bnn_ops.py
2021/2/22
包括:
- BirealBinaryActivation(torch.autograd.Function)
- StraightThroughBinaryActivation(torch.autograd.Function)
- Binarize(torch.autograd.Function)
- BinaryConv2d(nn.Module)
- SkipConnectV2(nn.Module)
- BinaryConvBNReLU(nn.Module)
- ResNetDownSample(nn.Module)
- BinaryResNetBlock(nn.Module)
- BinaryVggBlock(nn.Module)
- NIN(nn.Module)
类。
New Methods
Class
BirealBinaryActivation
BiReal原文暂时没看,看完之后再考虑填坑。(似乎对应原文公式(3)?)
StraightThroughBinaryActivation
继承自torch.autograd.Function类。
含有方法:
forward:根据传入参数method选择对inputs的处理方法,sign或者float。backward:需要传入梯度,然后原样返回。
Binarize
继承自torch.autograd.Function类。
含有方法:
forward:传入参数包括ctx, x, fp_weight, binarize_cfgs。其中x表示activations,fp_weight表示全精度的weights,binarize_cfgs包括bi_w_scale(scaling factor related)和bi_act_method(activation量化方法)。Binarize activations。(有点问题,scale没改过来?)Binarize weights,包括不同的scale(scaling factor),scale == -1应该表示fp weights,通常不用,所以没写完?scale != -1的方式都需要对weights进行clamp(±1)截断,scale == 0应该就是正常BC的做法(没有scaling factor),scale == 1应该是XNOR-Net中的scaling factor,scale == 2 or scale == 3应该对应的是BiReal中的scaling factor计算方法。最后把old_x, fp_weight, bi_weight, mean_val, scale存到ctx里。backward:传入参数包括ctx, g_x, g_bi_weight。这里似乎已经算出了gradient of x(g_x),只对梯度进行一个clip?(逐元素比较,绝对值大于门槛的就clip成0)奇怪的是gradient clip的门槛也要乘scaling factor?
BinaryConv2d
继承自torch.nn.Module类。
含有方法:
__init__:初始化,调用BinaryConv2d的父类的初始化方法,用torch.zeros开个全精度参数的数组,在(0,0.05)上normal_初始化,再初始化bias。forward:写一个binarize_cfgs字典出来,binarize activations&weights,然后调用torch.nn.functional.conv2d用binary weights对binary activations做卷积。
SkipConnectV2
继承自nn.Module类。
根据C_in、C_out、stride确定并执行操作,目的是对齐通道。
含有方法:
__init__:self.conv_ds是什么的bool变量?似乎是支持任意channel的?C和C_out不用对齐?对输入的activations做group conv?conv_ds表示对于downsample层,是用一个conv层来表示downsample,还是直接过一个avgpool2d然后在channel维度上复制一遍。判断流程:先判断stride是不是2:if self.conv_ds->op1=nn.AvgPool2d(2),op2=XNORGroupConv;else判断C_in和C_out是不是相等或2倍关系,(这边写得感觉有点烂…)如果是的话就取average_pool(1个或2个,看expansion);stride == 1就op=Identity()。forward:非静态方法。按照上面反着来self.stride == 1则op=Identity()self.stride == 2self.conv_ds则op1=nn.AvgPool2d(2),op2=XNORGroupConvnot self.conv_dsself.expansion == 2则op1=op2=nn.AvgPool2d(2),结果concateself.expansion == 1则op=nn.AvgPool2d(2)
BinaryConvBNReLU
基本的binary conv bn relu block。
"""
xnor-conv-bn-relu should be the basic building block and contain all the possiible ops
It should contain the args:
- ch disalignment arrangement
- shortcut_op_type(simple parameter-free shorcut)
- reduction_op_type(avgpool2d / factorized reduce)
- layer-order
- relu
- group
- dilation
- binary_conv_cfgs
- bi_w_scale
- bi_act_method
- bias(zero-mean)
"""
含有方法:
__init__:正常初始化,要注意的是shortcut只有在特定的情况下(对应Line382-Line390)才能用。支持"conv_bn_relu", "bn_conv_relu"两种layer order。目前似乎只支持self.shortcut_op_type == "simple"。self.bn的初始化要考虑layer order(对应不同的channel数目)。根据stride初始化self.convs。根据self.shortcut_op_type初始化self.shortcut。forward:在最开始或后面过BN,最后过relu(不重要)。if self.stride == 2 and self.reduction_op_type == "factorized"下面,"factorized"指什么?
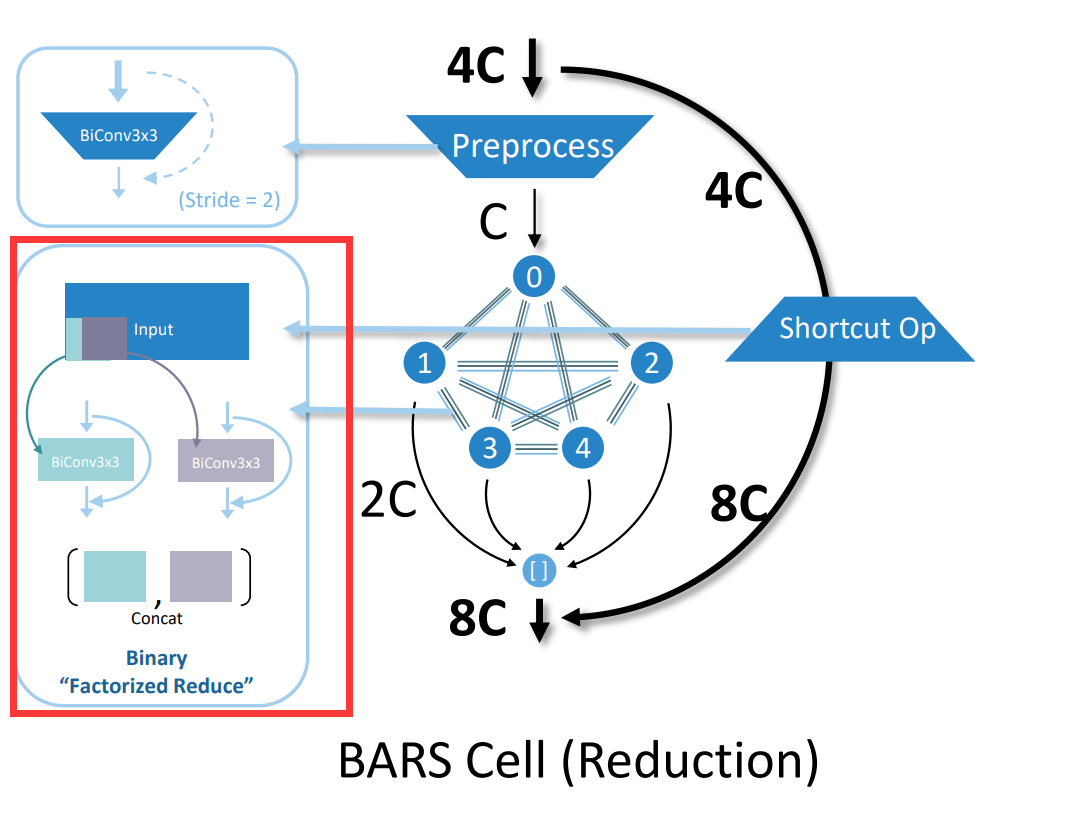
x.size(2)是什么?channel out?
A:推测是w or h,这里应该假定了w==h。
pad方式也不是很懂。
A:其实这里已经规定了stride=2了,所以就算padding最多也只padding1…然后pad第二个传入参数是指定pad的位置((1,0,1,0)表示在上方左方pad) 这里我认为padded x经过factorized reduction之后产生的activations w×h是一样的,虽然内心非常不安(主要是op后的尺寸能否对应)。 两个conv后的activations能不能直接和同一个shortcut绑在一起的疑惑暂时消除了,因为与其担心这个不如担心对pad后的x进行卷积产生的影响了。(无关紧要)
shortcut是直接加在一起?不是concate?
A:shortcut的前后tensor shape是不变的,所以shortcut是tensor按元素相加。需要注意的是加shortcut的时候是让padded x过shortcut再concate,所以不会有w*h上对应的问题。
ResNetDownSample
继承自nn.Module。看样子是ResNet中的降采样层。 含有方法:
__init__:用了kernel_size=1, stride=2的nn.AvgPool2d,也就是隔一个采一个值,有点粗暴。forward:有点奇怪,最后是x与x.mul(0)按channel concatenate在一起(不该是原样concatenate吗?)
BinaryResNetBlock
继承自nn.Module。看样子是binary resnet的building block…嗯。
含有方法:
__init__:正常的初始化,后面跟了op_1和op_2的初始化,两个op都是BinaryConvBNReLU,但是第二个op保持了输入输出维度相同(都是C_out)。从三种方式["conv", "avgpool", "binary_conv"]中选一个downsample的方法。选择的流程是:- 如果
downsample == "conv":- 如果
stride == 1那么self.skip_op = Identity() - 否则
self.skip_op = ConvBNReLU()
- 如果
- 如果
downsample == "avgpool":- 如果
stride == 1那么self.skip_op = Identity() - 否则
self.skip_op = ResNetDownSample()
- 如果
- 如果
downsample == "binary_conv":- 如果
stride == 1那么self.skip_op = Identity() - 否则
self.skip_op = BinaryConvBNReLU()
- 如果
- 如果
forward:有丶特色。前传的时候,先对input进行op_1,把结果和skip_op(input)加在一起变成中间结果inner,然后对inner进行op_2,再加上inner作为输出。
注册方法
- Line570-595:
xnor_resnet_block - Line597-620:
bireal_resnet_block - Line683-694:
xnor_vgg_block - Line696-707:
bireal_vgg_block - Line712-733:
xnor_conv_3x3_noskip - Line735-740:
xnor_conv_1x1_noskip - Line745-771:
xnor_conv_3x3_cond_skip_v0 - Line774-779:
xnor_conv_3x3_cond_skip - Line782-787:
xnor_skip_connect - Line791-811:
xnor_conv_3x3_skip_connect - Line903:
xnor_nin
BinaryVggBlock
继承自nn.Module。building block of binary vgg.
含有方法:
__init__:注意Line660 vgg block没有shortcut。判断downsample是"avgpool"(目前应该只支持这个,或者vgg只对应这个),然后根据stride确定实际downsample的操作。forward:先op再pool,正常。
NIN
继承自nn.Module。应该是一个弃用了的方法,因为里面到处都是老的XNORConvBNReLU。
含有方法:
__init__:注册了好多op。最后用一个self.modules()保存了这些op(有点像ModuleList) Line 872附近的代码有点参考价值(方法层面):
for m in self.modules():
if isinstance(m, (nn.BatchNorm2d, nn.BatchNorm1d)):
if hasattr(m.weight, "data"):
m.weight.data.zero_().add_(1.0)
这里的self.modules保存了之前的所有模块(具体的"模块"可以参考这篇博客…虽然又多了个self.children()有点更难李姐)。下面是判断self.modules中的元素是不是nn.BatchNorm2d和nn.BatchNorm1d中的一种,然后把它的权重先变成0再变成1,函数加了下划线的属于内建函数,将要改变原来的值,没有加下划线的并不会改变原来的数据,引用时需要另外赋值给其他变量。
forward:前传的时候对BN的data有一个clamp_操作,夹紧到0.01以内。最后有个x.squeeze()把为1的维度去掉。
问题集合
1. forward和backward中出现的ctx是什么意思?
A1:解决了,在这里给了详细的区分。
2. 与Question1相关联,为什么在StraightThroughBinaryActivation里面需要在forward里把inputs和method存起来,backward里拿出来又不用?
A2:可以用,没用到。但是不是存进去必须要取出来呢?
3. apply的用法?是torch专门的方法吗?
A3:确实是torch的方法。apply是torch.nn.functional的用法,因为我们写class的时候是继承了torch.nn.functional这个类的,我们相当于是重写了forward和backward函数;所以调用这个函数的时候应该用apply作为标准调用方式,只调用xxx.forward的话不确定会不会调用对应的backward
4. Line120以下,对梯度clip的时候门槛也要乘scaling factor吗?
A4: 按照正确定义应该是需要给threshold乘上scaling factor的。
5. Line217为什么full precision weights初始化的时候不用.cuda(),bias的初始化用?
A5:这个可能纯粹是写的时候没注意…后面会用model.to(device)把所有的module的attribute都搬到gpu上
6. Line259XNORGroupConv在哪?请见其他class SkipConnectV2的问题。
A6:没有改过来的历史遗留问题。XNORGroupConv貌似是之前的接口,可以看作和现在BinaryConv2d相对应。class SkipConnectV2中的问题已在之前回答过了。
7. BinaryConvBNReLU的问题。
A7:因为shortcut的前后tensor shape是不变的,所以shortcut是tensor按元素相加。
ResNetDownSample的concatenat需要确认一下。BinaryVggBlock注释似乎有问题。而且默认的downsample是conv,但是后面有assert downsample == "avgpool"有些矛盾。register_primitive的用法?
To-Do
nn.Module是个重要的类…需要仔细研究。nn.Parameter也很重要。。ModuleList需要研究