START: Traversing Sparse Footholds with Terrain Reconstruction
2026/5/12
来源:RAL25
-
总结:START 提出了一种面向稀疏落脚点地形的端到端四足机器人学习框架:通过 TR-Net 从机载第一视角深度图和本体感知中重建局部 heightmap,并把它作为 locomotion policy 的显式输入,进行安全落脚和步态调整,从而在真实 Lite3 机器人上实现踏石、窄梁、沟壑等场景的 zero-shot sim-to-real 穿越。
-
中心思路:作者认为,稀疏落脚点地形上,策略最需要知道的是哪里可以踩、边缘在哪里、当前脚附近的地形如何。如果只把深度图压成一个隐式 latent vector,策略容易丢失边缘、窄梁、踏石中心等关键几何信息,最后学成一种平均化、僵硬的步态。START 的思路就是:仍然做端到端训练,但中间显式监督一个局部地形重建任务(使用 TR-Net 重建局部 heightmap),让策略看到一个具有物理意义的地形表示。
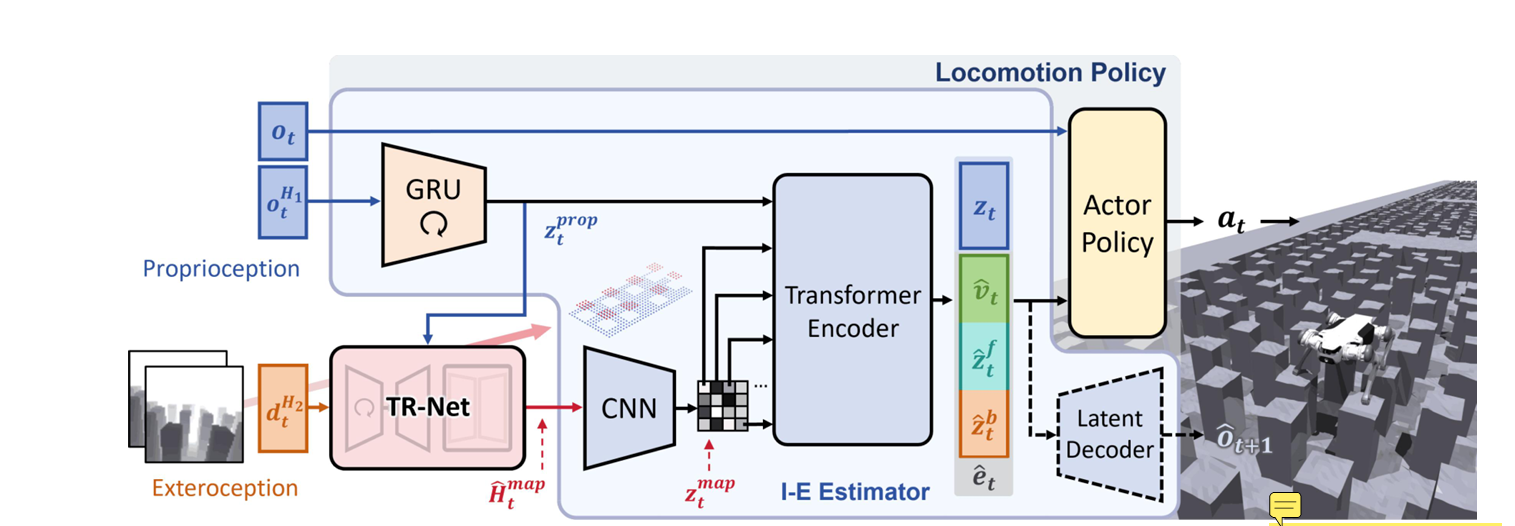
- 上图中给出了 START 的两个核心模块,TR-Net 和 Terrain-Aware Locomotion Policy。
- TR-Net 负责从深度图和本体感知中重建局部 heightmap。
- Terrain-Aware Locomotion Policy 负责根据重建 heightmap 和本体状态输出 12 个关节的位置目标。
- 总体的控制流程是,机器狗先得到本体感知(角速度、重力方向、速度命令、关节角、关节角速度、上一时刻动作等),同时得到第一视角深度图。TR-Net 用这些信息重建局部 heightmap。然后 locomotion policy 里的 I-E Estimator 再进一步从本体感知和重建 heightmap 中提取隐式和显式估计量,最后 actor 输出 12 维关节目标。
- 设计细节如下:
- TR-Net
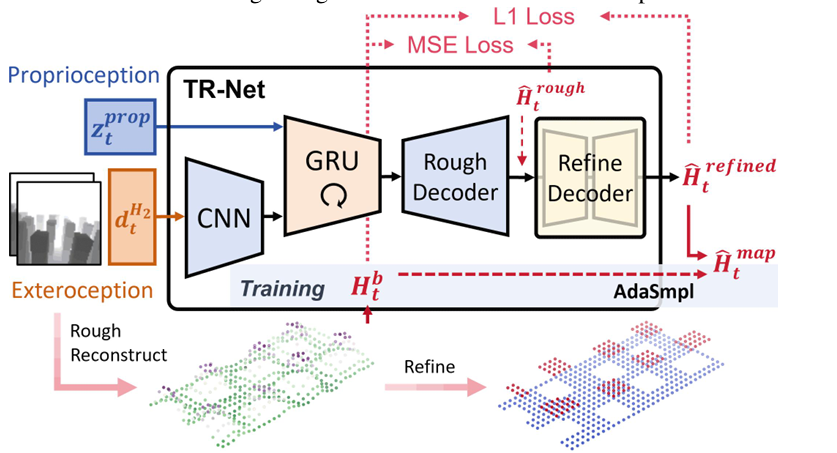
- 输入是本体感知特征和最近两帧深度图,输出是机器人局部坐标系下的局部 heightmap。这个 heightmap 覆盖机器人后方 0.5 m 到前方 1.1 m,宽度 0.8 m,空间分辨率 5 cm。覆盖身体下方和身后是因为,稀疏落脚点中,机器人当前脚下或身后区域往往已经不在相机视野中,所以用了 GRU 来保留时间记忆,把过去看到但现在被遮挡的地形也保存在局部重建中。
- TR-Net 的结构是,CNN 编码深度图,拼接本体感知特征,再送入 GRU,之后由 MLP decoder 输出一个 rough heightmap;为了让边缘更清楚,后面再加一个 U-Net 风格的 refinement decoder,生成 refined heightmap。
- Locomotion Policy
- 由 I-E Estimator 和 Actor 两部分组成,
- I-E Estimator 用 GRU 处理历史本体感知,用 CNN 处理重建 heightmap,再用 transformer encoder 融合这些特征。显式输出包括 base velocity 估计、body-centric heightmap descriptor、foot-centric heightmap descriptor;隐式输出则来自 VAE latent。训练时,它被监督去预测下一步本体感知、base velocity、脚周围 heightmap、身体周围 heightmap等。
- Actor 的直接输入包括当前本体感知、I-E Estimator 的显式估计和隐式 latent;输出是 12 维关节位置目标。训练采用 PPO,并使用 asymmetric actor-critic。
- AdaSmpl
- 原因是,训练早期 TR-Net 的重建很差,如果 locomotion policy 一开始就只吃 noisy reconstructed heightmap,那么它很难探索到成功行走策略,导致训练不稳定。
- 具体做法是,训练时以一定概率把 TR-Net 重建 heightmap 替换成 ground-truth heightmap,给 locomotion policy 暂时提供"干净地图"。
- TR-Net
- 训练细节如下:
- 训练在 Isaac Gym 上进行
- 使用云深处 Lite3 机器人(实机头部装 Intel RealSense D435i,相机以 10 Hz 获取深度图,经过过滤后得到 60×60 深度图输入)
- 在一张 RTX A6000 上训练约 10000 iterations / 16.6 小时。
- 本文的局限 & 和我们的需求匹配/不匹配的地方如下:
- 是一个局部控制策略,能根据速度命令和局部地形行走,但是没有导航能力。而且所谓的 "Sparse Footholds" 是指机器狗运动环境中的落脚点很少,而不是先显式预测出落脚点,再让机器狗track到这些位置。