Towards Accurate Binary Convolutional Neural Network
2021/6/16
来源:NIPS2017在投
resource:github上备份的包括ipad标注的pdf版本。
作者是DJI的Xiaofan Lin、Cong Zhao和Wei Pan,这篇文章也算是BNN领域的开创性&代表性作品了。
Summary:BNN领域非常具有代表性的作品,提出使用线性组合的weights&activations来近似FP counterpart,在早期就取得了非常高的成绩(~65),但是代价是比较显著地增加了运算数和存储空间消耗。值得注意的是,这里对activation的量化就已经出现了zero point shifting的思想。此外,这篇文章中还出现了BN merge的思想,将训练后的BN和sign函数组合在一起(所以昨天读的boolnet不是第一篇提出这种设计思想的工作啊0 0)
rating:3.6/5.0
comprehension:4.3/5.0
文章的贡献有:
- 提出了一种比较典型的weights/activations近似方法,用一组binary的weight base/activation base线性加权近似full-precision counterpart。
1 Introduction
- 提了一个论点:量化feature map比量化weights更难些。
2 Related work
- 一个很牵强的论点(所以放在这里有啥用啊):二值激活可以用脉冲响应(spiking response)于事件依赖的计算和通信,只在必须的时候才消耗能量,因此能效较高。
It is known that binary activation can use spiking response for event-based computation and communication
(consuming energy only when necessary) and therefore is energy-efficient
3 Binarization methods
3.1 Weight approximation
说对每层的weight有两种近似方法,一种是layerwise,一种是channel-wise,但是后者额外的计算/存储/能量开销太大了,所以本文用的是layerwise的方法。
用这种方法来近似FP weights(公式太难打了,偷懒截图了乌乌):

公式(1)用数值方法也能求解出来base和\alpha,但是这样就不能用反向传播(没有深究)更新W了,所以用了下面这种手工定义的方法得到weight base:

其中\(u_i\)既可以是训练的,也可以是定义的(这篇文章里用了人工定义的方式)。得到base之后用求解的方法求出来\(\alpha\)(这里和那篇binarySR一模一样啊,真就硬抄呗/不对,人家还改了加权的东西呢,hh)。
这里似乎没说alpha的取值,但显然是FP的,这不算作弊?
3.2 Multiple binary activations and bitwise convolution
在量化activation之前要clip一下,这里的量化出现了zero point shifting!,而且shift parameter是个可学习的参数:

但是和weights不一样的是,尽管activations的组合也可以用线性回归,但是输入的统计特性在不断变化(因此不能构建之前那种依赖statistics的base),解决的方法是在sign之前先过BN,这样将feature map normalize(有问题诶,训练之后不就不能改变statistics了吗)。而且这里采用可训练的加权系数也是为了"静态"适应变化的输入:

之后用可训练的sign函数以及加权系数把它们串起来。
最后组合之后的样子大概是这样的:
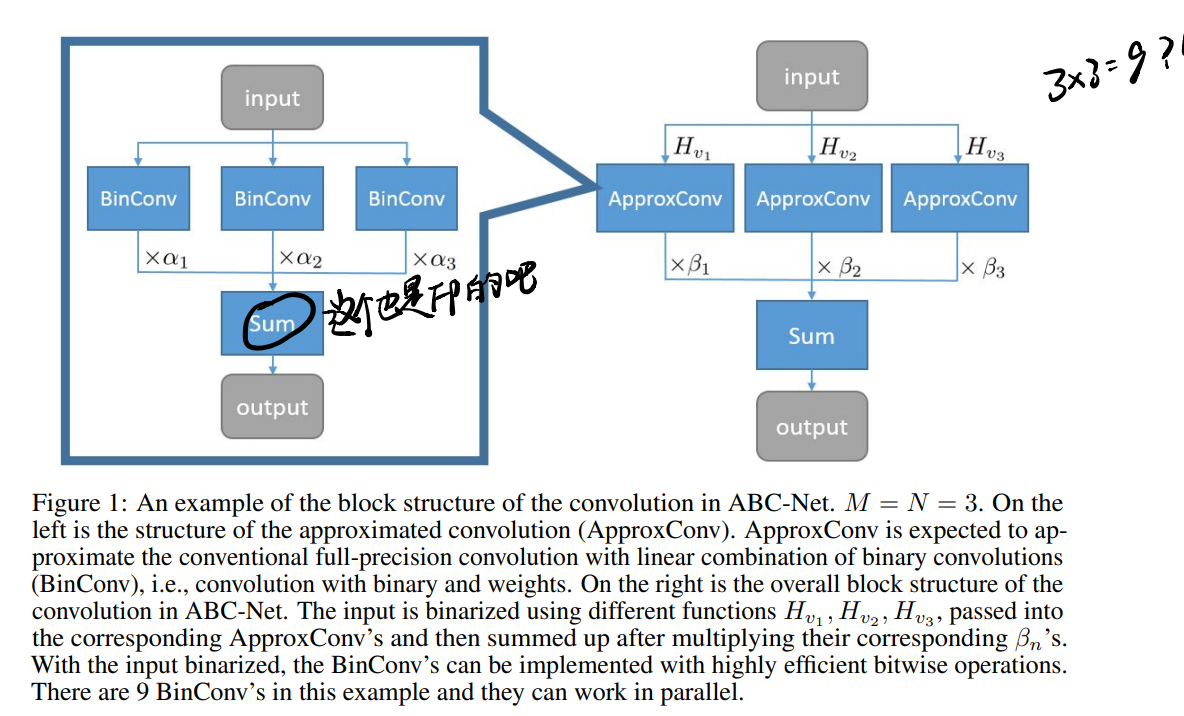
3.3 Training algorithm
一些技术细节:
- 把max-pooling layer放在BN和activation层之前,防止出现几乎都是+1的情况;
- 没说清楚是不是把pretrained-model作为initialization(说作为initialization好,但是又表示需要适应新结构,所以有没有用这种initialization啊),算法如下:

- M增多(base增多)偏移量彼此接近,性能变差(可能是因为线性回归难解了),加个l2正则可能好使。
4 Experiment results
- 好像没啥用:accuracy随着weight base数量增多而线性增加。
- 和17年SOTA的比较结果:

5 Discussion
5.1 Why adding a shift parameter works?
QuickAnswer:因为部分利用了幅度信息。
5.2 Advantage over the fixed-point quantization scheme
大概可以总结如下:
- K binarization scheme(本文的方案)保留了比特操作,比定点计算更有效;
- K位乘法器比K个一位乘法器消耗更多资源(和上面有区别?);
- "spiking response"(九折?)。
5.3 Further computation reduction in run-time
有一些op可以merge起来进一步减少资源消耗(对!说的就是BN!)。
下面就是把activation的shift和BN中的偏移结合起来的:
