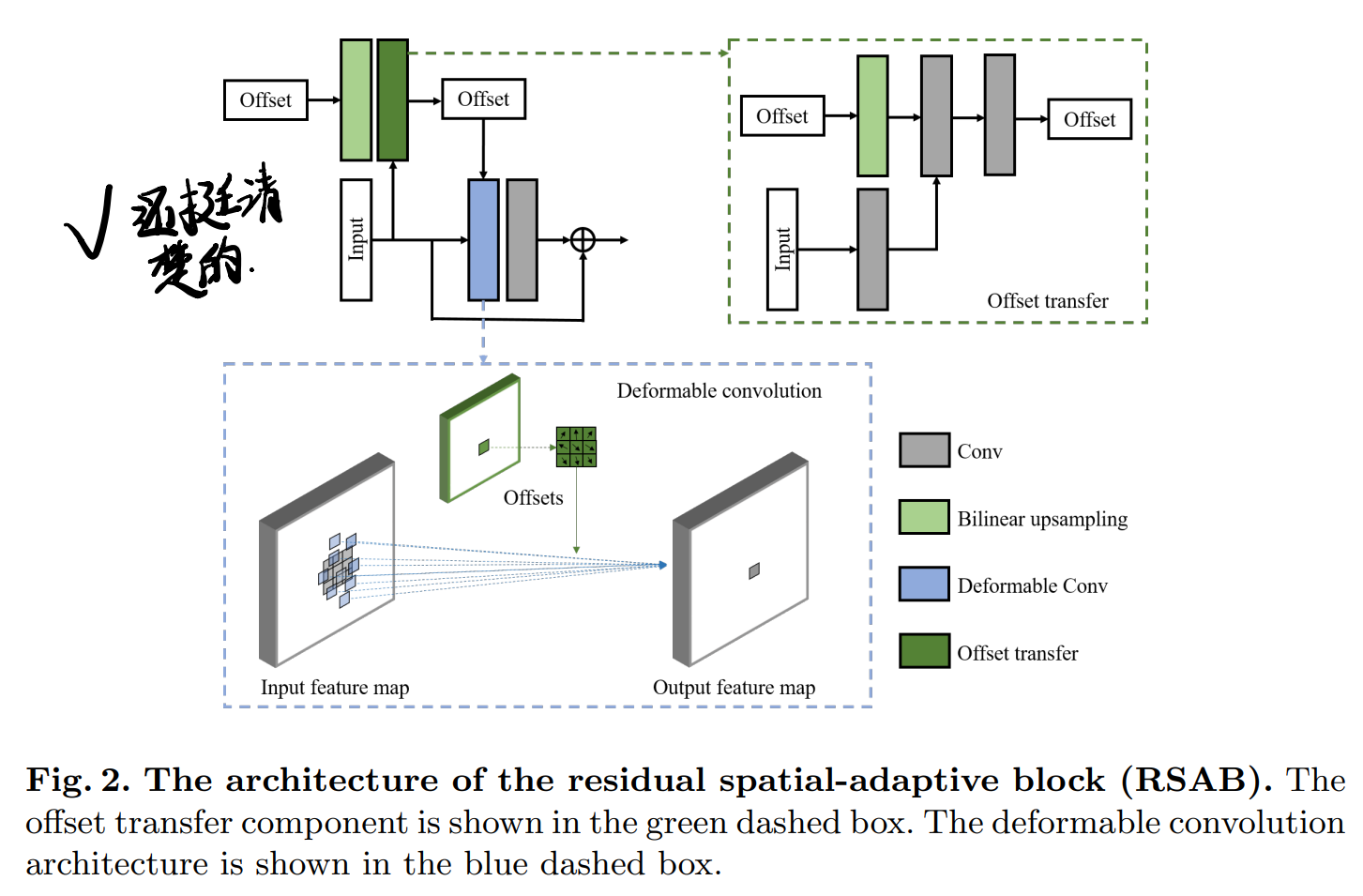
网络中间的Context Box:
1 Introduction
出发点是一般的Conv只能使用局部固定位置的pixel,但是这些pixel之间可能不相关甚至exclusive,由于这样的Conv Kernel不能适应纹理和边缘,所以基于CNN的方法会丢失细节,过度平滑区域;以及通常用于扩大感受野的方法,如加深网络、使用non-local module会增加内存、时间消耗,因此本文的贡献有:
- (没用的一条,大家都知道你提出了一个新网络)提出SADNet,网络可以复杂的图像内容中提取相关的特征,并且恢复细节和纹理;
- 提出了RSAB,包括适应空间特征和边缘的deformable conv、在自编码器中间夹了个context box来捕捉多尺度的信息。
2 Related works
虽然但是,讲挺清楚的。比如有TNRD和NLNet,以及再次抨击non-local operation需要消耗很多存储空间与时间。
3 Framework
见第一张图。
- 前面用了ResBlock,但是去掉了BN,激活函数改用LeakyReLU,限制了downsample的数量、利用context box以防破坏图像纹理、扩大感受野;
- 在解码器中用了RSAB,核心是deformable conv,offset transfer也是为了这个服务的;
- L1 L2 loss都用了,在合成噪声中用L2,在真实噪声中用L1。
3.1 Residual spatial-adaptive block
一般的Conv可以用下式表示:
\[y(p)=\sum_{p_i \in N(p)}w_i \cdot x(p_i)\]这种一般的Conv严格限制了抽取feature的位置,即当前pixel周围的矩形区域,但是这样抽取出来的特征往往是不相关的,会影响结果的计算(比如如果当前pixel在边缘,那么就会采样padding pixel,算出来的结果会平滑边缘)。这里挪用的方法是Deformable Conv,只考虑相关或者相似的特征,有点像self-similarity加权去噪的方式:
\[y(p)=\sum_{p_i \in N(p)}w_i \cdot x(p_i + \triangle p_i) \cdot \triangle m_i\]从而改变了Conv Kernel的形状,具体可以参考第二张图的示例。首先对每个pixel学一个offset map,并根据offset map调整kernel形状。\(\triangle m_i\)是调制系数,用来判断当前pixel和目标pixel之间的关系。
RSAB具体是把ResBlock第一层替换成了Deformable Conv,shortcut不变,BN去掉,激活函数替成LeakyReLU。
进一步提出了offset transfer,也就是用当前的Feature和上一层的offset去算当前层的offset。
3.2 Context block
目的就是和之前说的一样,避免使用过多down-scale操作,同时扩大感受野,具体做法是在dilated Conv前用一些1*1 Conv去处理输入特征,然后分四路Dilated Conv,不加BN(没说加不加激活哎),最后再接个1*1 Conv。以及shortcut。
3.3 Implementation
第一层和最后一层Conv的卷积核大小是1x1,令人意外地小。
4 Experiments
用到的数据集:
- 训练:
- DIV2K(合成噪声)
- SIDD
- RENOIR
- Poly
- 测试:
- BSD68
- Kodak24
超参设置的一些奇怪的点:patch都好小,比如这里的128*128,lr几乎没变化。
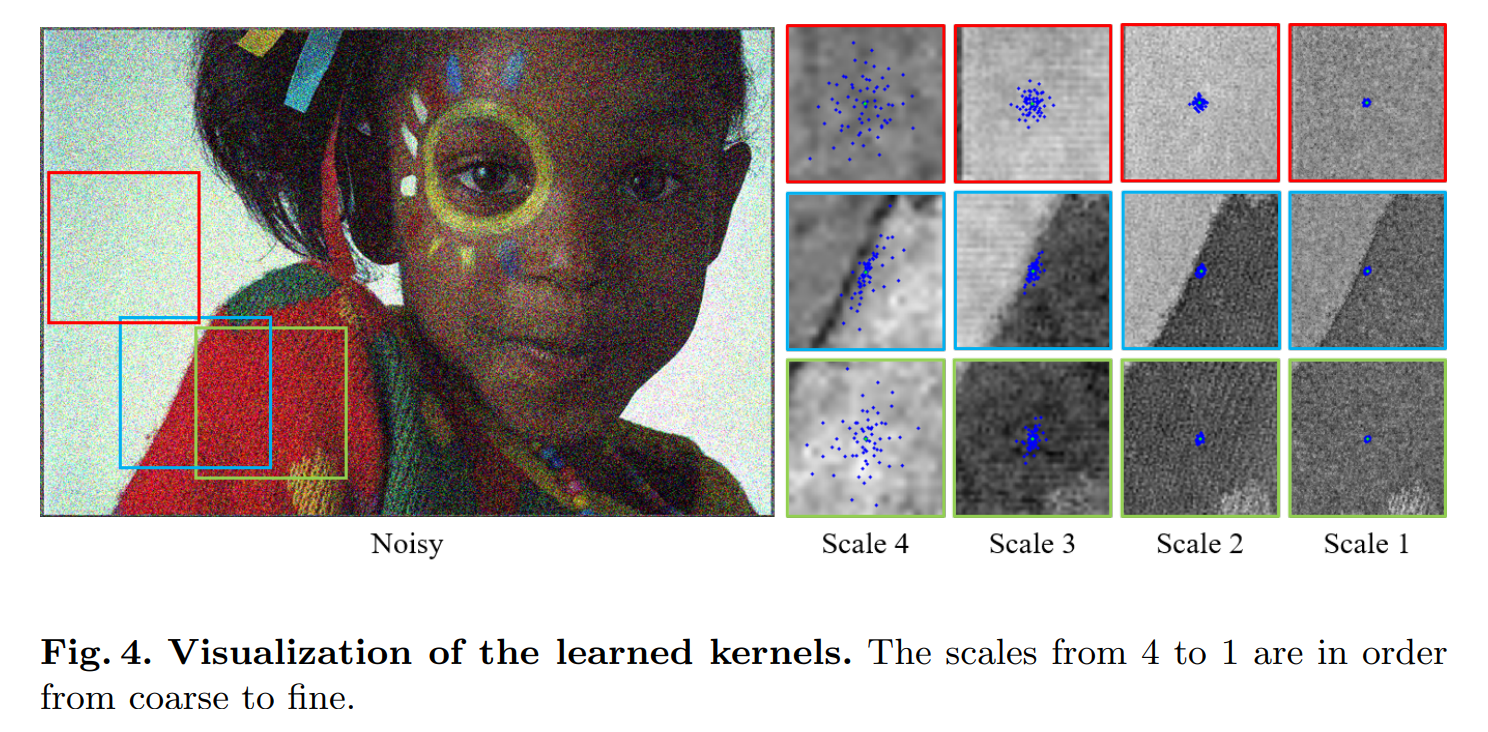
4.2 Analyses of the spatial adaptability
这种空间上不同的分布还挺有意思的:
4.3 Comparisons
简单(甚至不算)的训练技巧:混用数据集,并且有个数据集间的transfer
这篇文章就开始关注一些效率问题了: