2021/6/16结果反馈与讨论记录
2021/6/16
Discrete Gradient效果验证
多步DG效果验证
- 实现方案:
- 将原来的单步DG(对所有维度仅扫描一次,对每一维obj排序,从大到小选出合适的维度,直到budget消耗完毕)改为多步DG(将原来的budget均分到每一step,每步按照原来单步DG的方案选择当前步最优维度,如果当前步当前维度在此前step已被更新过,则以更新后的该维作为起点计算obj);
- 将DG原来对整个模型所有层的扫描改为对一层(目前设置为第一层)的扫描,统一DG/STE/CDG的budget(\(\epsilon = 0.1\))。
- 实验结果:
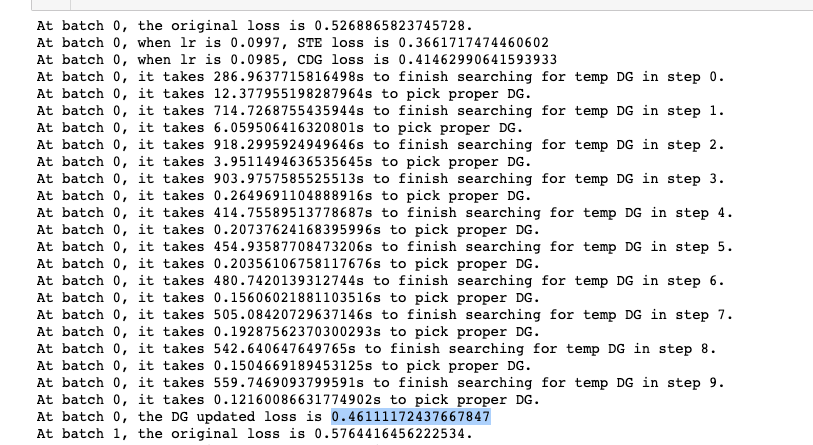
- 结果讨论:
- DG的效果似乎不足以作为STE的参考upperbound?
multistep-STE与variant-STE
multistep-STE
比较单步STE和同样预算的多步STE的性能。
- 实验设置:
- 在全精度MLP和binary MLP上分别进行以下实验:
- 单步STE和多步STE都在toy model上的第一层计算(仅更新该层的参数);
- 单步STE grad计算后进行normalization,在[1e-5, 1e-1]区间上以1e-5为间隔扫描最佳lr,取最佳loss;
- 多步STE通过SGD/SGDm/Adam优化器计算并更新,在每次更新参数后判断参数的增量\(\delta_w\)是否超出预算(0.1),超出则将\(\delta_w\) clip到0.1,直到达到更新次数上限。
- 多步STE在原始参数之上引入一定随机噪声,添加噪声的幅度及后续参数更新量不大于budget,观察在当前参数邻域内STE的结果。
- 实验结果:
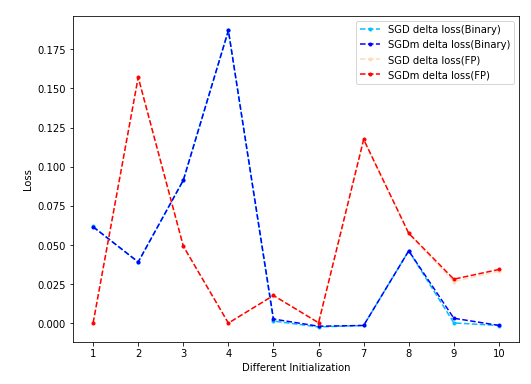
- 结果说明:
- 曲线为以单步STE loss归一化的单步STE loss与多步STE loss之差,该值越正则说明多步STE的效果越好于单步STE。红色系曲线为FP MLP上结果,蓝色系曲线为Binary MLP上结果。Adam性能波动较大,参数比较难调,对应曲线没有画出。
- SGD和SGDm的效果非常接近;
- 在预算范围内的参数空间里,存在优于STE更新结果的参数点(体现在噪声提供的随机性可以使多步的性能改善) -> STE在当前budget下不一定能指向最优的点(指loss下降最多的点)。
- 但是,这个现象并不是二值化采用STE造成的,FP MLP上的结果与Binary MLP上的结果非常类似,说明这是梯度下降共有的特性?
-
实验update:
将batch size从1024改为8192,将单步STE改成gradient clipping到[-0.5, 0.5]的variant STE(FP MLP因为不使用STE所以没有gradient clip): - 实验结果:
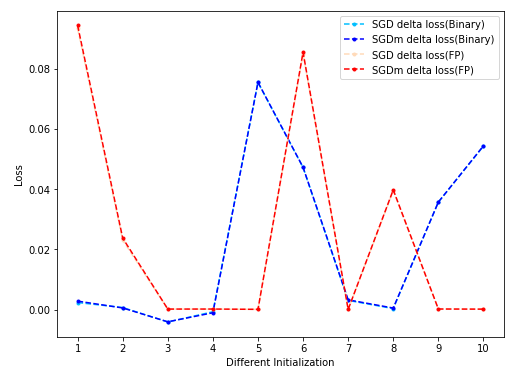
- 结果说明:
增大bs后实验结果的方差减小,但是FP MLP的变化趋势与此一致,难以说明是Variant STE的效果。
variant-STE
比较单步STE和同样预算的variant STE的性能。
- 实验设置:
- 单步STE和variant STE都在toy model上的第一层计算(仅更新该层的参数);
- 单步STE/vSTE对应input一致,均为bs=8192的输入。
- 实验结果:
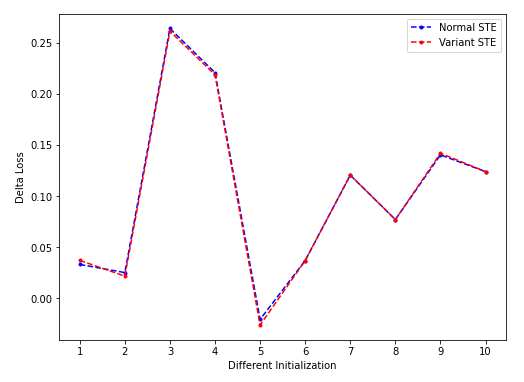
- 结果分析:
- vSTE和nSTE差距很小,怀疑是当前设置下很难区分出两种STE。
会议记录
- 陈老师
- 改一下threshold / 看一下STE variance&mean -> resnet
- DSQ:训练中缩小window - hardtanh-like? / reprodduce
- 低比特的挑战(2/3-1和3):
- √model capacity(模型空间里有没有想要的?)
- generalization(训练和测试,大网络有overfit的趋势->实际上并不是这样/大的网络越鲁棒)
- √optimization(能不能找到这个解?)
- 总比特数(每个unit的比特数/更宽)越多则越好优化
- 低比特更难优化(的原因×2):
- gradient有错,走不出local optimum;
- local optimum太多。
- 解决优化问题的路线:
- 本来:离散问题用离散方法 ADMM(STE checkpoint) (但是)遗传算法难以处理高维问题
- pretrain的问题 - local optimum
- 思路(2):
- 加扰动
- gradient vanishing - initialization(xavier etc.)
- cifar10/100加mixup - 缓解overfitting
- 思路(2):
- simulation不合理,不带硬件 -> (可能陈老师想做类似boolnet这种有硬件仿真的实验?
目前要做的事情:
- 陈老师验证试验收尾:
- 在ResNet上测STE:看variant STE和normal STE的区别,因为不复现(比较麻烦)DSQ schedule所以就在ResNet上静态测一下vSTE(变化窗口区间)?观察不同STE的实验效果,可以在initialized/pretrained model上各看一下;
- 在cifar10/100上跑带mix-up的pretrain/train from scratch,验证pretrain > tfs?
- 低比特工作相关:
- 调研SR主流思路,思考有没有低比特不适配的环节;
- 这周内跑起来baseline。