2026 Working Progress
By 2026/1/7
- 继续调基于本地LLM的MCP Client(Flag回收)
- 优化推理效率方面的尝试
- 摸了下
vllm框架,期望通过该框架优化推理开销(降低推理延时+降低显存开销),但是没有成功:vllm框架目前对VLA的支持不是很好,参考vllm官方vla示例把RoboBrain2.0缝进去;官方示例使用的对话模板是qwen2.5-vl的,需要替换为修改后含工具调用的jinja模板。vllm主要面向的是高并发场景下的大模型推理服务,它的主要目的是在生产环境中同时服务多个用户,主要的技术贡献在于显存管理,用PageAttention等技术减少碎片化显存(在这一意义上,它是设计来替代Pytorch显存管理方案的);尽管vllm支持部署量化后的LLM,留有相关的量化接口,但是它并没有集成量化模块,用户须在其他框架下进行模型量化,再将模型迁移到vllm中。自己量化RoboBrain2.0不太可行,因为需要利用该模型的训练数据做量化参数校正,已在RoboBrain2.0官方repo提了issue,希望开放量化后的模型,暂无回复。- 1/6 update: 在HF上发现了
RoboBrain2.0的量化版本,分别是RoboBrain2.0-7B-W8A16与RoboBrain2.0-7B-FP8。
- 1/6 update: 在HF上发现了
- 综上,
vllm的设计初衷不是单模型推理优化/加速,没能实现利用vllm优化推理。
- 利用上述
RoboBrain2.0官方提供的量化后checkpoint做测试:- 使用RoboBrain2.0-7B-W8A16版本,模型加载后显存占用由16GB+变化至~10GB,推理速度明显降低,由~10s变为~1min,且推理时显存增量明显(增量由~300M变为~3000M),推理质量未见退化;
- 使用RoboBrain2.0-7B-FP8版本,模型加载后显存占用由16GB+变化至~10GB,推理速度也有明显下降,由 ~10s变为~20s,但显存无明显增长;
- 原因似乎是,
transformer的默认pipeline会把W8反量化回W16,造成额外推理时间和显存开销;量化后模型应搭配特定的优化核使用。
- 摸了下
- 技术路线备份方面的尝试
- 评估了不同服务框架下LLM / VLM调用工具(tools)的方法,结论是对话模板均需手动编写、消息填装与回复解析均需手动实现、多轮交互与工具调用均需手动编排:
- 参考
vllm提供的官方示例chat_with_tools,该框架下LLM调用工具的局限有:- 工具的声明和调用方法没有按照MCP标准,需要手工进行message填装和工具声明;
vllm的LLM chat pipeline对应的对话模板完全依赖于对应LLM官方提供的模板,无通用模板。遇到RoboBrain2.0这样的样例,仍需要手工编写含有工具调用的对话模板;vllm中LLM chat pipeline不含流控制,在多轮工具调用的场景下,依赖对话模板汇总对话上下文历史 + 手工编写规则判断工具调用循环是否结束。
- 通过
openai api实现与本地端口serve的LLM(通过vllm实现)进行对话,发现该方案也符合上述结论描述(需要自定义模板、交互前后处理需要手工写、无任务/工具调用编排)。 - 尝试通过
ollama启动本地LLM服务,它的产品定位类似于huggingface(但仅支持ollama官方提供的部分LLM)的model hub + (无模型/推理优化)vllm。发现ollama对本地自定义LLM的支持比较差,没找到现成的例子(似乎可以serveGGUF格式的HF模型),轻量化的设计让它更适合新手快速上手,似乎不太适合基于此进行拓展开发。
- 参考
- 对于多轮交互与工具调用的编排,或许可以尝试
LangChain&LangGraph。
- 评估了不同服务框架下LLM / VLM调用工具(tools)的方法,结论是对话模板均需手动编写、消息填装与回复解析均需手动实现、多轮交互与工具调用均需手动编排:
- 优化推理效率方面的尝试
- 尝试将本地Robobrain2.0 MCP client接入
ros-mcp-server
By 2026/1/21
- 尝试使用
OpenManusOpenManus是啥:Manus的开源替代,定位是LLM-Agent框架,功能特点有:- 具备
Multi-Agent分工合作能力,可类比AutoGen(官方示例脚本被标记为"unstable"且长达8月未维护); - 可以拆解复杂任务目标、调用真实工具、并在任务失败后重新多次尝试;(可以讲讲搜索的例子)
- 给了多个真实工具(如浏览器搜索、沙盒程序运行)的调用方法;
- 具备
- 优点:
- 现成的LLM Agent调用工具(浏览器搜索)示例,可以参考工具接口写法 + 编排控制;
- 开源(与其他开源多智能体框架相比,暂未看到明显优势)
- 缺点:
- 没有使用文档!没有架构示意图!没有文章支撑! 架构、组织形式等需要自己摸索;
- 项目维护频率低,几乎一月一更或者一月两三更;
有点在25年4月搞个大新闻就跑路的意思
- 与其他多智能体框架的对比(参考自这篇随送)
- 与
AutoGPT相比,AutoGPT更像是实验性质的初步尝试,"仅支持单Agent,靠prompt驱动一切,易发散、难维护",而OpenManus更像是工程实用导向的框架; - 与
LangChain相比,LangChain侧重于提供多种工具支持,而OpenManus是"尝试构建完整执行闭环"(理解为类似LangGraph的流程编排); - 与
CrewAI/MetaGPT相比,前两者"更适合写作、分析、协作型任务",OpenManus"关注任务是否真正被完成"。
- 与
OpenManus的架构(参考自这篇随送与这篇回答)- 整体架构:
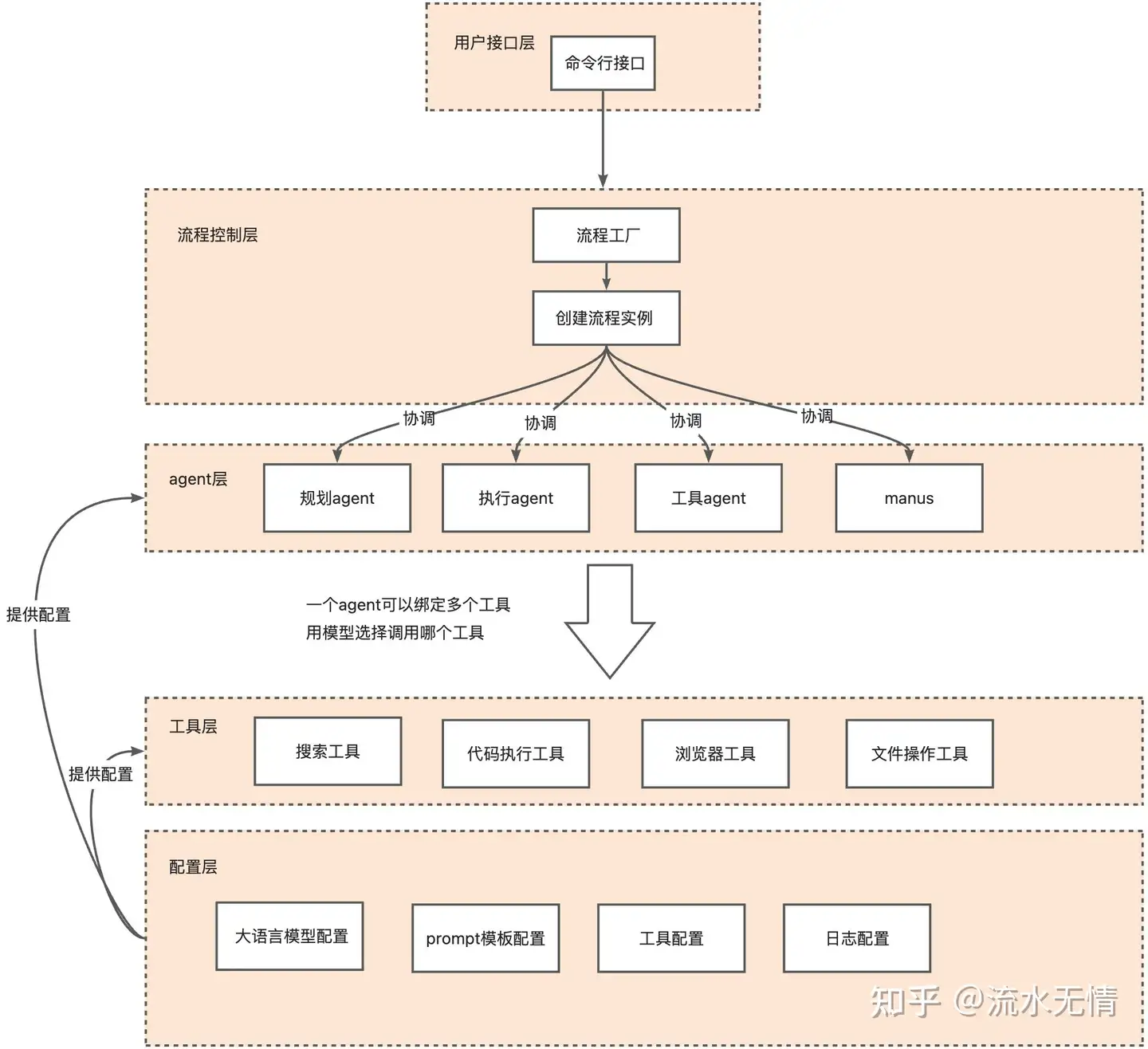
- 由三个基本模块构成:
Agent:继承自 BaseAgent 并可以执行任务的类;Tools:可用于完成任务的工具功能;LLM Integration:和LLM的通信层,兼容多种LLM格式/服务提供商(openai/claude/ollama/jiekouai…)
Agent系统: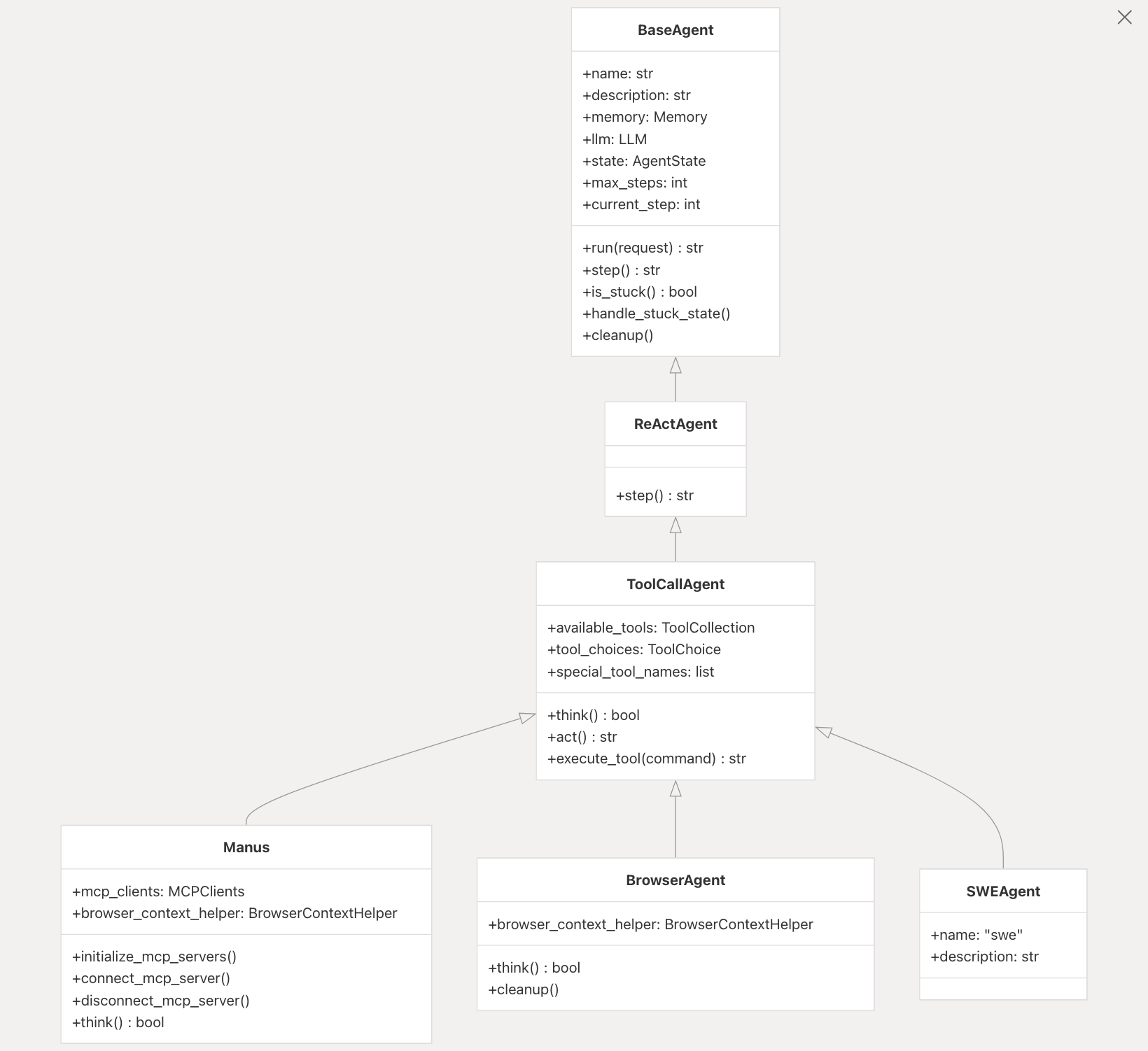
- 由以下
Agent构成:BaseAgent:所有Agent的基类,负责管理状态和记忆。ReActAgent:实现推理和行动的循环。ToolCallAgent:处理工具调用,根据LLM决策执行工具。Manus:多功能通用Agent,标准模式下使用的主代理。BrowserAgent:专门用于浏览器交互的Agent。
OpenManus的工作流程: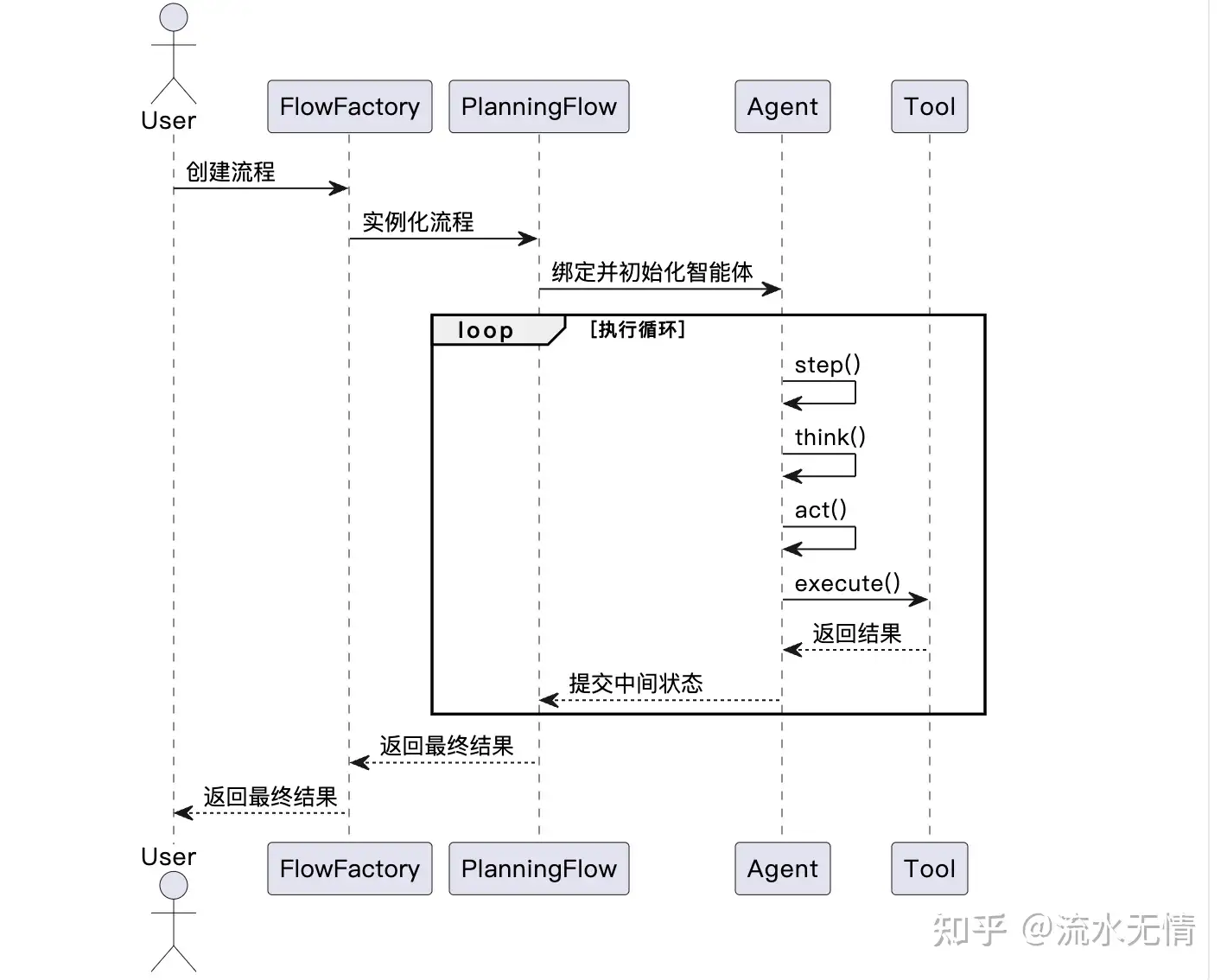
- Agent向LLM询问进行思考(决定做什么);
- LLM建议工具调用执行;
- Agent执行工具并观察结果;
- 循环重复,直到任务完成或达到最大步数;
- 整体架构:
- 需要解决以下问题才能使用
OpenManus:- 修改
requirements.txt中的crawl4ai版本避免依赖冲突,crawl4ai~=0.7.2; - 手动
pip安装daytona、structlog等requirements.txt中缺失的依赖; - 在官方示例
./config/config.toml文件末尾添加以下字段:[daytona] daytona_api_key = "your_api_key" daytona_server_url = "https://app.daytona.io/api" daytona_target = "cn"
- 修改
- 尝试若干LLM serve方法: ❌
OpenAI - API模式,需要本地代理+账号token余额,尝试更换国内二手服务商,发现接口不通畅; ✔️ollama本地serve方法,在本地端口启动llama3.2服务,利用OpenManus访问; - 尝试使用
OpenManus运行官方给的样例:- 使用
ollama在本地serve模型,发现:- 尝试
Gemma3:12b模型,发现Gemma3系列不支持工具调用,无法与OpenManus搭配使用; llama3.2模型在使用中发现两个问题:①llama3.2优先访问英文页面(模型直接输出的url就是外网连接),且幻觉严重(生成了很多不存在的url,而且是根据记忆直接去某些特定的页面,而不是打开google等搜索引擎),无法从网络页面获取有效信息;②在模型的think阶段,生成的LLM response会产生大量重复回答(同一个工具调用命令,重复40次,区别仅在于id不同,而id应该是LLM服务框架自动生成的),检查OpenManus传递的信息,未发现异常(输入内容正常,且未发现重复调用现象),问题可能出在ollama框架或llama3.2模型本身,因涉及跨框架联调,暂时未深入研究。未完成一次示例。ollama的官方hub中给出的例子比Gemma3更老 / 规模太大,没有试其他的模型;
- 尝试
- 使用
Deepseek API(DeepseekV3.2-chat),发现OpenManus的成功率很有限,表现为:- LLM对页面的控制很不稳定,经常出现文字输入失败等问题,无法正常使用网络页面搜索功能(这或许是LLM本身能力的问题);具体而言,LLM可以和网页有限交互,比如可以点击某些按钮跳转页面,但是需要在输入框输入某些文字进行查询的时候经常出错;
- 国内的互联网生态很烂(壁垒很高,封闭性太强),在查询的时候经常要登录验证,导致LLM陷入死循环,或许在外网
OpenManus的联网搜索表现会更好; - 在浏览器搜索失败以后,LLM通常会根据自己的资料库生成文件:
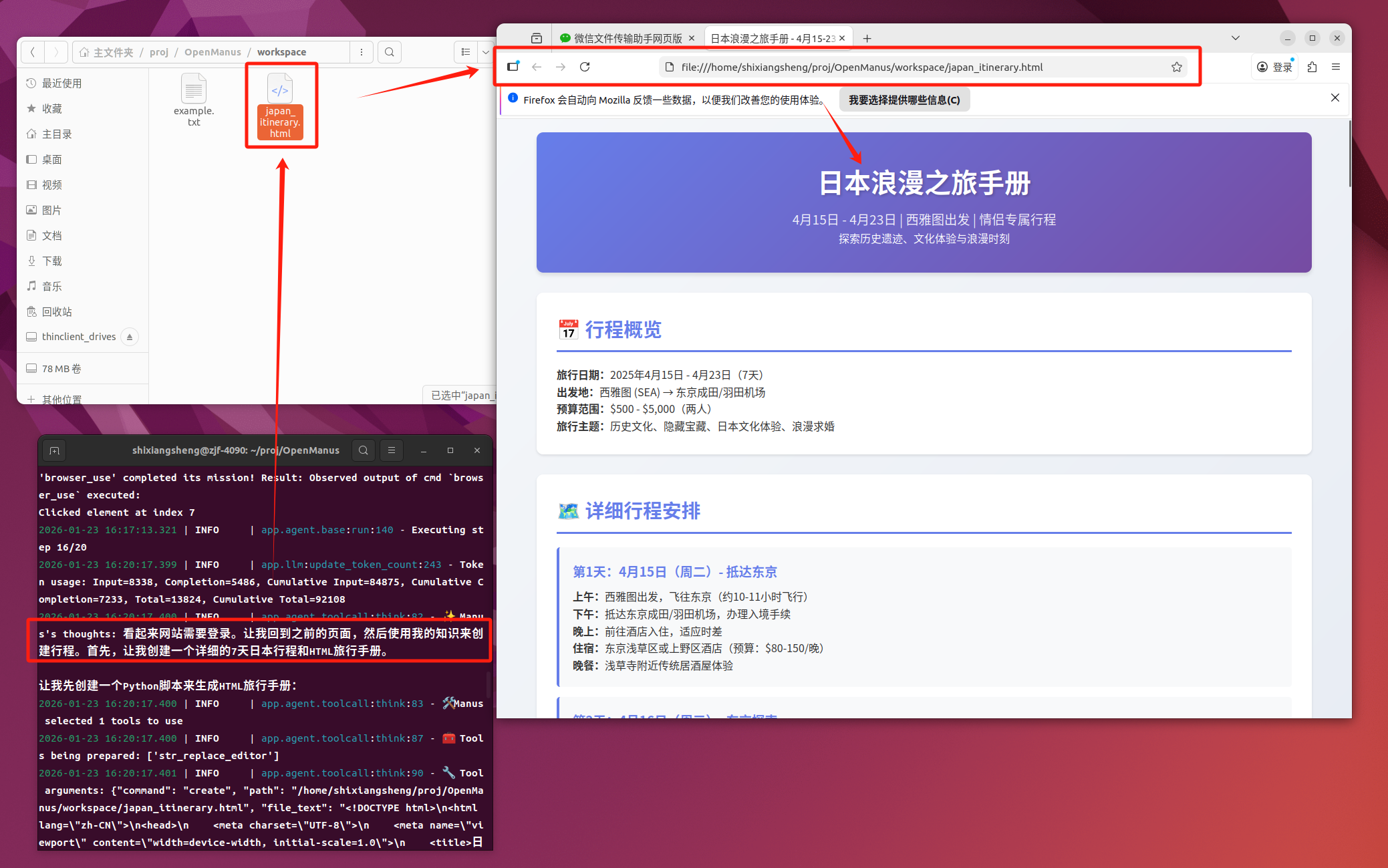
OpenManus的本地文件创建与代码执行表现不错,可以正常在本地新建文件,并执行Python脚本。
- 使用
- 对比
Manus与OpenManus,有以下待核实内容:- []
OpenManus是否有Manus的规划–执行–验证三层架构(具体而言,OpenManus是否具有复杂任务动态拆解为子任务 DAG、工具选择与资源分配、异常路径预判与回退策略等功能,是否具有任务完成校验机制); - []
OpenManus是否有Manus的多智能体协作机制,OpenManus确实有独立定义的、负责不同功能的Agent,但它们是否能协作、是否在独立沙箱中运行并隔离需要进一步核实; - []
OpenManus和Manus在执行同一任务时,有何差异表现:- 是否有显式的任务拆解、有无中间文件(如
todo.md)生成; - 是否有
Agent协作,还是简单的调用关系;Agent的工作环境是否独立,是在沙箱中独立运行,还是共享系统环境; - 是否存在核查环节;
- 是否有显式的任务拆解、有无中间文件(如
- []
OpenManus是否在各个Agent中都接入LLM,接入的LLM是否有不同(不同模型类型、不同system message); - []
OpenManus是否有并行任务执行能力? - 【TODO】如果参考
OpenManus,如何在它的基础上改进?
- []
OpenManus记忆系统的实现:- 总结:
OpenManus的记忆仅限于LLM与用户、LLM与工具的文本交互信息,是一种非常朴素的"记忆系统"。 - 在
BaseAgent(所有Agent的基类,继承关系是BaseAgent->ReActAgent->ToolCallAgent-><specific_Agent>)中实现类内属性memory,它对应了app.schema中的Memory类; Memory类是一个简单的对Python List维护的类,核心是一个messages(Python list),负责记录传入的message变量;此外,该类提供了若干辅助函数,包括在messages中新增、删除、清空历史message;message变量是一个自定义的Message类,里面记录了每次交互的角色、交互的文本内容、工具调用等信息,此外,还提供了一个转写为Python dict的方法,可以将Message实例改写为字典格式,并进一步构成prompt。注意:单次的交互内容(一次用户query、一次LLM回复、一次tool call等)记为一条message。- 以下是记忆系统的一个示例:
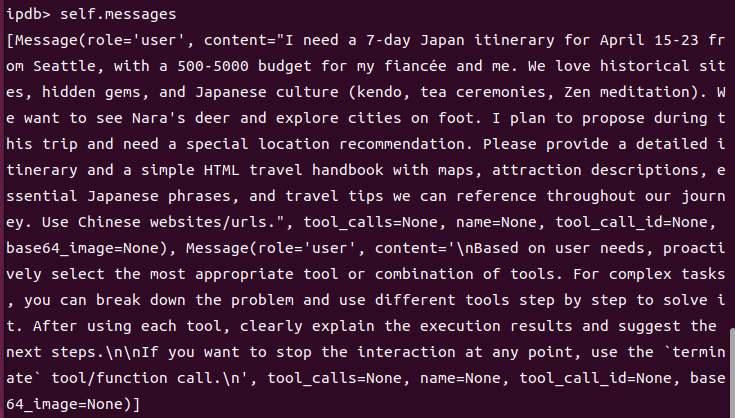
- 总结:
-
OpenManus的工具调用: -
OpenManus的编排能力: -
OpenManus的验证方案: OpenManus的智能体定义:OpenManus中各个Agent的继承关系是BaseAgent->ReActAgent->ToolCallAgent-><specific_Agent>,所有的Agent都基于BaseAgent,然后统一依次被ReActAgent、ToolCallAgent继承,最后再继承为实现特定功能的<specific_Agent>;- 在
app/prompt目录下含有py文件格式的prompt文件,包括system prompt与next step prompt(追加在生成prompt的最后,提示下一步该做的事情);各个<specific_Agent>在初始化时会从对应的文件中引入prompt字段; BaseAgent是所有Agent的基类;类内包含Memory与LLM的初始化,还有更新memory、管理状态、死循环检测等功能;- 和LLM交互的
content中的角色有四类,分别是system、user、assistant、tool; - 基本的循环是,在最大执行步骤以内,反复调用子类
step函数,期间处理可能的死循环,直到达到迭代上限/agent判断任务已完成。无显式子任务分解(DAG拆分)、无显式任务完成情况校验,完全依赖大模型能力。
- 和LLM交互的
ReActAgentoverride了BaseAgent的step方法,在单次step中加入了think抽象类的调用,在判断当前step是否需要执行act;ToolCallAgent中对think、act等抽象类进行了实现;think方法对用户输入进行一定处理(在self.message中追加next_step_prompt的内容),调用self.llm.ask_tool,将可用tool与self.messages(记忆系统中所有的message)等信息打包装填成与LLM直接交互的prompt,根据LLM的回复判断当前step是否执行act方法;act方法依次执行self.tool_calls(记录LLM调用的工具与参数的list)中的工具调用,并将工具调用结果依次写到self.messages里;
OpenManus的多智能体协作:
## By 2026/2/6
- 调研
AgentScope:- TL;DR:
AgentScope可视为OpenManus的上位替代,在框架完成度、可扩展性、开发者支持(工具+文档)、社区生态等方面均显著优于OpenManus;AgentScope有较多可参考的设计与实现,例如多模态模型支持与跨API兼容、并行工具调用、实时人工介入、长短时记忆系统设计、分组工具管理、复杂任务编排、专家系统集成等,可尝试在RAI的基础上增加这些模块;AgentScope的不足:没有看到执行验证相关的描述;
AgentScope定位:AgentScope 1.0是阿里开源的LLM智能体框架,以ReAct范式(推理-行动闭环)为基础,提供"消息、模型、工具、记忆"等灵活搭配的模块,同时原生支持多模态交互、并行工具调用、实时人工干预等工业级需求,适配需要复杂任务编排、多智能体协作的场景。AgentScopeOverview:
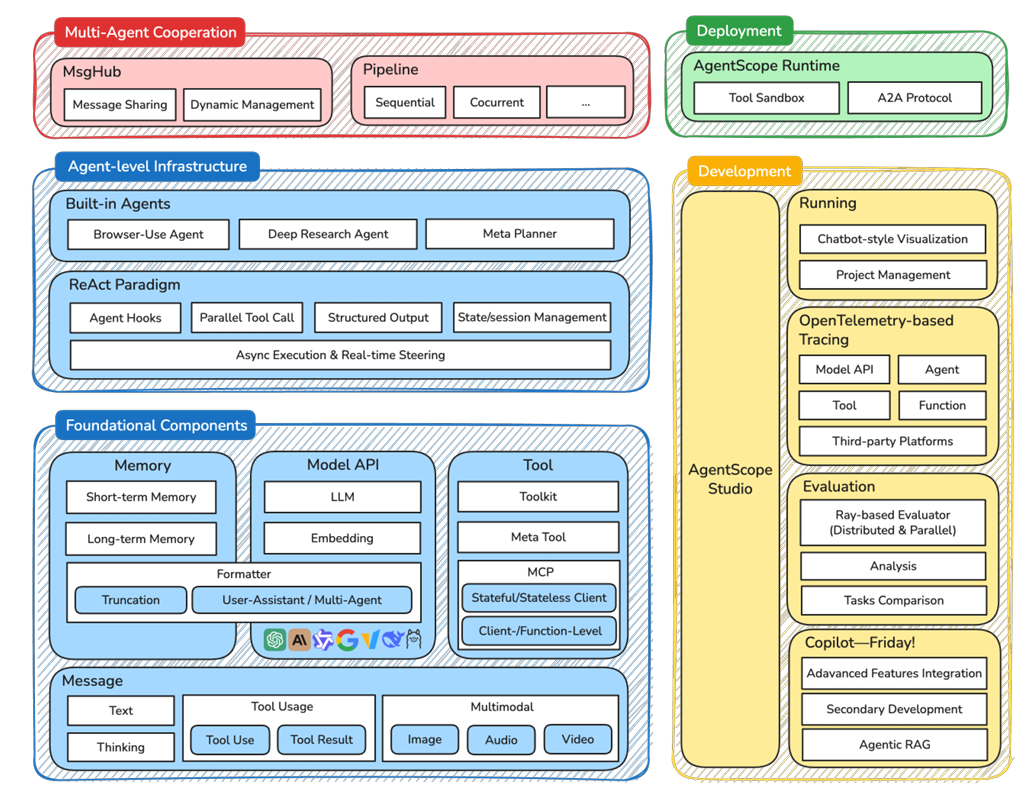
AgentScope架构可以分为若干层,包括核心构建模块、智能体基础设施、多智能体协作、部署、开发模块;- 核心构建层(foundational components):包括四个基本模块,消息(message)、模型(model)、记忆(memory)、工具(tool);
- 智能体基础设施层(agent-level infrastructure):以
ReAct范式为基本的智能体架构(agent architecture),支持并行工具调用、异步工具执行、实时人工介入;
AgentScope的核心建构层(与目前看过的智能体框架划分基本一致):- 消息
- 基本的数据单元,作用是在智能体之间进行信息交互、在用户界面进行信息显示、用于记忆系统存储;
- 包含若干字段:Name、Role、Content、Metadata、timestamp、id;其中,
AS进一步将Content中的内容封装成了ContentBlock,如textblocks、imageblocks、audioblocks、videoblocks等,以一种更加结构化的方式管理信息;
- 模型
- 统一的LLM/VLM接入接口,兼容OpenAI、DashScope、Anthropic、Gemini、Ollama、vLLM等主流模型 / 服务框架,支持流式输出、工具调用、视觉输入;
- 兼容处理不同模型的API格式差异,对齐模型输入输出,无需手动适配;
- 提供tracking和hook函数,实现细粒度的模型token消耗监控与预算控制;
- 记忆
- 负责上下文与长期知识管理,包括对话历史、执行轨迹、跨对话数据,分为短时记忆(Short-term Memory)、长时记忆(Long-term Memory),支持外部记忆库(如mem0)接入;
- 短时记忆:存储对话历史、工具执行轨迹,支撑任务多步骤闭环;
- 长时记忆:支持语义检索、跨会话知识复用,提供开发者控制和智能体自主控制双模式;
- 工具
- 工具注册、调用、管理的接口;
- 支持本地函数、远程MCP服务(模型上下文协议)注册;
- 支持工具分组管理(Group-Wise Tool Management),智能体可动态激活 / 关闭工具集,减少具身任务的工具选择冗余;(适配我们设计的场景中的任务切换,可将技能按照应用场景进行分别封装,例如 "机械臂抓取组""导航组")
- 原生支持并行工具调用、异步执行,智能体可生成并行工具调用指令,并通过
asyncio.gather分发与并行执行;(或可支持我们设想的多任务并行执行场景) - 工具中断容错:执行中被中断时保留部分结果,方便任务的故障重试;
- 消息
AgentScope的智能体基础设施层
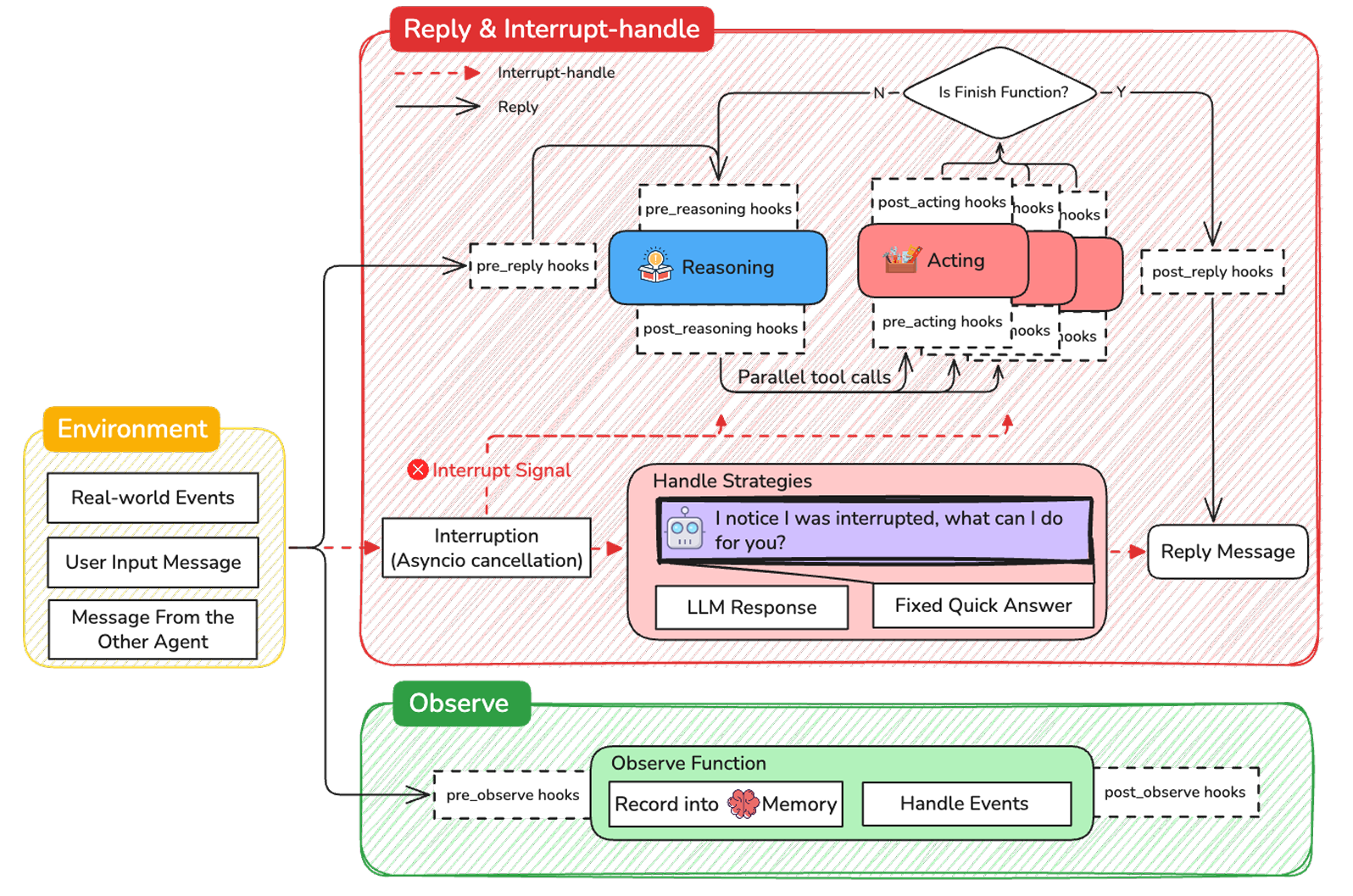
AS框架下智能体的任务执行流程中有三个关键函数:- Reply:智能体的主要主动响应机制,通过执行推理、采取行动、生成结论性的回复来响应用户指令;
- Obeserve:智能体处理包括环境变化、广播信息的函数,以此来更新内部状态或记忆;
- Handle Interrupt:支持"人-机"互动,触发后允许智能体暂时中断执行中的任务并按照用户指令调整行为;
AS框架以ReAct范式为核心,扩展了若干能力:- 实时干预(Real-time Steering):支持用户在任务执行中中断智能体,智能体可保留当前状态并根据干预调整策略;
- 动态工具配置(Dynamic Tool Provisioning):智能体可自主切换工具组,适配任务的多阶段需求;
- 状态持久化与钩子函数:支持智能体状态(记忆、工具配置)保存与恢复,钩子函数可无侵入式扩展功能(如添加动作日志记录、数据校验);
- 支持多智能体协作,将专业智能体封装为工具(Agent-as-a-Tool),由主智能体调用(invoke specialized agents as tools to handle particular subtasks or domains of expertise);
AS提供了若干智能体demo:- Deep Research Agent:擅长多源信息检索与报告生成,可借鉴的地方在于 任务分解-子任务执行-反思优化 的闭环;
- Browser-use Agent:支持浏览器自动化操作,借鉴之处在于 视觉+文本多模态推理、长页面分块处理;
- Meta Planner:复杂任务规划与多智能体编排,可借鉴 分层任务分解(hierarchical task decomposition)-动态worker智能体创建-进度跟踪 的流程。
AgentScope还提供了丰富的开发环境支持:- 框架提供了一套工程化工具,支持智能体开发中的调试与评估;
- Evaluation(评估模块):支持单进程调试(Sequential Evaluator)和分布式评估(RayEvaluator),可自定义评估指标;
- Studio(可视化平台):提供聊天式交互界面、执行轨迹追踪、评估结果可视化,可实时查看推理过程、工具调用记录;
- Runtime(运行时环境):支持
Google A2A等多智能体通信协议,一键部署为FastAPI服务;提供隔离的工具执行环境,支持文件系统、浏览器、训练环境等专项沙箱;
- TL;DR:
- 阅读
RAI代码;