2021/6/17实验记录
2021/6/17
variant STE测试
vSTE on toy model
怀疑vSTE和nSTE差距不大是clip threshold不够明显的区别(几乎没有clip值),所以进行了下面一组对比。
- 实验条件:
- FP weight Binary activation的toy model,bs=8192,无预训练
- 实验结果
-
- clipping threshold = ±0.5:
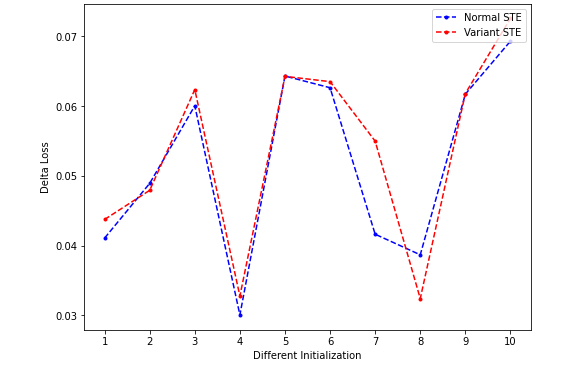
-
- clipping threshold = ±0.2:
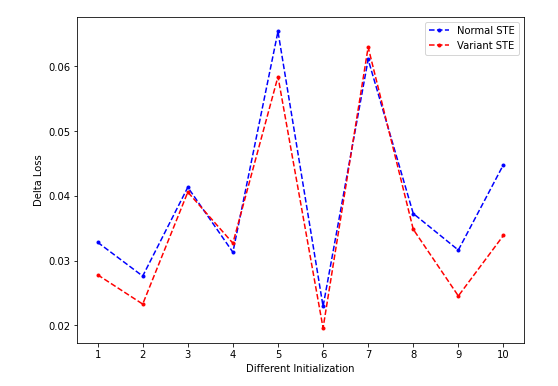
- clipping threshold = ±0.2:
-
- clipping threshold = ±0.1:
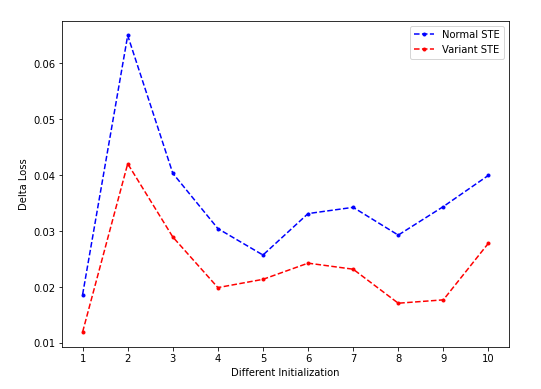
- clipping threshold = ±0.1:
- 结论
- clipping STE对loss下降没有明显帮助(在threshold比较大的时候几乎没有被clip的值;适中的时候效果也不是很稳定,而且总体看要比nSTE差,在threshold比较小的时候明显差于nSTE),该结果与binaryduo中汇报的一致?
- 可能的原因:在FWBA条件下的特例?
vSTE on XNOR-ResNet
在ResNet上再测试vSTE。
- 实验条件:
- FP weight Binary activation的XNOR-ResNet,bs=128,第20epoch
- 可能是计算图的特性,clip当前层的activation之后似乎不会对当前层的weight的grad造成影响,因此clip最后一层的conv kernel,测第一层的conv grad。
- 实验结果:
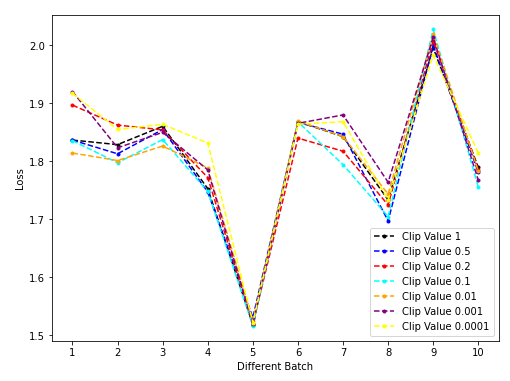
- 结论:
- vSTE和nSTE的差距非常不明显(clip value=1作为没有clip的baseline),但是极端clip情形一定不好(value=0.01/0.001/0.0001),这三条曲线几乎堆在图的最底部。
比较Toy Model和XNOR-ResNet上的实验,可以得出结论:
- vSTE和nSTE的差距不是很明显(因此上次实验几乎没有看到区别,这也和clip value的选取有关,对于toy model来说±0.5的clipping value看来还是太大了),很难说明哪个更好,但是极端clip的情形一定不好。
- XNOR-ResNet和Toy Model对极端clip的鲁棒性不同。Toy Model上用0.1 clip就能看到非常明显的性能恶化,但是在XNOR-ResNet上clip则不这么明显。
*Interesting Findings
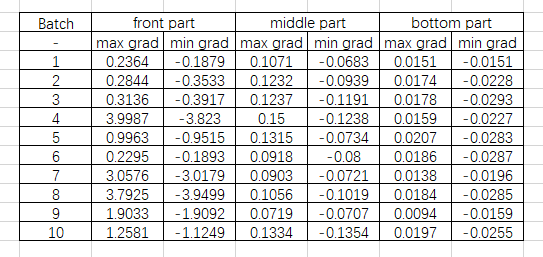
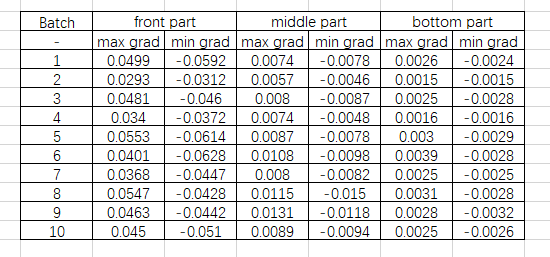
不同层深关于weights的gradient大小有明显不同:
- XNOR-ResNet on early training stage:
- XNOR-ResNet on late training stage:
- Insight:
- 因为没有对weight进行quantize,所以也就没有对weight gradient进行clip,发现越靠模型前部weight gradient越大,能否从这个点(结合之前模型前面CDG>STE的结论)说明STE误差累积?