π0: A Vision-Language-Action Flow Model for General Robot Control
2026/5/14
来源:RSS25
- 总结:把 "大模型预训练 + 后训练" 的范式搬到机器人控制里,做一个能跨机器人本体、跨任务、接受语言指令,并且能输出连续高频动作的通用机器人策略模型。传统 VLA 像 OpenVLA 往往把机器人动作离散化成 token,然后像语言模型一样自回归生成动作;但 π0 认为高频、精细、连续的灵巧操作不适合这样做,所以它保留 VLM 的图文语义能力,同时额外加了一个 action expert,用 flow matching 来生成连续动作块。这样既能理解语言和图像,又能输出更适合机器人控制的连续动作。
-
Takeaways: π0 的本质不是机器人上的 VLM,而是用 VLM 做语义骨架,用 flow matching 做连续动作生成,用大规模跨本体数据和后训练 recipe 把它变成机器人策略。
- 本文的故事
- 作者认为当前机器人学习有三个核心困难:数据少、泛化弱、鲁棒性差。单任务机器人策略通常只能在一个窄场景里工作,一旦换物体、换初始状态、换任务流程、换机器人平台,性能就会显著下降。文章借鉴 LLM/VLM 的经验:与其为每个任务单独训练一个小模型,不如先在大量多样数据上预训练一个通用模型,再用高质量数据后训练到具体任务上。
- π0 也采用大规模预训练+后训练微调的逻辑:预训练阶段用大量、多机器人、多任务、质量参差但覆盖广的数据,学到基本物理交互、视觉理解、动作恢复等能力;后训练阶段用更少但更高质量、更一致的数据,让模型在具体任务上动作更流畅、更高效、更像专家。文章反复强调,只用高质量数据会导致模型缺少失败恢复经验,只用大规模杂数据又会导致动作策略不够干净和高效。
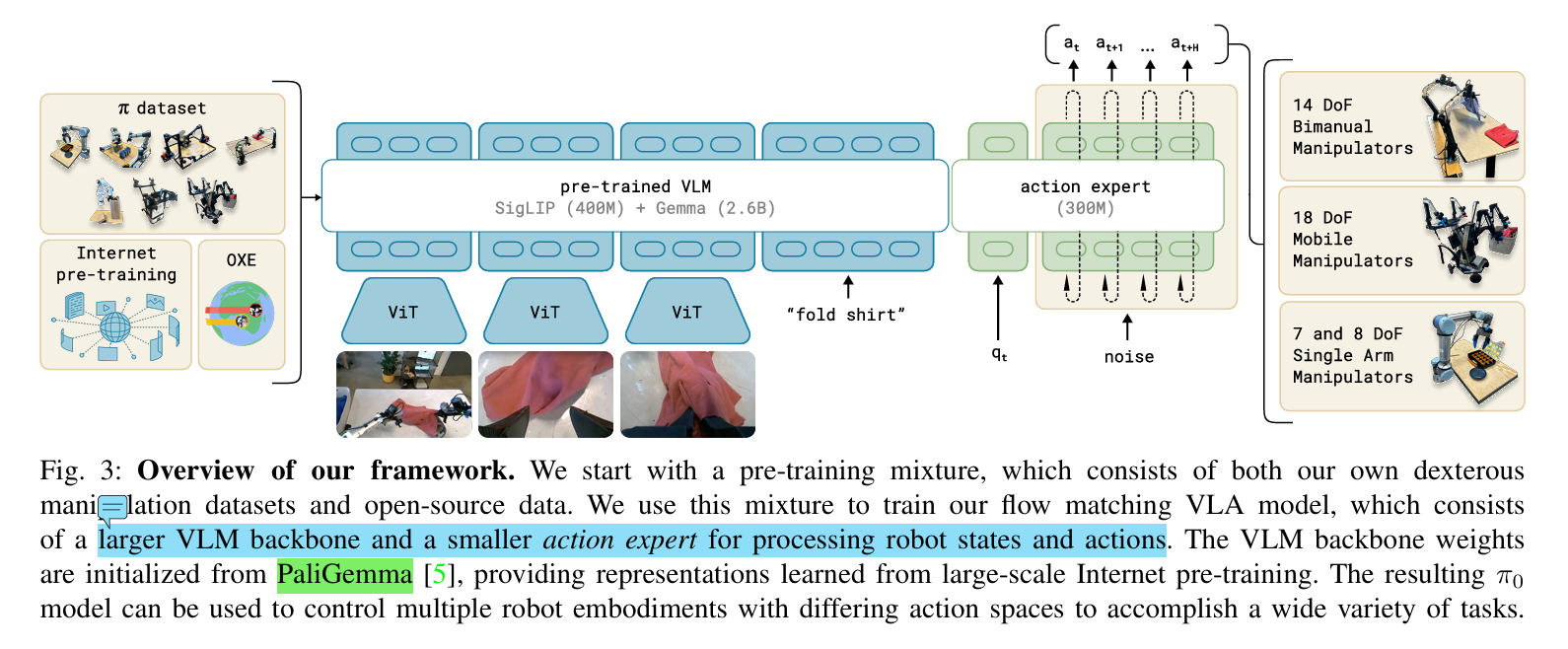
- π0的模型结构
- π0 的主体是一个基于 PaliGemma 的 VLM backbone。PaliGemma 负责处理图像和语言,把多路 RGB 图像和语言指令编码到统一的 token embedding 空间中。机器人额外还有 proprioceptive state,也就是本体状态,例如关节角度,这部分也会被编码后投影到同一个 embedding 空间。
- 作者没有直接让 VLM 像生成文本一样生成动作 token,而是加了一个 action expert。可以把它理解成:普通 VLM backbone 更擅长处理视觉和语言;action expert 专门处理机器人状态和动作 token。
- 模型要建模的是,给定当前观测 $o_t$,生成未来一段动作块 $A_t = [a_t, a_{t+1}, …, a_{t+H−1}]$。文章中 H=50,也就是说一次不是只预测下一步动作,而是预测未来 50 步的 action chunk。输入观测包括多张 RGB 图像、语言命令、机器人关节状态;输出是连续动作序列。π0 用 flow matching,就是为了更自然地表达连续动作分布。
- Flow matching
- 可以把 flow matching 粗略理解为一种从噪声逐步变成动作的生成模型,和 diffusion 思路接近。训练时,真实动作块 $A_t$ 会和高斯噪声混合,得到一个带噪动作 $A_t^τ$。模型学习的不是直接输出动作,而是学习一个向量场 $v_θ(A_t^τ,o_t)$,告诉当前这个带噪动作应该往哪个方向移动,才能变成真实动作。
- 文章采用的路径比较简单:从随机噪声开始,逐步向真实动作靠近。训练时采样噪声 $ϵ$,构造 $A_t^τ=τA_t+(1−τ)ϵ$,然后让模型预测从噪声到真实动作的方向 $A_t−ϵ$。推理时则从随机噪声 $A_t^0$ 出发,用 Euler integration 积分 10 步,得到最终动作块。
- 这和自回归动作 token 的差别很大。OpenVLA 这类模型把动作离散化后像文本一样生成,适合低频、粗粒度动作,但对高频灵巧任务不友好。π0 生成的是连续动作块,并且 action tokens 之间使用双向注意力,意味着一个动作块内部的各步动作可以相互协调,而不是一步一步单向生成。
- 数据和训练 recipe
- 预训练混合数据包括作者自己的 π dataset,以及 OXE、Bridge v2、DROID 等开放数据。开放数据占训练 mixture 的 9.1%,作者自己的数据包含 903M timesteps,其中 106M 来自单臂机器人,797M 来自双臂机器人;总共涉及 7 种机器人配置和 68 个任务。
- 训练分为 pre-training 和 post-training。pre-training 的目的不是让某个任务做到满分,而是获得广覆盖能力:语言理解、视觉识别、基本操作、失败恢复、跨场景适应。post-training 则针对具体复杂任务,用更高质量、更一致的数据让模型形成专家策略。