Image Blind Denoising With Generative Adversarial Network Based Noise Modeling
2021/9/27
来源:CVPR18
resource:github上备份的包括ipad标注的pdf版本。
作者是中山大学的Jingwen Chen, Jiawei Chen, Hongyang Chao, Ming Yang等人,不是很了解他们。
Summary:一篇一般的论文,出发点是CNN的训练缺少成对图片,解决方法就是用GAN去学噪声分布,生成噪声patch(因为不能保证GAN网络生成的图像改变原始图像)加到纯净图像里构成noise-pure image pair指导CNN训练。性能不怎么样,合理怀疑是A+B文章。
Key words:
- GAN for denoising
- 2-staged Network
Rating: 3.0/5.0 一般,思路简单,效果不佳。
Comprehension: 4.0/5.0 GAN那块不是非常懂,但还是挺懂了。
三张图总结全文,见下面的流程图、GAN图、CNN图。
2. Related Work
BM3D的描述还可以。
细分出了Image Prior Based Denoising Methods和Noise Modeling Based Blind denoising Methods的两个概念,这难道是两种概念吗?
第一次引入了internel information和external information的概念,意思是同一张图中的信息,与一个dataset中的信息。
2.4. Generative Adversarial Network (GAN)
GAN被提出用来估计生成性模型(estimate the generative model),能够学习复杂的分布,绕过了使用深度生成性模型的一些难点,例如近似棘手的概率计算。GAN中,判决性网络用来判断一个样本是生成的还是真实的,生成性网络生成样本以骗过判决性网络。但是,GAN的训练非常有技巧性、不稳定。
3. GAN-CNN Based Blind Denoiser (GCBD)
使用GAN从含噪图片中构建成对的训练数据作为数据集,因为GAN很难学从纯净图片到含噪图片的映射,所以直接训练GAN输出噪声。假设噪声类型是零均值加性噪声。整体流程如下图所示:
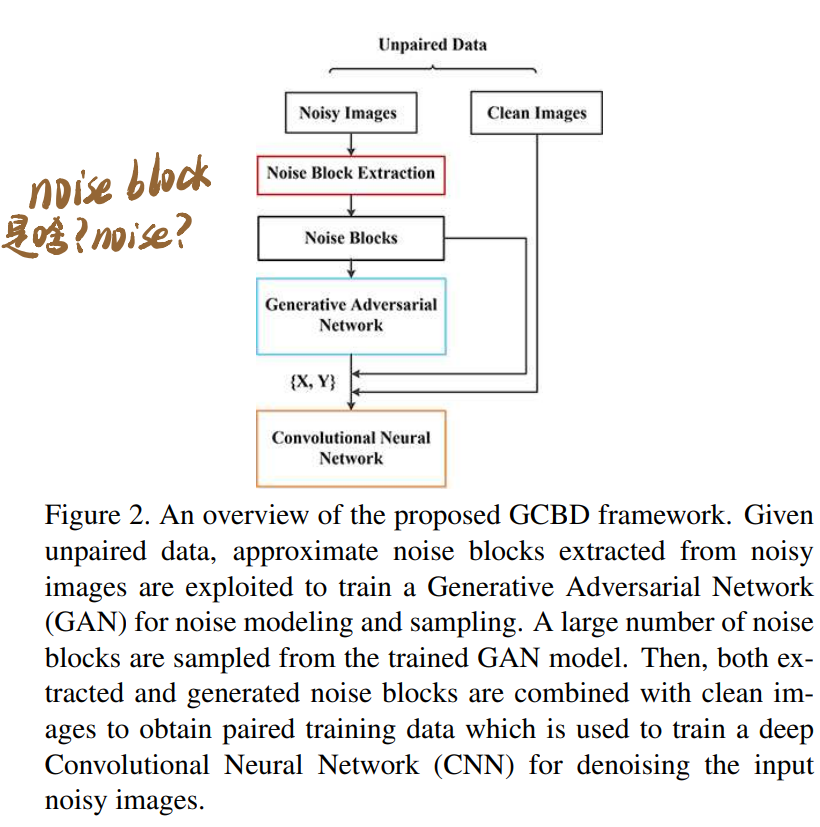
3.1. Noise Modeling
3.1.1 Noise Block Extraction
这一步是从含噪图像中提取噪声patch。因为假设噪声零均值,提取方法是noisy image patch里减去一个相对平滑的patch(relatively smooth patch)的均值,这里的平滑patch指的是内部非常相似的区域,有个具体的抽取方法,不在这里列了,反正应该用不到。
3.1.2 Noise Modeling with GAN
GAN的结构如下:
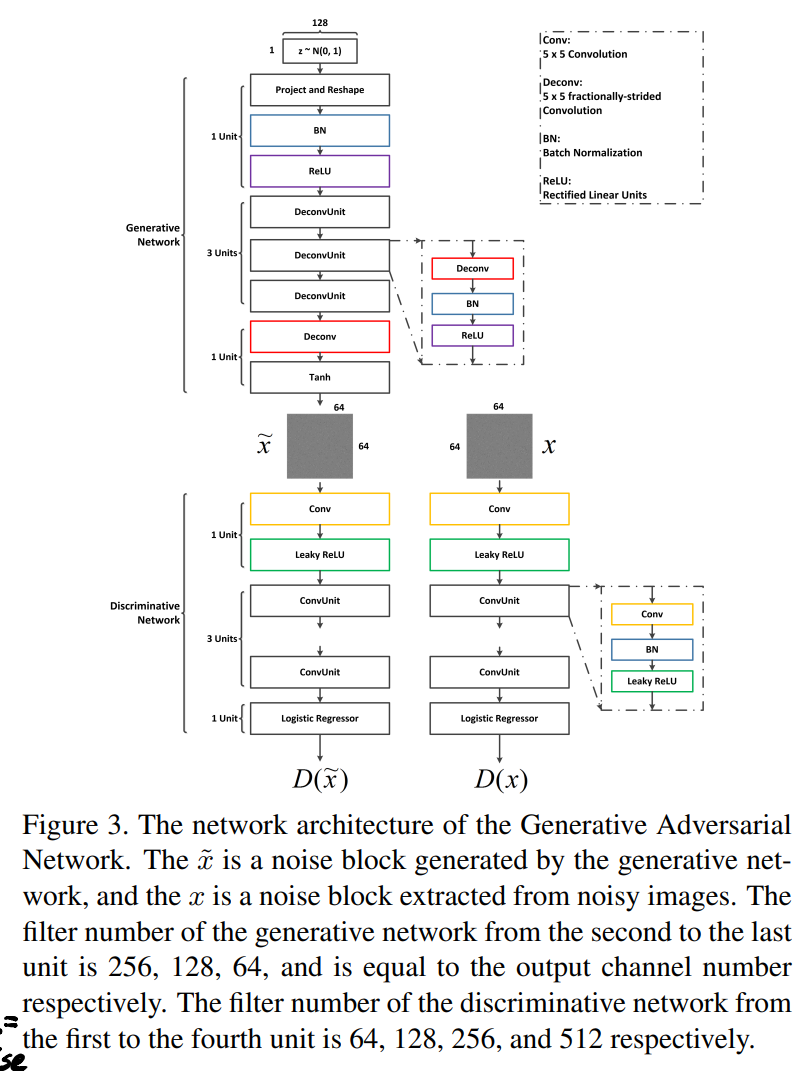
对应一种新的loss:

但是第三项不太懂。
3.2. Denoising with Deep CNN
把生成的noise和真实noise分别加到图像patch中,再把合成patch拼成完整的图像。CNN使用残差结构(实际上和DnCNN一样吧):
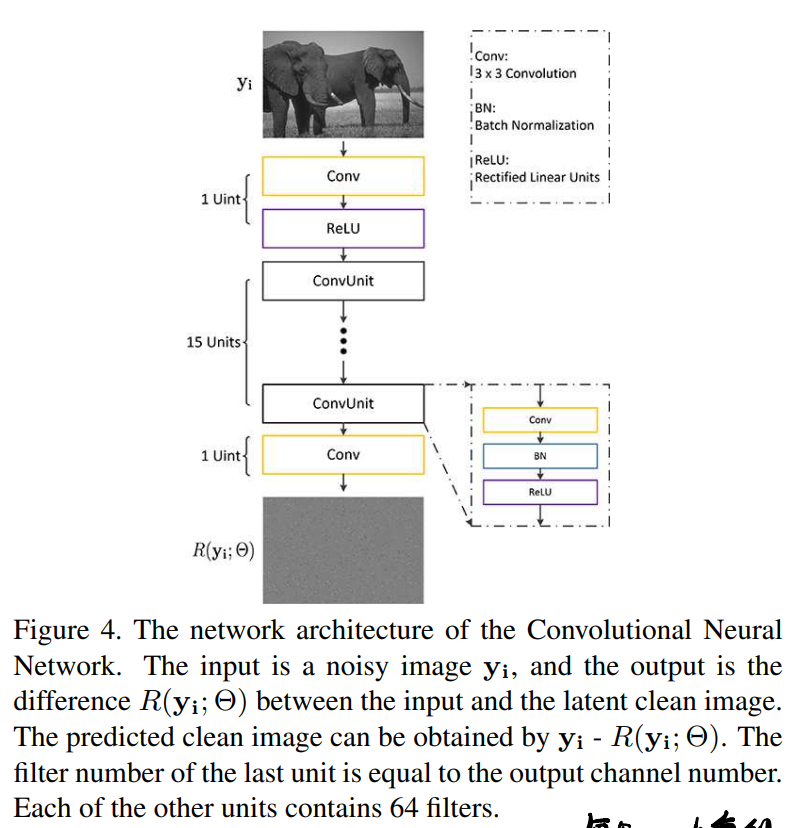
4. Experiments
测了高斯盲去噪、混合噪声、真实噪声,性能很菜,高斯盲去噪甚至比不过DnCNN-B。有一节甚至放出来了噪声对比,你放噪声这谁懂啊。
没见过的实验数据有NIGHT、CLEAN1、CLEAN2。