# OpenPCDet
Overall Framework
- OpenPCDet官网上给了个整体的模型框架,非常清楚:
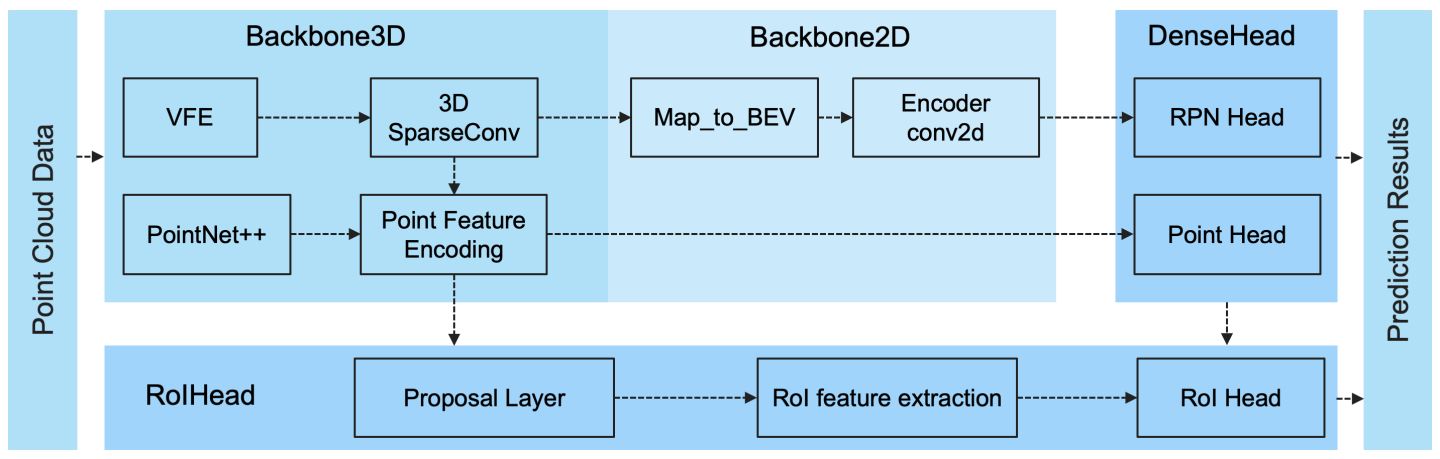
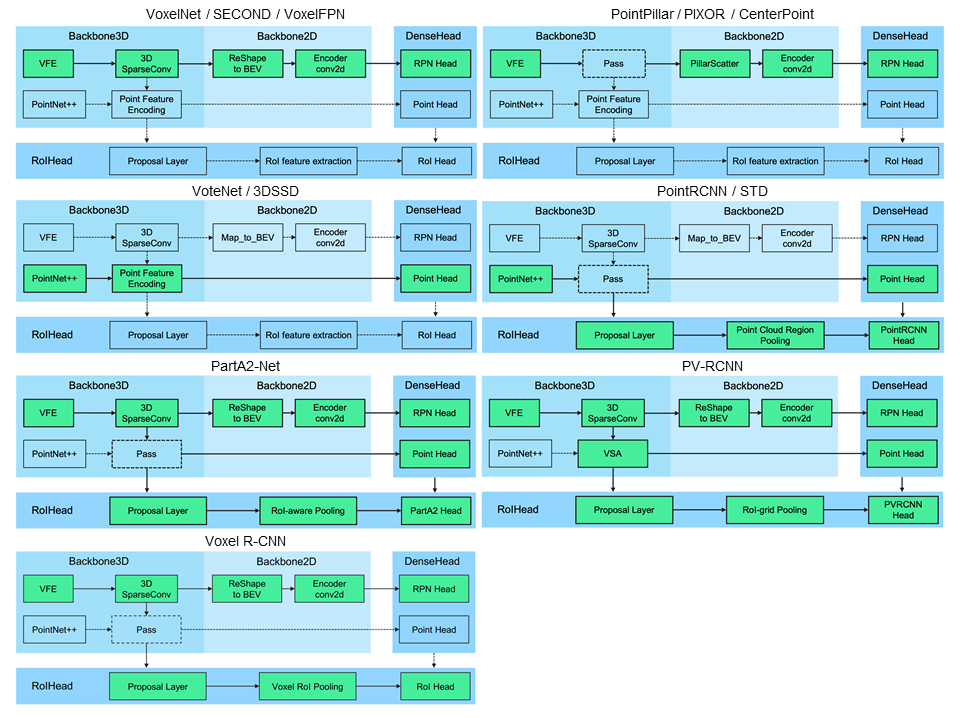
- 其中,一些典型模型的组成如下所示:
Dataset
- Kitti的数据集加载与预处理见这个页面。
PointPillar实例
模型初始化
- 模型
PointPillar在OpenPCDet中是个detector,似乎有对应的backbone(实际的网络定义) detector的基类是Detector3DTemplate,主要靠里面的build_networks方法来实现模型定义。模型中包括的模块有:VFE(short for Voxel Feature Encoder):- 甚至找到了个专门介绍
VFE模块的博客。看起来是负责做由point cloud到pillar的encoding过程; - 定义在
./pcdet/models/backbones_3d/vfe/pillar_vfe.py; - VFE的一些参数设置:

- VFE的功能主要是靠
PFNLayer实现的,定义也在同一个文件中;PointPillar的PFNLayer就是一个Linear(10, 64) + 一个BN1d:

- 初始化函数里除了定义
PFNLayer就是算几个offset;
- 甚至找到了个专门介绍
backbone_3d:- 这个是空的(of course…)
map_to_bev_module:- 定义在
./pcdet/models/backbones_2d/map_to_bev/pointpillar_scatter.py;具体是PointPillarScatter; - 看起来是生成pseudo image的模块;
- grid size(432, 496, 1)分别对应于
self.nx,self.ny,self.nz.
- 定义在
pef:- None
backbone_2d:- 定义在
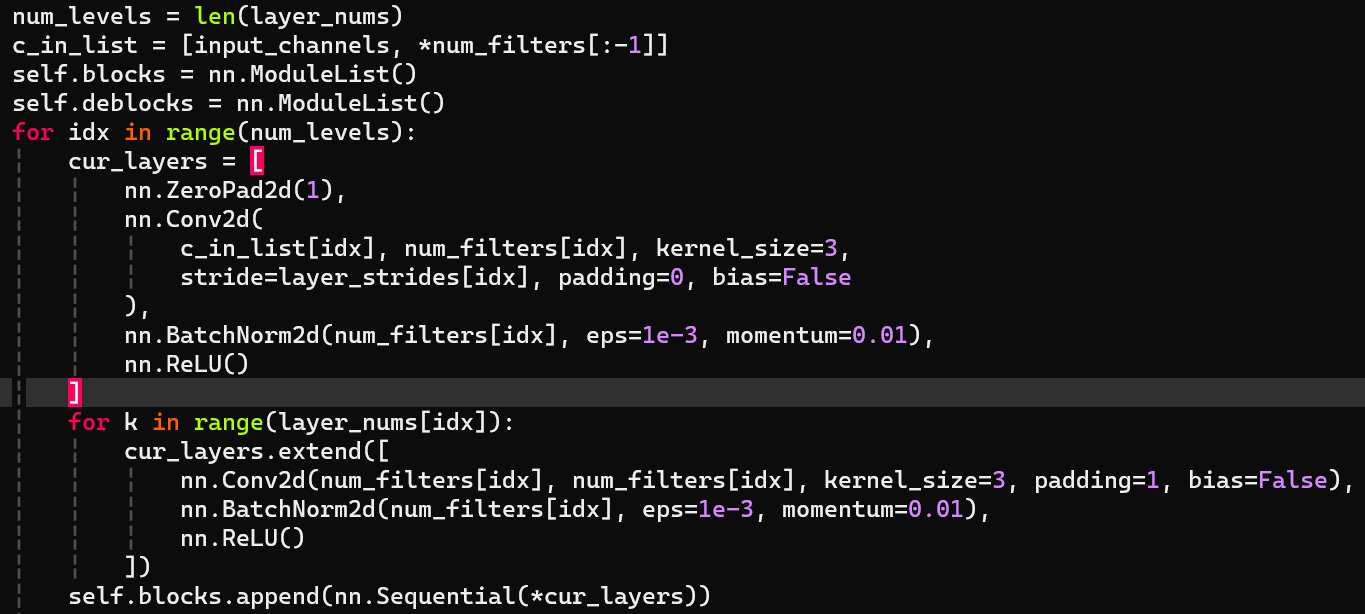
./pcdet/models/backbones_2d/base_bev_backbone.py;具体是BaseBEVBackbone; - 正经的模型定义;具体参数如下所示:

- 分成3个阶段(enc-dec对称的,一共6个block),每个stage有1(含有stride的) + num_layer[idx]个层(更具体的是,ZeroPad-Conv-BN-ReLU + num_layer[idx] * (Conv2d-BN-ReLU));
- in case I don't remember:
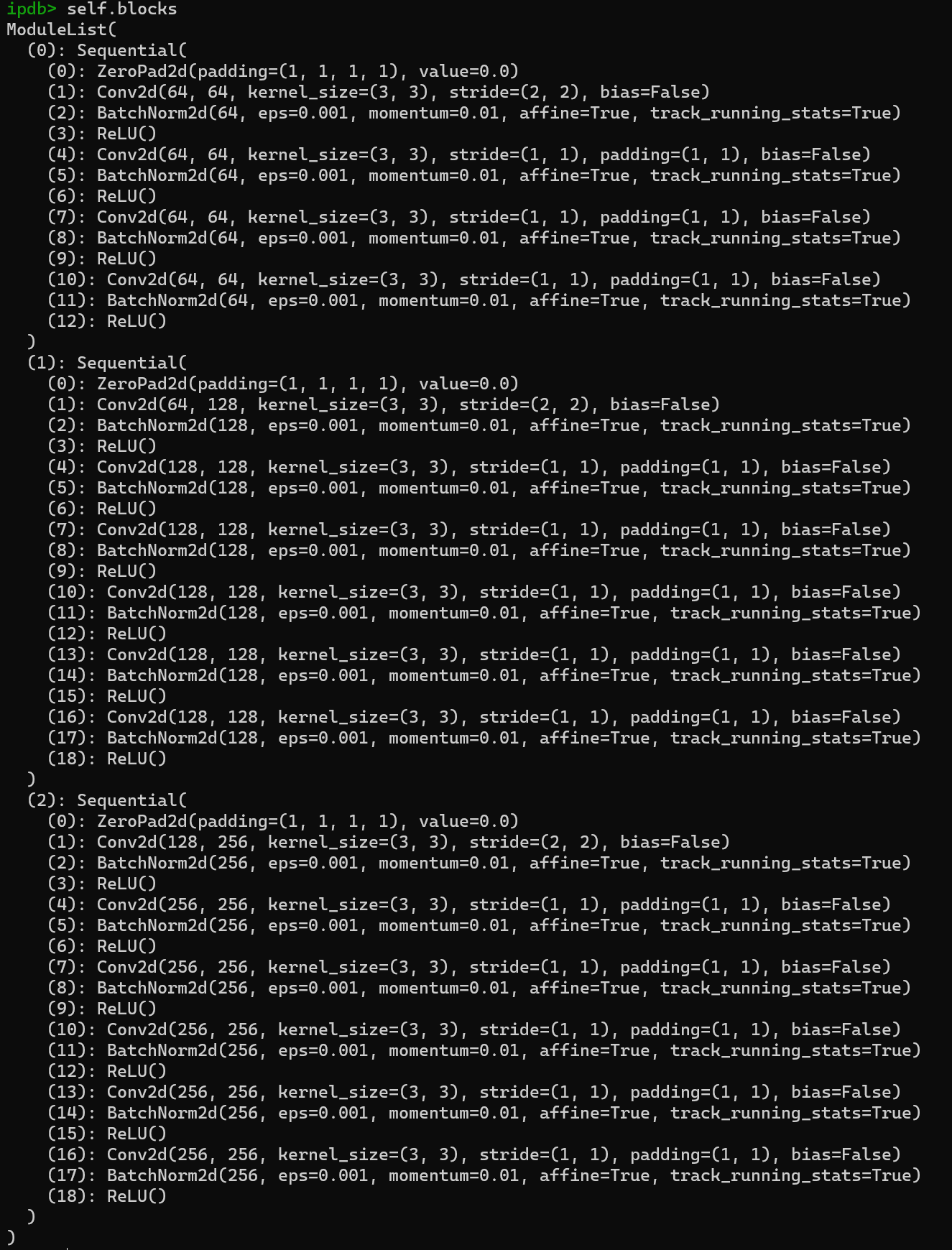
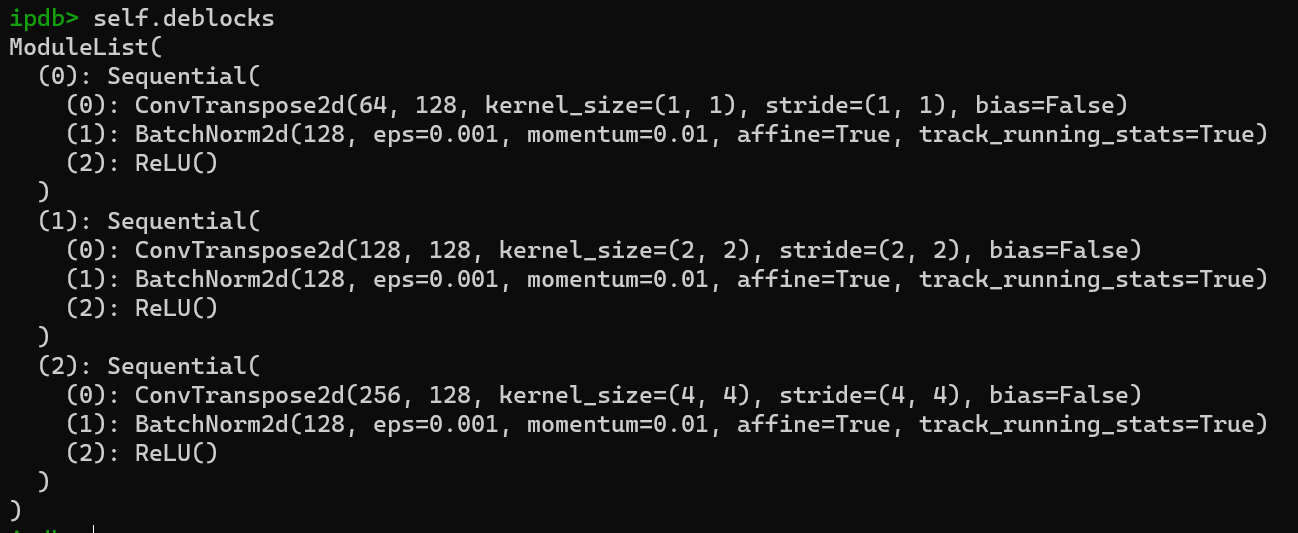
- deblocks则相对更thin一些,只有一个deconv;
- self.blocks & self.deblocks的全景图(nmd真的有必要放吗?):
forward函数:def forward(self, data_dict): """ Args: data_dict: spatial_features Returns: """ spatial_features = data_dict['spatial_features'] ups = [] ret_dict = {} x = spatial_features for i in range(len(self.blocks)): x = self.blocks[i](x) stride = int(spatial_features.shape[2] / x.shape[2]) ret_dict['spatial_features_%dx' % stride] = x if len(self.deblocks) > 0: ups.append(self.deblocks[i](x)) else: ups.append(x) if len(ups) > 1: x = torch.cat(ups, dim=1) elif len(ups) == 1: x = ups[0] if len(self.deblocks) > len(self.blocks): x = self.deblocks[-1](x) data_dict['spatial_features_2d'] = x return data_dict
- 定义在
dense_head:- 定义在
./pcdet/models/dense_heads/anchor_head_single.py,具体是AnchorHeadSingle;AnchorHeadSingle的基类AnchorHeadTemplate:- 参数非常之多:
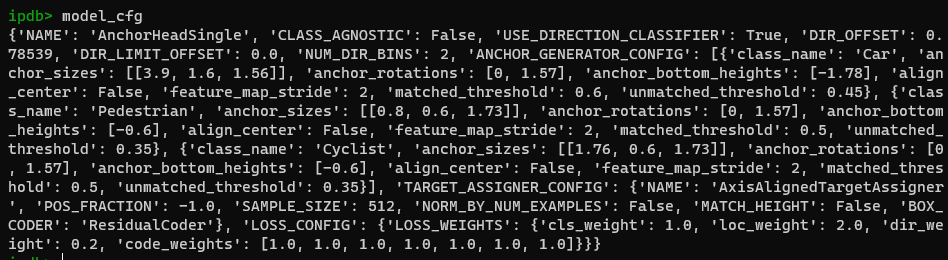
predict_box_when_training是False,不知道啥意思;- 里面有一个
self.box_coder属性,来源是./pcdet/utils/box_coder_utils.py里的ResidualCoder,不知道是干啥的。 anchor_target_cfg属性包括:

- 还会通过
self.generate_anchors方法生成一些anchor(这是怎么回事?anchor居然是事先生成的吗?) anchor_generator_cfg包括:

- 这个方法里还包了一个
AnchorGenerator(来源是./pcdet/models/dense_heads/target_assigner/anchor_generator.py)的实例化,这也太复杂了吧 - 看起来这个实例才是真正干活(指生成anchor)的;
- 该类的
generate_anchor方法:包含非常复杂的张量变换,大意是按照空间切成grid,把anchor assign到每个grid的中心;每个anchor包括坐标(3)、尺寸(3+1)、方向(2)共7个维度;
- 这个方法里还包了一个
- 后面还有一个
self.target_assigner,是AxisAlignedTargetAssigner的实例(我去怎么这么多,而且怎么还有个专门的assigner啊??),初始化部分把各个类的threshold记录下来了; self.build_losses:- 有三种loss,但是没有细看各个loss的作用是啥,以及怎么实现的
- loss cfg如下所示:

- 参数非常之多:
- 在
AnchorHeadSingle类中,模型有三个输出头:self.conv_cls:顾名思义;- 但是为什么输出的类别有6*3种??
self.conv_box:顾名思义self.conv_dir_cls:dir -> direction,似乎给direction也有一个专门的输出头;
- 定义在
point_head:- None
roi_head:- None
- 来个完整的模型描述:
PointPillar( (vfe): PillarVFE( (pfn_layers): ModuleList( (0): PFNLayer( (linear): Linear(in_features=10, out_features=64, bias=False) (norm): BatchNorm1d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) ) ) ) (backbone_3d): None (map_to_bev_module): PointPillarScatter() (pfe): None (backbone_2d): BaseBEVBackbone( (blocks): ModuleList( (0): Sequential( (0): ZeroPad2d(padding=(1, 1, 1, 1), value=0.0) (1): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), bias=False) (2): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (3): ReLU() (4): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (5): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (6): ReLU() (7): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (8): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (9): ReLU() (10): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (11): BatchNorm2d(64, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (12): ReLU() ) (1): Sequential( (0): ZeroPad2d(padding=(1, 1, 1, 1), value=0.0) (1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), bias=False) (2): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (3): ReLU() (4): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (5): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (6): ReLU() (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (8): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (9): ReLU() (10): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (11): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (12): ReLU() (13): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (14): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (15): ReLU() (16): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (17): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (18): ReLU() ) (2): Sequential( (0): ZeroPad2d(padding=(1, 1, 1, 1), value=0.0) (1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), bias=False) (2): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (3): ReLU() (4): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (5): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (6): ReLU() (7): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (8): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (9): ReLU() (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (11): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (12): ReLU() (13): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (14): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (15): ReLU() (16): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (17): BatchNorm2d(256, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (18): ReLU() ) ) (deblocks): ModuleList( (0): Sequential( (0): ConvTranspose2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (2): ReLU() ) (1): Sequential( (0): ConvTranspose2d(128, 128, kernel_size=(2, 2), stride=(2, 2), bias=False) (1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (2): ReLU() ) (2): Sequential( (0): ConvTranspose2d(256, 128, kernel_size=(4, 4), stride=(4, 4), bias=False) (1): BatchNorm2d(128, eps=0.001, momentum=0.01, affine=True, track_running_stats=True) (2): ReLU() ) ) ) (dense_head): AnchorHeadSingle( (cls_loss_func): SigmoidFocalClassificationLoss() (reg_loss_func): WeightedSmoothL1Loss() (dir_loss_func): WeightedCrossEntropyLoss() (conv_cls): Conv2d(384, 18, kernel_size=(1, 1), stride=(1, 1)) (conv_box): Conv2d(384, 42, kernel_size=(1, 1), stride=(1, 1)) (conv_dir_cls): Conv2d(384, 12, kernel_size=(1, 1), stride=(1, 1)) ) (point_head): None (roi_head): None )